Unsupervised Outlier Detection on Databricks
Kakapo - integration for PyOD, MLflow and Hyperopt
by Iliya Kostov, Milos Colic and Michele Caputo
![]() Kakapo (KAH-kə-poh) implements a standard set of APIs for outlier detection at scale on Databricks. It provides an integration of the vast PyOD library of outlier detection algorithms with MLFlow for tracking and packaging of models and Hyperopt for exploring vast, complex and heterogeneous search spaces.
Kakapo (KAH-kə-poh) implements a standard set of APIs for outlier detection at scale on Databricks. It provides an integration of the vast PyOD library of outlier detection algorithms with MLFlow for tracking and packaging of models and Hyperopt for exploring vast, complex and heterogeneous search spaces.
The views expressed in this article are privately held by the author and cannot be attributed to the European Securities and Markets Authority (ESMA)
Anomaly detection methods permeate many industries. Whether the use case is fraud, service deterioration, traffic congestion, network monitoring, etc., chances are that outlier detection tools and techniques are needed to generate insights. Detecting outliers is an important phase of the typical data science workflow: once the data is cleaned and augmented with bespoke features, a predictive model may yield suboptimal results in the presence of outliers. Identifying them may also be the end goal. In either case it would be desirable to have a simple and scalable framework, easy to implement and to adapt to evolving requirements.
To set things in place, in this blog post we will stick to Wikipedia's definition of anomaly detection: "In data analysis, anomaly detection (also referred to as outlier detection and sometimes as novelty detection) is generally understood to be the identification of rare items, events or observations which deviate significantly from the majority of the data and do not conform to a well defined notion of normal behavior.". So we'll consider the two terms as synonyms.
Where to start when working with outlier detection? Which framework should one select? Which technique should be adopted? What to do in the absence of labeled data? What to do if the number of anomalies to expect is unknown?
Beyond technical aspects of outlier detection, there are several wider considerations that may come to mind when embarking on implementing robust solutions:
- Future proofing and scalability, i.e. how to handle not just today's workloads but have a framework that scales as requirements change - e.g. volume/ velocity/ complexity increases
- Productivity and collaboration, i.e. how to ensure that work and ideas can be easily shared
- Governance and auditability, i.e. how to can collect and log metadata, ensure robust audit trails and ultimately produce data that can be trusted
In this blog post we provide a standard set of APIs to perform anomaly detection at scale on Databricks. The solution integrates with MLflow (for tracking and packaging of models) and Hyperopt (for model and hyperparameter tuning). We will provide a step by step guide, starting with a simple model wrapper template which will allow for the integration of a number of outlier detection algorithms included in the PyOD library with MLflow for easy and scalable tracking and auditability. The output is meant to be an extendable framework that can be used as-is or enriched further. At the heart of this framework are the library Kakapo, MLflow and Hyperopt.
Why do outliers matter?
Statistics and insights are only as good as the underlying data is in the definition of anomaly detection above, we identify the term "significant" as something to be determined on a case by case basis and that is somewhat subjective. This is because there is no rigid mathematical definition of what an outlier is. Chebyshev's inequality, Dixon's Q test, Chauvenet's criterion, Mahalanobis distance or perhaps others - are all approaches that aim to answer the question "What different than expected looks like?" - the question of expectancy, which is complemented by the question "How can one identify the 'different' (observations)?". Small differences in the inequalities definitions may have a significant impact on the performances, just because of the context.
The question of expectancy is transversal across industries. It is put front and center by the regulated industries, as it is regulators' duty to be vigilant with the monitoring of their respective industries. "Regulators should take an evidence based approach to determining the priority risks in their area of responsibility, …" - UK Regulators' Code. The evidence-based approach is essentially as effective as our ability to consume and correctly interpret the data. The statistical nature of data points (ie. whether something is an anomaly or not) is critical for these considerations. Another example of the importance of the question of expectancy can be found in the very same mission statement of the European Securities and Markets Authority (ESMA): "One mission: to enhance investor protection and promote stable and orderly financial markets". In order to properly model stable and orderly markets one is required to understand what unstable and unorderly behaviors look like. This is where anomaly detection can bring substantial value towards achieving data driven regulatory activities. Finally, it is regulatees duty to adhere to the same norms and standards imposed and monitored by the regulators. And in order to adhere to these norms regulatees require the same tools in order to detect anomalous and erroneous events in the way they deliver their business and fix these issues proactively.
