Software Engineering Best Practices With Databricks Notebooks
Databricks Notebooks
by Rafi Kurlansik and Austin Ford
Notebooks are a popular way to start working with data quickly without configuring a complicated environment. Notebook authors can quickly go from interactive analysis to sharing a collaborative workflow, mixing explanatory text with code. Often, notebooks that begin as exploration evolve into production artifacts. For example,
- A report that runs regularly based on newer data and evolving business logic.
- An ETL pipeline that needs to run on a regular schedule, or continuously.
- A machine learning model that must be re-trained when new data arrives.
Perhaps surprisingly, many Databricks customers find that with small adjustments, notebooks can be packaged into production assets, and integrated with best practices such as code review, testing, modularity, continuous integration, and versioned deployment.
To Re-Write, or Productionize?
After completing exploratory analysis, conventional wisdom is to re-write notebook code in a separate, structured codebase, using a traditional IDE. After all, a production codebase can be integrated with CI systems, build tools, and unit testing infrastructure. This approach works best when data is mostly static and you do not expect major changes over time. However, the more common case is that your production asset needs to be modified, debugged, or extended frequently in response to changing data. This often entails exploration back in a notebook. Better still would be to skip the back-and-forth.
Directly productionizing a notebook has several advantages compared with re-writing. Specifically:
- Test your data and your code together. Unit testing verifies business logic, but what about errors in data? Testing directly in notebooks simplifies checking business logic alongside data representative of production, including runtime checks related to data format and distributions.
- A much tighter debugging loop when things go wrong. Did your ETL job fail last night? A typical cause is unexpected input data, such as corrupt records, unexpected data skew, or missing data. Debugging a production job often requires debugging production data. If that production job is a notebook, it's easy to re-run some or all of your ETL job, while being able to drop into interactive analysis directly over the production data causing problems.
- Faster evolution of your business logic. Want to try a new algorithm or statistical approach to an ML problem? If exploration and deployment are split between separate codebases, any small changes require prototyping in one and productionizing in another, with care taken to ensure logic is replicated properly. If your ML job is a notebook, you can simply tweak the algorithm, run a parallel copy of your training job, and move to production with the same notebook.
"But notebooks aren't well suited to testing, modularity, and CI!" - you might say. Not so fast! In this article, we outline how to incorporate such software engineering best practices with Databricks Notebooks. We'll show you how to work with version control, modularize code, apply unit and integration tests, and implement continuous integration / continuous delivery (CI/CD). We'll also provide a demonstration through an example repo and walkthrough. With modest effort, exploratory notebooks can be adjusted into production artifacts without rewrites, accelerating debugging and deployment of data-driven software.
Version Control and Collaboration
A cornerstone of production engineering is to have a robust version control and code review process. In order to manage the process of updating, releasing, or rolling back changes to code over time, Databricks Repos makes integrating with many of the most popular Git providers simple. It also provides a clean UI to perform typical Git operations like commit, pull, and merge. An existing notebook, along with any accessory code (like python utilities), can easily be added to a Databricks repo for source control integration.
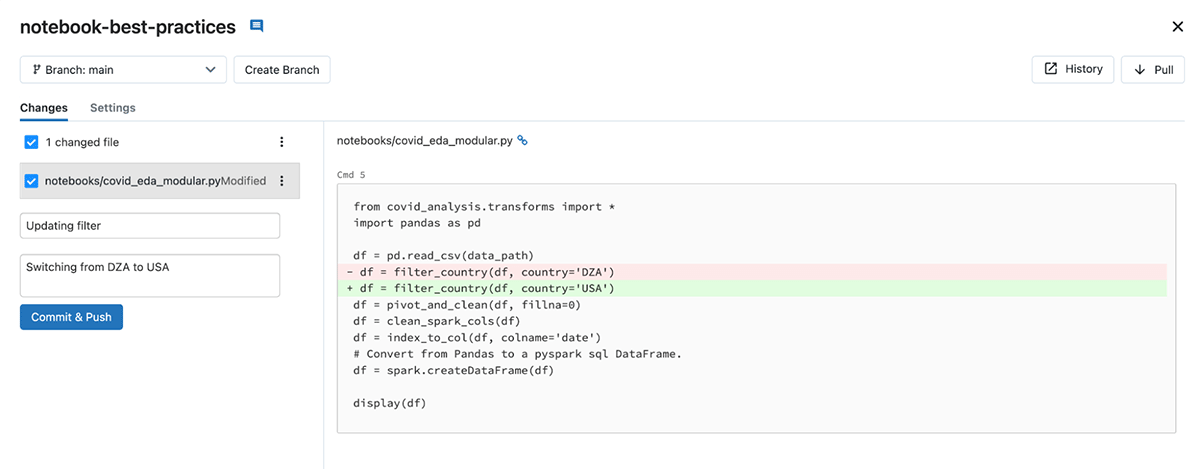
Having integrated version control means you can collaborate with other developers through Git, all within the Databricks workspace. For programmatic access, the Databricks Repos API allows you to integrate Repos into your automated pipelines, so you're never locked into only using a UI.
