Enabling Operational Analytics on the Databricks Lakehouse Platform With Census Reverse ETL
by Prasad Kona and Parker Rogers
This is a collaborative post from Databricks and Census. We thank Parker Rogers, Data Community Advocate, at Census for his contributions.
In this article, we'll explain how using Census's reverse ETL (rETL) makes you – a data professional – and your data lakehouse even more valuable to your organization. We'll answer all your questions, including:
- What is reverse ETL with Census?
- Why does reverse ETL with Census make you and your data lakehouse more valuable?
- How do you launch reverse ETL in your data lakehouse today?
If you've created a data lakehouse that your organization trusts and utilizes – congratulations! This is a significant accomplishment, and the hardest work for your data team is already behind you.
Now, we want to introduce a simple, non-time-consuming solution to help you make data even more valuable and actionable in your organization. Whether you're a data scientist, analyst, or analytics engineer, the implementation of this solution can benefit you.
It's called reverse ETL with Census, and here are a few (or many!) things it can help you accomplish:
- The ability to deliver trustworthy data and insight from Databricks to all the tools used by your sales, marketing, and ops teams
- The ability to create a consistent picture for everybody in every tool
- The ability to reach every one of your customers at any scale at just the right time.
- The ability to bridge the data gap and human gap between data and ops teams.
First, let's learn about what reverse ETL is.
What is Reverse ETL with Census?
Reverse ETL is the process of syncing data from a source of truth (like your data lakehouse) to a system of actions (whether that's your CRM, advertising platform, or another SaaS application). This essentially flips the original ETL process, allowing you to extract data from the lakehouse, transform it, so it plays nicely with your target destination's API, and then load it into your desired target app.
Why does this process need to be flipped anyway?
While traditional ETL worked well for a limited volume of data, as the data industry has exploded and the sheer amount of volume that organizations are handling has grown in tandem, the data engineers who once had ample bandwidth to process and answer your data-related questions, no longer do. With a lack of hands to process your data and pull out valuable insights, you need more sophisticated tools and processes (like rETL) to operationalize your analytics.
Now, that's a high-level overview, so let's explore the meat of the "why."
Why Reverse ETL with Census makes you and your data lakehouse more valuable
Reverse ETL has use cases for every (yes, every) department in your organization, but we'll focus on a common one: Sales.
Imagine your sales team wants to know which leads they should prioritize for outbound efforts. In your lakehouse, you create a query that scores your leads based on certain criteria – whether that's company size/industry, job title, interactions with your product/marketing website, etc. Here, the higher the lead score, the higher the priority for outbound efforts.
At this point, you have the data you need, but two huge questions prevent you from putting it into action:
How will you deliver it to your sales team?
How can you ensure it drives value?
The traditional approach is to deliver it to a BI tool or CSV file and hope the sales team utilizes it. Sure, they might use it, but more than likely, they'll forget about it. That's just the way this process used to work.
But with reverse ETL, you can send the data directly from your data lake to the SaaS tools your sales team lives in (Outreach, Hubspot, Salesforce, etc), so you can ensure the data is always top of mind for your sales reps, helping them drive value in every interaction.
But how does Census get the data into your SaaS tools, ensuring timeliness and accuracy (all while keeping your data secure)? Census is built on several key building blocks: Models, segments, and syncs.
- Models are your cleaned and prepped lakehouse data that will be sent to your SaaS apps. Models can be composed inside Census's segment builder via SQL, exposing dbt models, or exposing Looker Looks.
- Segments aren't required, but they provide a convenient way to segment your marketing data from a single model. This enables you to feed different segments to different marketing lists from a single model.
- Syncs move the data from a model/segment into the destination. They allow you to map your source fields to your destination fields and they provide scheduling and orchestration. You can schedule your syncs to run in batches or continuously, leading to near real-time syncs.
These building blocks are surrounded by three governance layers:
- Observability. Alerts you to any issues with your syncs both while creating the sync and while they run on a schedule. This is composed of sync history, API inspector, sync logs, sync alerts, and sync dry runs.
- Access Controls. Enable you to restrict data access to the right team members.
- Data Security. Census takes a unique approach to data security. Census is designed to run inside your lakehouse. This "low-touch" architecture uses Databricks's execution engine to perform sensitive operations, meaning that validation, transformation, and state tracking all happen without your data ever touching Census's servers. This makes your data "secure by default".
