Using Hightouch for Reverse ETL With Databricks
Driving analytics back into the business
by Prasad Kona and Luke Kline
This is a collaborative post from Databricks and Hightouch. We thank Luke Kline, Product Evangelist at Hightouch, for his contributions.
You finished setting up your data lakehouse on Databricks. You have a centralized location where you can perform all forms of analytics, machine learning, artificial intelligence, and business intelligence.
Your data engineers are excited because they can finally start tackling all of your streaming use cases, and your data scientists can start focusing on your data science and machine learning use cases. Your data engineers are able to leverage this information to build relevant data models to power your business, and your data analysts are thrilled because they now have the ability to run quick ad-hoc queries at a moment’s notice.
As data resides in Databricks, Hightouch enables Reverse ETL, where the data can be moved into operational systems like advertising, marketing, success, and other business platforms to extend the value of analytics on the lakehouse. Hightouch can help open up the value of all these analytics to your business teams that need access to the unique customer data that exists within the lakehouse:
Moving this data out of Databricks is now really easy. You don’t have to build a custom data pipeline for potentially dozens of destinations (ads, marketing, CRM, customer success, ERP, etc). Hightouch provides a platform and programmatic approach to ensure your data is in the proper format to be ingested.
The maintenance of these pipelines is now equally as efficient because Hightouch takes care of managing constantly changing APIs of upstream or downstream systems. On top of this, Hightouch provides easy ways to manage data quality with live debugging and version control.