Modularity
When a project moves past its early prototype stage, it is time to refactor the code into modules that are easier to share, test, and maintain. With support for arbitrary files and a new File Editor, Databricks Repos enable the development of modular, testable code alongside notebooks. In Python projects, modules defined in .py files can be directly imported into the Databricks Notebook:
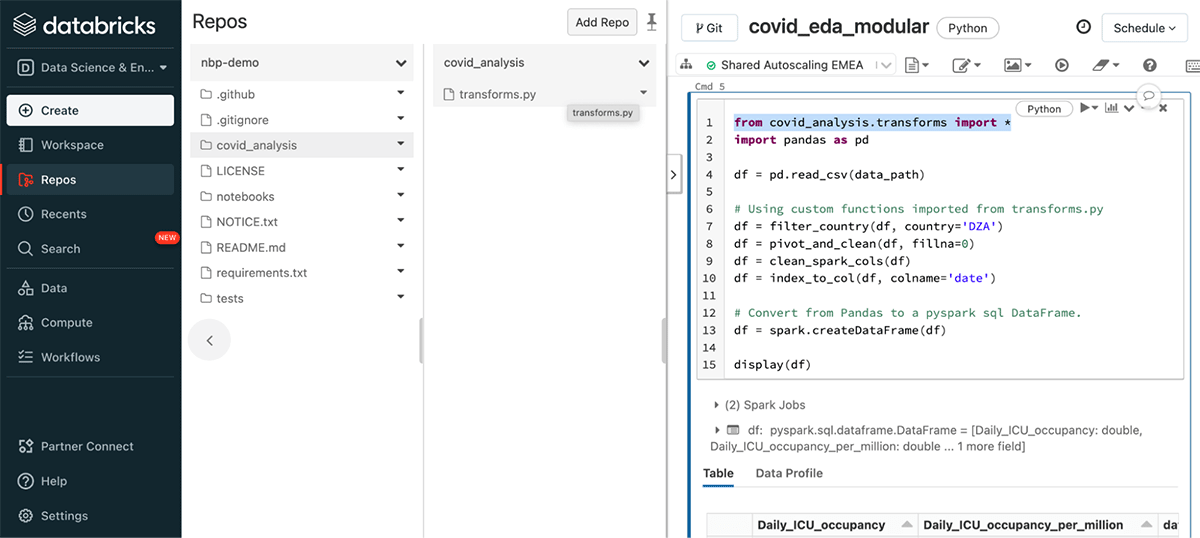
Developers can also use the %autoreload magic command to ensure that any updates to modules in .py files are immediately available in Databricks Notebooks, creating a tighter development loop on Databricks. For R scripts in Databricks Repos, the latest changes can be loaded into a notebook using the source() function.
Code that is factored into separate Python or R modules can also be edited offline in your favorite IDE. This is particularly useful when cosebases become larger.
Databricks Repos encourages collaboration through the development of shared modules and libraries instead of a brittle process involving copying code between notebooks.
Unit and Integration Testing
When collaborating with other developers, how do you ensure that changes to code work as expected? This is achieved through testing each independent unit of logic in your code (unit tests), as well as the entire workflow with its chain of dependencies (integration tests). Failures of these types of test suites can be used to catch problems in the code before they affect other developers or jobs running in production.
To unit test notebooks using Databricks, we can leverage typical Python testing frameworks like pytest to write tests in a Python file. Here is a simple example of unit tests with mock datasets for a basic ETL workflow:

We can invoke these tests interactively from a Databricks Notebook (or the Databricks web terminal) and check for any failures:

When testing our entire notebook, we want to execute without affecting production data or other assets - in other words, a dry run. One simple way to control this behavior is to structure the notebook to only run as production when specific parameters are passed to it. On Databricks, we can parameterize notebooks with Databricks widgets:
The same results can be achieved by running integration tests in workspaces that don't have access to production assets. Either way, Databricks supports both unit and integration tests, setting your project up for success as your notebooks evolve and the effects of changes become cumbersome to check by hand.
