Work With Large Monorepos With Sparse Checkout Support in Databricks Repos
by Vaibhav Sethi and Xiaodong Wang
For your data-centered workloads, Databricks offers the best-in-class development experience and gives you the tools you need to adhere to code development best practices. Utilizing Git for version control, collaboration, and CI/CD is one such best practice. Customers can work with their Git repositories in Databricks via the 'Repos' feature which provides a visual Git client that supports common Git operations such as cloning, committing and pushing, pulling, branch management, visual comparison of diffs and more.
Clone only the content you need
Today, we are happy to share that Databricks Repos now supports Sparse Checkout, a client-side setting that allows you to clone and work with only a subset of your repositories' directories in Databricks. This is especially useful when working with monorepos. A monrepo is a single repository that holds all your organization's code and can contain many logically independent projects managed by different teams. Monorepos can often get pretty large and beyond the size of Databricks Repos supported limits.
With Sparse Checkout you can clone only the content you need to work on in Databricks, such as an ETL pipeline or a machine learning model training code, while leaving out the irrelevant parts, such as your mobile app codebase. By cloning only the relevant portion of your code base, you can stay within Databricks Repos limits and reduce clutter from unnecessary content.
Getting started
Using Sparse Checkout is simple:
- First, you will need to add your Git provider personal access token (PAT) token to Databricks which can be done in the UI via Settings > User Settings > Git Integration or programmatically via the Databricks Git credentials API
- Next, create a Repo, and check the 'Sparse checkout mode' under Advanced settings
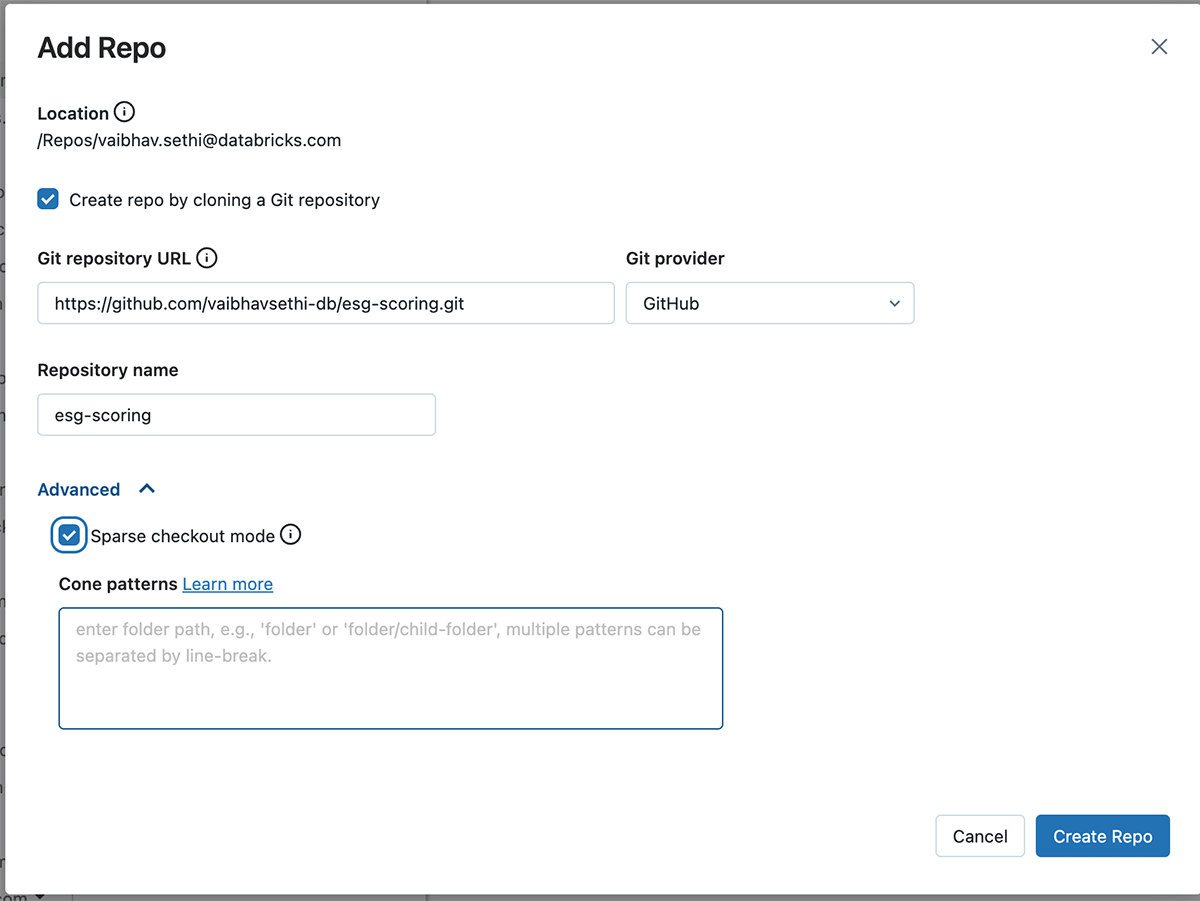
- Specify the pattern you want to include in the clone
To illustrate Sparse Checkout, consider this sample repository with following directory structure
Now say you want to only clone a subset of this repository in Databricks, say the following folders 'notebooks/data_prep', 'utils' and 'tests'. To do so, you can specify these patterns separated by newline when creating the Repo.