You no longer have to maintain labor-intensive pipelines in-house. Hightouch on Databricks is a great solution for Reverse ETL to get data into the hands of business users, where it can be actioned and bring immediate impact to your business.
The solution: Reverse ETL
Reverse ETL is the process of moving your transformed data back into the tools that run business processes. Usually, destinations consist of SaaS tools used for growth, marketing, sales, and support. Instead of using dashboards to make decisions, Reverse ETL shifts the focus to putting your datasets to work through Operational Analytics – turning insights into action automatically.
If your best data only exists in Databricks, your business teams are relying on generic information to power their day-to-day activities. This could be something as simple as supplying your sales team with updated product usage for new leads, sharing a new audience with your marketing team for ad retargeting, helping your customer success team identify, which support tickets should be prioritized or notifying members of your team when a specific event takes place in your app.
You can probably think of several examples of data that would be better served elsewhere within your business. There are many use cases that Hightouch can solve with Reverse ETL, and you will soon see why tech-first companies like Nauto are using Hightouch to supercharge Databricks.
How to get started syncing data with Hightouch
Note: Hightouch never stores your data, so you don’t have to worry about compliance.
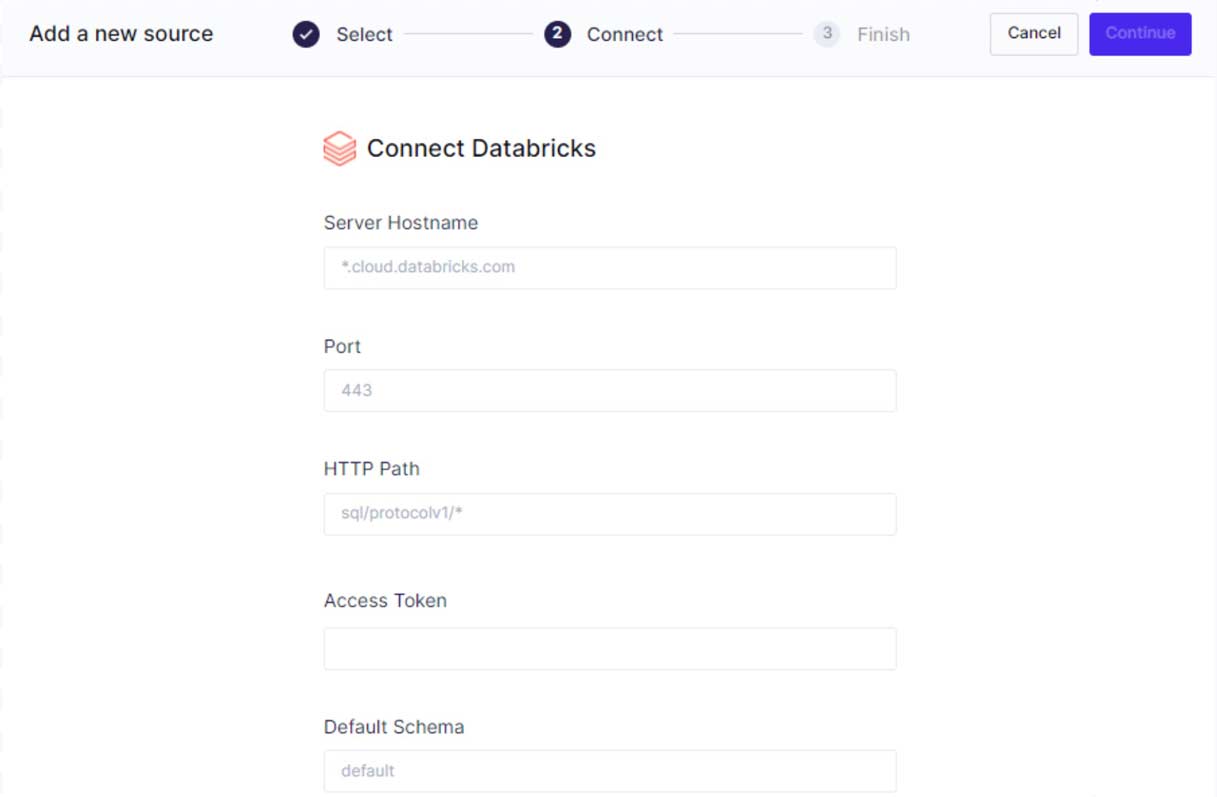
Step 1: Connect Hightouch to Databricks.
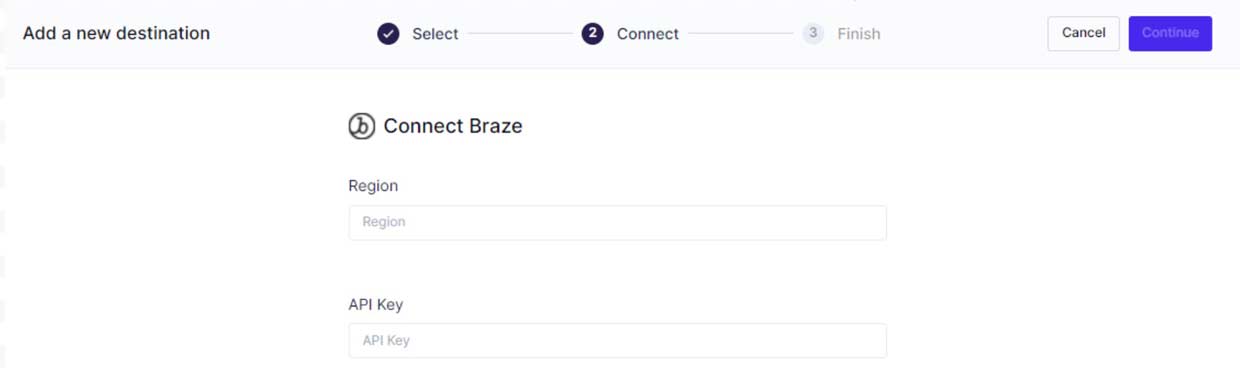
Step 2: Connect Hightouch to your destination.