The same principles likewise are pertinent outside the regulated industries. In private and third sectors, the question of expectancy is as important and as critical as it'll ever be - it simply applies to different use cases. In these sectors detection out of ordinary data could help prevent undesired customer churn and deflection to competition, or help tackle increase in fraud cases and automate fraud detection, or perhaps help improve predictive maintenance. Out of ordinary observations are either evidence of unexpected events or harbingers of events to come. Correct data driven decisions are impossible without taking into account the full nature of the available data - and out of ordinary observations are a powerful tool for better decision making in any industry.
The case for label-less model evaluation
In many, if not the majority of cases, it is hard to get a hand on labeled anomalous data or to quantify the volume of the expected number of anomalies per data asset. It is a complex task that can be time-consuming and expensive, both in terms of energy and costs. Even with labeled data, many other outliers could still exist and muddy the evaluation criteria. In addition, for many organizations it is prohibitive to attempt to label hundreds of data assets they may have, all of which could (or do) have potential anomalies.
We have designed the kakapo library with this in mind and exposed the exact same set of APIs to carry out both supervised and unsupervised model evaluation with no changes in the code but via passing a simple flag parameter. In the case when we do have no labeled data, we compute an unsupervised metric that only depends on the features and their distribution (in this case, we have computed the EM/MV metrics based on N. Goix et al.).
In addition, by taking advantage of the Kakapo library's integrations which we cover in this blog, we are able to train hundreds of models with varied hyper parameters at scale and we can freely create "ensemble" models (i.e. using multiple models in parallel) to generate a consensus type anomaly prediction without relying on any one single model.
Simplification, standardization and unifications unlock the value out of these complex situations we described above. Throughout this blog we will be using PyOD, MLflow and Hyperopt to promote these principles and to promote best practices and clean system design for anomaly detection use cases.
PyOD - The identification toolbox
"PyOD is the most comprehensive and scalable Python library for detecting outlying objects in multivariate data." - PyOD.
The breadth of the offering coming from PyOD is perfectly in line with the aforementioned quote. PyOD offers over 40 different models for anomaly detection including both traditional and deep models. This makes PyOD an essential tool in the repertoire of any data scientist - be it a seasoned veteran or new aspirant.
PyOD includes a unified API and a large selection of detection algorithms - from classical staples like Isolation Forest to newer entrants such as ECOD, all the while boasting more than 10 million downloads - giving it the industry stamp of approval and adoption.
Finally - probably the most appealing aspect of the framework - is its simplicity and ease of use. Implementing an outlier detection algorithm takes no more than a few lines of code:
Why not simply use Isolation Forest? All of these benefits put forth PyOD as a strong candidate for unification and simplification of the outlier detection efforts and system design:
- The code base will be more robust with a flexibility that allows for a substitution or an augmentation of the current anomaly detection technique.
- The code base will be slimmer and more declarative.
- By integrating with MLflow and hyperopt, the proposed framework will allow for delivering outlier detection both in cases when prior knowledge of anomalies is available and when such knowledge does not exist.
Note: There is a wealth of information on the official PyOD docs page and we strongly recommend it to anyone interested in further reading on outlier detection.
MLflow's best practices for ML lifecycle management
MLflow is amongst the most prominent open-source platforms for managing the ML lifecycle, including but not limited to experimentation, reproducibility, deployment and a central model registry. MLflow's main components are:
| MLflow Tracking | MLflow Projects | MLflow Models | MLflow Registry |
|---|---|---|---|
| Record and query experiments - code, data, config and results | Package data science code in a format to reproduce runs on any platform | Deploy ML models in diverse serving environments | Store, annotate, discover and manage models in a central repository |
The Tracking API allows the user to log parameters, metrics and a myriad of other outputs when training machine learning models in a way that is easy and accessible with just a few lines of code!