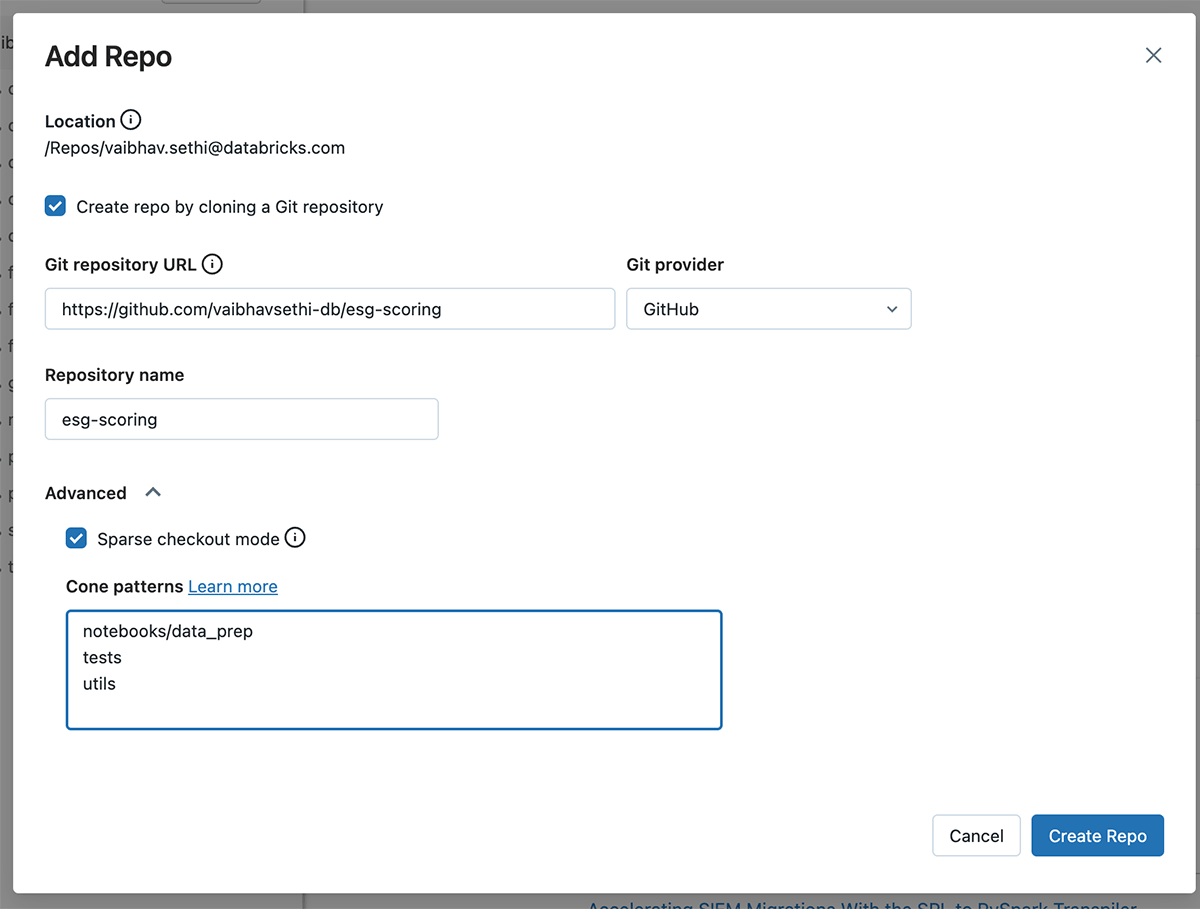
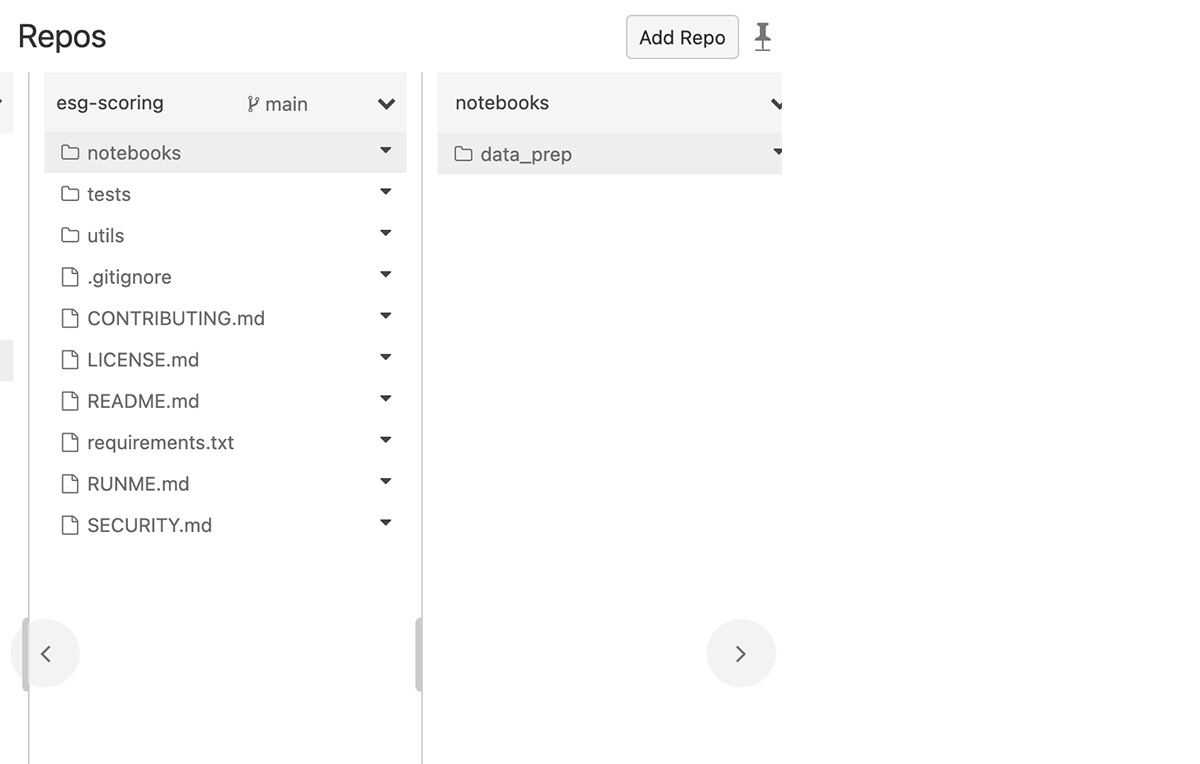
This will result in inclusion of the directories and files in the clone, as shown in image below. Files in the repo root and contents in 'tests' and 'utils' folders are included. Since we specified 'notebooks/data_prep' in the pattern above only this folder is included; 'notebooks/scoring' is not cloned. Databricks Repos supports 'Cone Patterns' for defining sparse checkout patterns. See more examples in our documentation. For more details about the cone pattern see Git's documentation or this GitHub blog
You can also perform the above steps via Repos API. For example, to create a Repo with the above Sparse Checkout pattern you make the following API call:
POST /api/2.0/repos
-
Edit code and perform Git operations
You can now edit existing files, commit and push them, and perform other Git operations from the Repos interface. When creating new folders of files you should make sure they are included in the cone pattern you had specified for that repo.
Including a new folder outside of the cone pattern results in an error during the commit and push operation. To rectify it, edit the cone pattern from your Repo settings to include the new folder you are trying to commit and push.
Ready to get started? Dive deeper into the Databricks Repos documentation and give it a try!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.