Continuous Integration / Continuous Deployment
To catch errors early and often, a best practice is for developers to frequently commit code back to the main branch of their repository. There, popular CI/CD platforms like GitHub Actions and Azure DevOps Pipelines make it easy to run tests against these changes before a pull request is merged. To better support this standard practice, Databricks has released two new GitHub Actions: run-notebook to trigger the run of a Databricks Notebook, and upload-dbfs-temp to move build artifacts like Python .whl files to DBFS where they can be installed on clusters. These actions can be combined into flexible multi-step processes to accommodate the CI/CD strategy of your organization.
In addition, Databricks Workflows are now capable of referencing Git branches, tags, or commits:
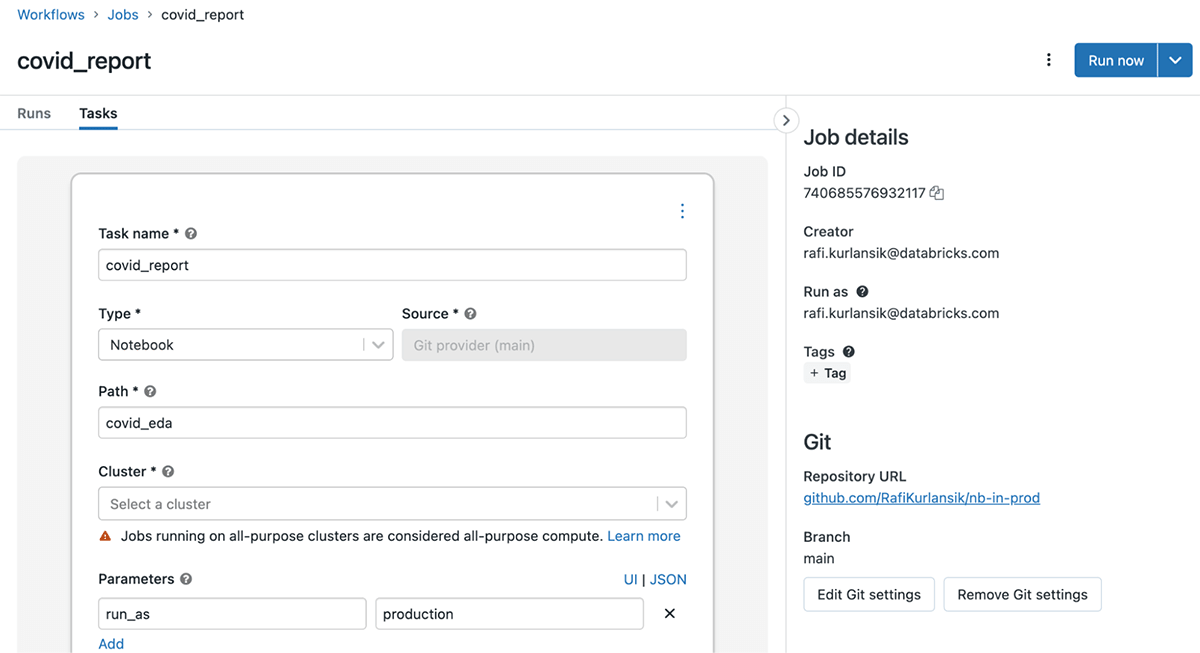
This simplifies continuous integration by allowing tests to run against the latest pull request. It also simplifies continuous deployment: instead of taking an additional step to push the latest code changes to Databricks, jobs can be configured to pull the latest release from version control.
Conclusion
In this post we have introduced concepts that can elevate your use of the Databricks Notebook by applying software engineering best practices. We covered version control, modularizing code, testing, and CI/CD on the Databricks Lakehouse platform. To learn more about these topics, be sure to check out the example repo and accompanying walkthrough.
Learn more
- Github repo: https://github.com/databricks/notebook-best-practices/blob/main/README.md
- Documentation: https://docs.databricks.com/notebooks/best-practices.html
- Service Principals for CI/CD : https://docs.databricks.com/dev-tools/ci-cd/ci-cd-sp.html
Share Feedback
- Databricks Community - Best Practices Discussions:
https://community.databricks.com/s/topic/0TO3f000000CiJeGAK/best-practices - Ideas Portal:
https://ideas.databricks.com
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.