Once that data is delivered to your SaaS tool, here's what it might look like to your Sales folks:
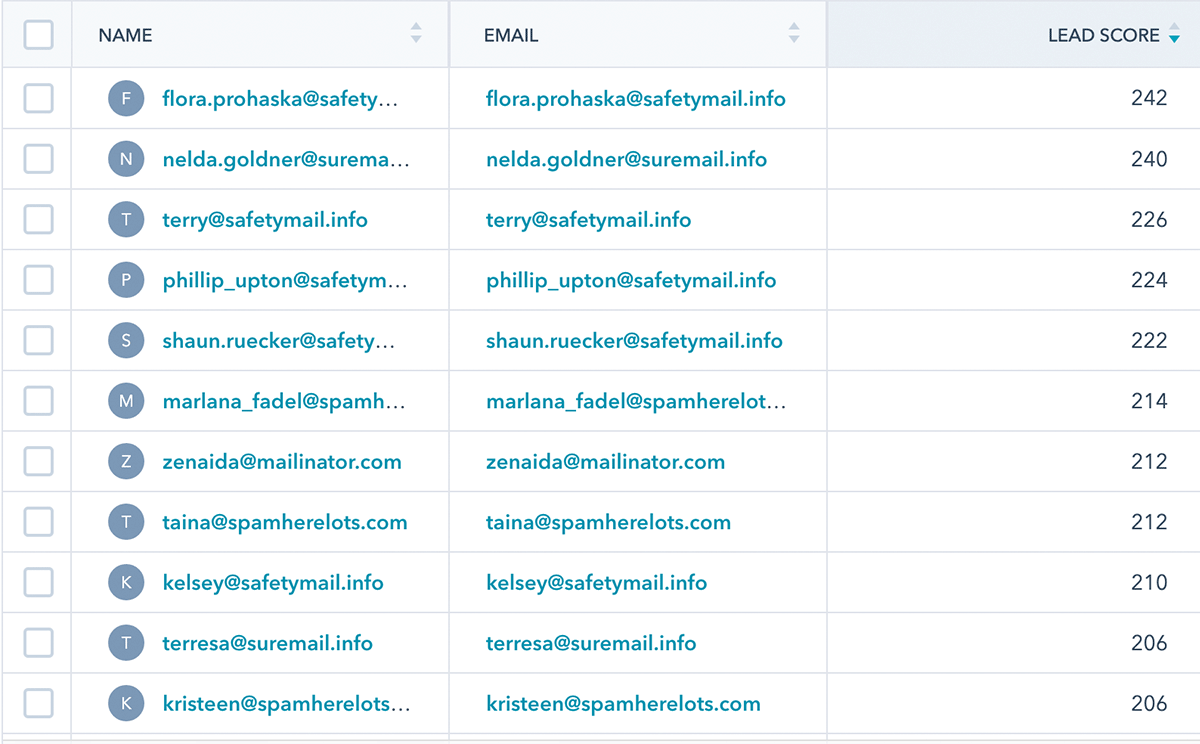
Sure, that's a high-level example, but check out how YipitData is using reverse ETL to empower their sales and customer success teams.
How YipitData uses reverse ETL
Like many others, YipitData uses reverse ETL to sync customer data from their data lake to Salesforce. As a result, their Sales and Customer Success teams are selling more effectively and preventing potential churn. Here's how they do it:
- Lead Scoring: Using product and marketing website data stored in their Databricks cluster, YipitData identifies the best-fitting prospective customers and prioritizes their sales team's time to reach out to these leads.
- Churn Scoring: Using product data from Databricks, YipitData creates various metrics to identify accounts that are likely to churn (ex: active users, active products, last login, etc.) This data helps the customer success team prioritize accounts to avoid churn.
- Customer 360: YipitData syncs relevant contact activities (ex. most recent email, most recent meeting, more recent cold call) to individual Salesforce contacts. This creates cohesion between all their go-to-market activities.
How to launch reverse ETL on Databricks
You can launch Census rETL today. Using the sales example above, here's how.
Step 1: Connect Databricks to Census
To establish the connection, you'll need the server hostname, port, HTTP path, and access token for a Databricks cluster. Choose a Databricks cluster running an LTS version like 7.3, 9.1, or 10.4. You can find the required credentials in these two documents:
After you enter your access token, you'll need to add the following configuration parameters to your cluster by navigating from Clusters > [Your Cluster] > Advanced Options > Spark.

If the CENSUS schema has not been created, create it by running:

If you need help or run into any issues while connecting to Databricks, check out this documentation (or just holler at us directly).
Step 2: Connect to a destination SaaS application
This example uses HubSpot as the service destination.
Connecting to a service destination usually only requires your login credentials, so enter those as shown.
Once you're connected, you can start the fun part: Modeling your data.
Step 3: Modeling your data
Create a model using data from Databricks. In this example, we're creating a "lead score" to identify which leads are the highest priority for a sales team's outbound efforts.
Because a model is simply a SQL query, if you know SQL, you can send whatever data you'd like to dozens of frontline tools used by your organization. In this example, we used the following model:
Step 4: Sync your data
This is where the "reverse ETL" magic happens. ðŸª"In a sync, data is sent from a model to a destination (i.e. HubSpot). In this case, we're sending the "Lead Score" model to a custom HubSpot field called "Lead Score", resulting in a custom lead score for each contact in your HubSpot account.
Step 6: Create a sync schedule
In addition to running a sync, you can automatically schedule your sync. Here, we're running the Databricks-to-HubSpot sync every morning at 10:00 am. This means that if new data is loaded into your Databricks account, Census will automatically include it in the sync every morning.
Step 7: If necessary, troubleshoot your sync with the Live API Inspector
We hope you don't have to debug your data, but if you do, we've got you covered! If you're running into issues, check out our live API inspector to find your issues and get your syncs running smoothly.
The "what", "why", and "how" of Databricks + Census rETL
Databricks is the heart of your data and AI strategy (and rightfully so!), but now you need to make it accessible to an even wider audience. That's where Census reverse ETL comes in. By putting your data in your frontline operational apps, the lakehouse can be extended to different end-users in the org.
- Want to see how this would work with your Databricks setup? Book a demo with a Census product specialist.
- If you don't have your data, analytics, and AI on a single platform yet, get started with Databricks for free.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.