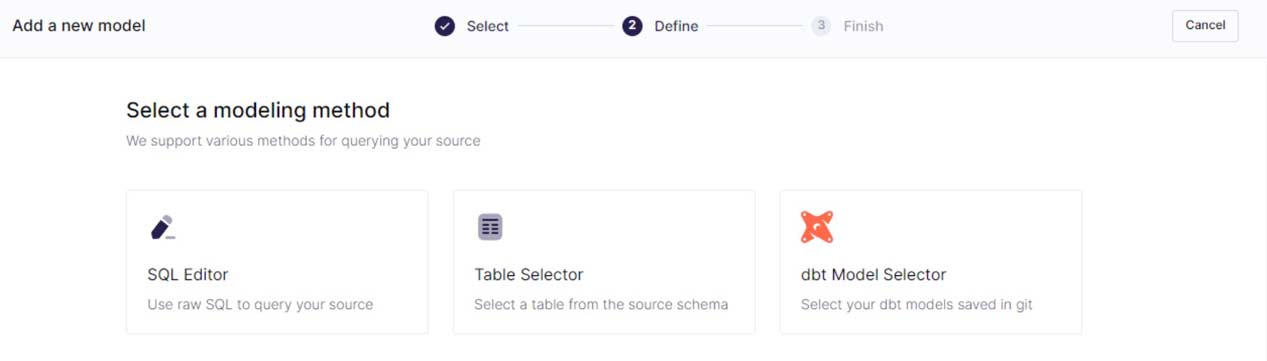
Step 3: Create a data model or leverage an existing one.
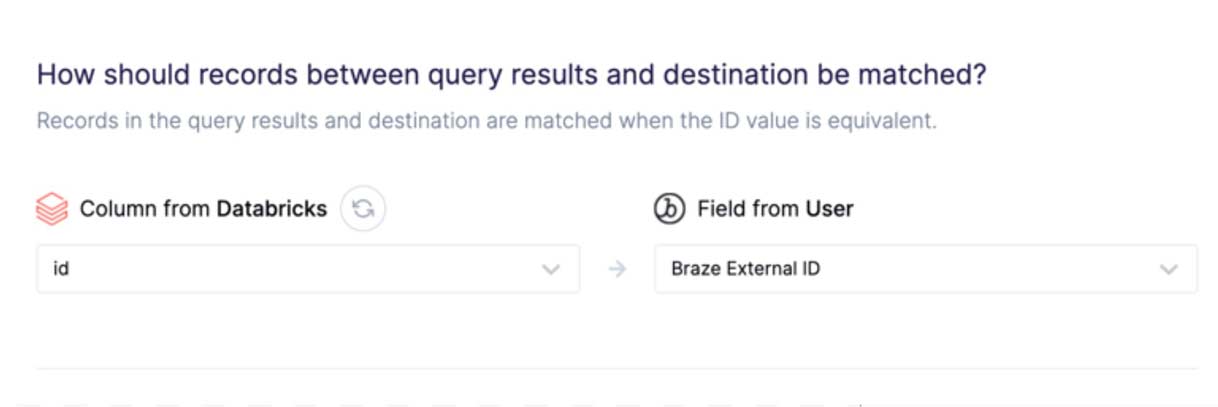
Step 4: Choose your primary key.
Step 5: Create your sync and map your Databricks columns to your end destination fields.
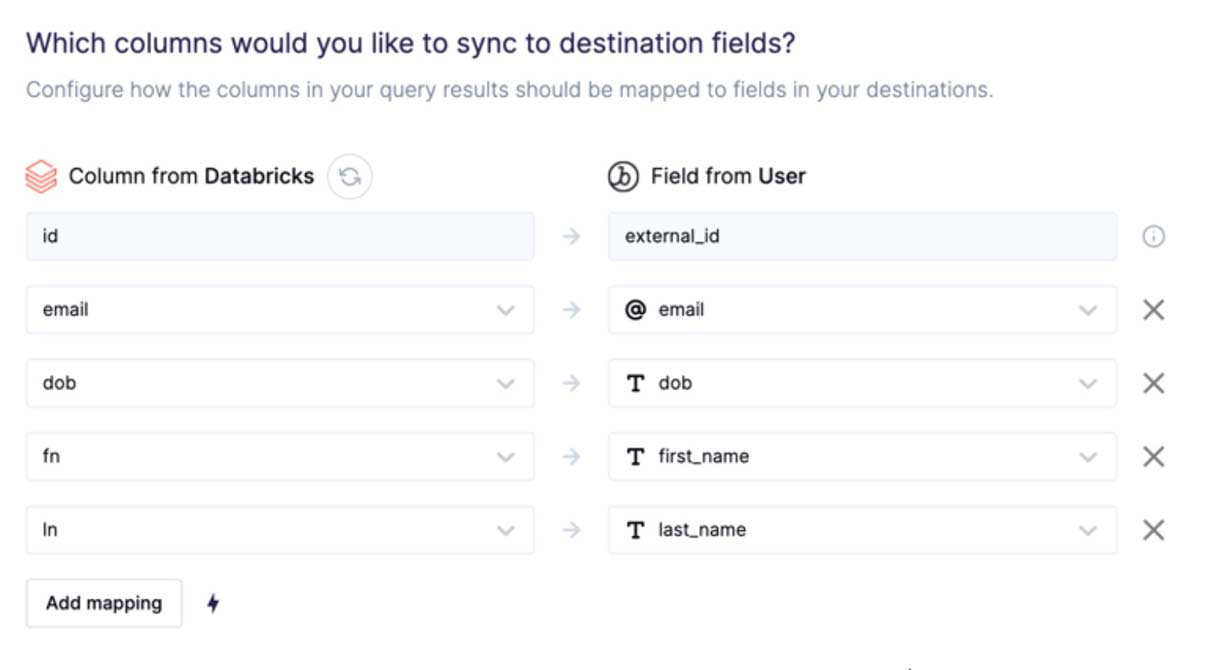
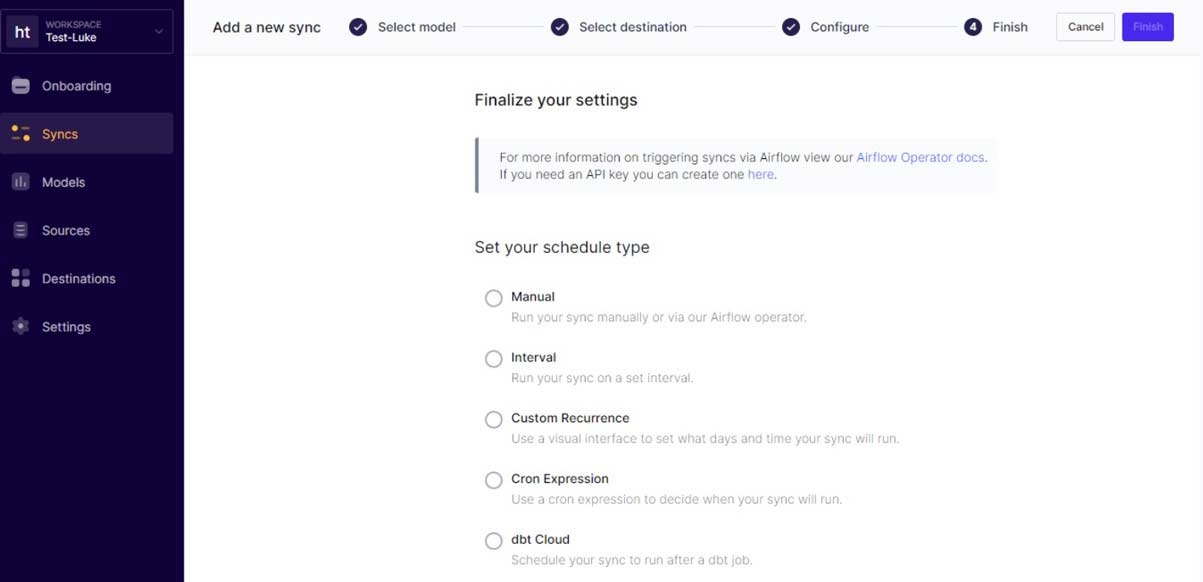
Step 6: Schedule your sync.
Getting started with Databricks and Hightouch
Visit Databricks docs for more information about how to start sending data from Databricks to Hightouch. You can test the integration on Databricks for free by signing up for a 14-day free trial. If you want to learn more about Reverse ETL, download Hightouch’s guide. The first integration with Hightouch is free so you can test it yourself or book a demo here.
- Data models: (subscription type, LTV, ARR, product qualified lead, content watched, etc.)
- Product usage data: (messages sent, last login, workspaces created, new users, etc.)
- Event data: (pages viewed, session length, shopping cart abandonment, items in cart, etc.)
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.