After logging each model run, either the feature-rich API or the intuitive web UI can be used to explore the experiments, comparing the results and sharing them with other data scientists:
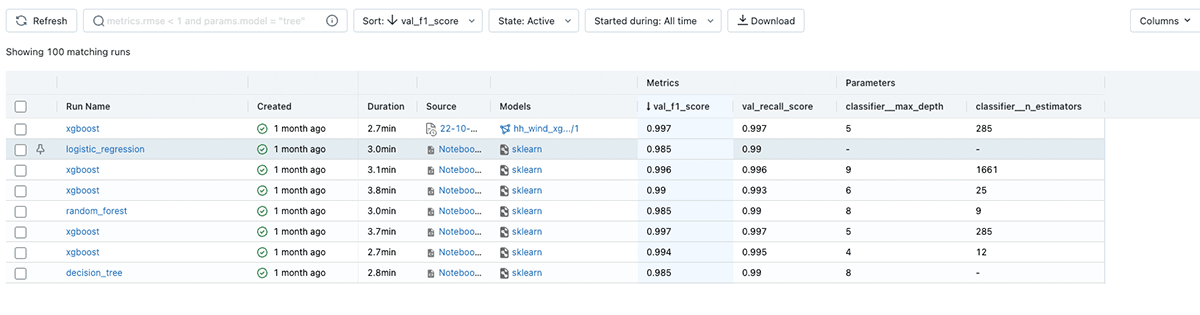
MLflow packages machine learning models in different formats (also known as "flavors") so that they can be easily deployed later on. MLflow provides several standard flavors and can automatically track and log a large number of models implemented via popular packages such as scikit-learn, XGBoost, etc.
MLflow provides a solution also for those models that are not natively supported: the python_function (pyfunc) model flavor provides the utility to create pyfunc models from arbitrary code and model data while still taking advantage of MLflow's best practices.
In the rest of this chapter, we will demonstrate one approach for wrapping arbitrary PyOD outlier detection models as a pyfunc model wrapper provided via the Kakapo package for tight integration with the rest of the MLflow ecosystem. The code blocks below will reference a method called PyodWraper which serves exactly this function - it takes a list of Pyod base models (referred to as a "model space" in the code) and implements the necessary integrations in the back end so that the models get logged and tracked by MLflow with minimal user intervention.
In the code above model_space is a dictionary of key-value pairs of the PyOD algorithms one wants to use. Kakapo provides a default model space accessible via get_default_model_space() method. Additionally, one can freely add additional models to enrich the default model space:
The main benefit of using an abstraction like Kakapo is the simplicity of the code needed to train the models for outlier detection without loss of generality and governance. The package adheres to standard APIs of MLflow and guarantees interoperability and portability while abstracting the uniqueness and specificity of each individual supported model. The end users can focus on parameter tuning and interpretation of parameters and metrics rather than on managing a complex - even boilerplate - code base.
In order to evaluate the performances of the different anomaly detection algorithms we are considering, we need some kind of metric. As we may or may not have access to labeled data, we define the flag GROUND_TRUTH_OD_EXISTS. Kakapo will behave differently according to its value:
- Ground truth labels do exist - roc_auc_score is computed and logged as the main model metric
- Ground truth labels do not exist - an unsupervised metric that only depends on the features and their distribution is computed and logged (the worked example in this blog computes the EM/MV metrics based on N. Goix et al.).
Through support of label-less data assets, we are addressing a big pain point in large data domains. Providing a labeled data asset in a data domain that may contain hundreds of datasets might be a challenge. Having a way to analyze for outliers across the entire estate is a massive benefit of the outlined approach.
The optimizer - scaling out for success with Hyperopt
The final piece of the puzzle is scaling our approach out to handle the training of hundreds of models in parallel - both using different algorithms and diverse sets of hyperparameter combinations.
Hyperopt is known as one of the most performant hyperparameter optimization libraries in Python and is widely used by data scientists. Defining a space of hyperparameters is a matter of a few lines of code. The library's API is then used to optimize the model's loss across this space.
Another powerful feature is the possibility to define a nested search space, covering multiple models and their respective hyperparameters at the same time:
Using the syntax above we can chain together a number of outlier detection models, all with their own sets of parameters as we embark on the journey to finding the best performing one (or generating a whole lot of candidate models that we then combine in an ensemble to provide majority consensus scoring to our data).
Similarly to Kakapo's get_default_model_space(), one can use get_default_search_space() to start with a default, starting Hyperopt parameter space. This as well can easily be enriched using the inbuilt methods (enrich_default_search_space()).
The only thing left to do is run Hyperopt's fmin function with the setup above which will kick off the model training in parallel.
Putting it all together
Once we have completed the training above, we can access each and every model run using the MLflow API. In the code block below we search for a particular Hyperopt run, retrieve all models that belong to it and sort them by the performance metric. We can then extract the unique run ID for the best performing model and proceed to load it.
Below we can see two alternative approaches to loading an MLflow model and generating predictions:
A) Load the model as a spark user defined function (UDF) and predict on a spark dataframe
B) Load the model as a pyfunc and predict on a Pandas dataframe
Finally, we can display the resulting dataframe (Spark or Pandas) and observe the anomaly predictions that were just generated.
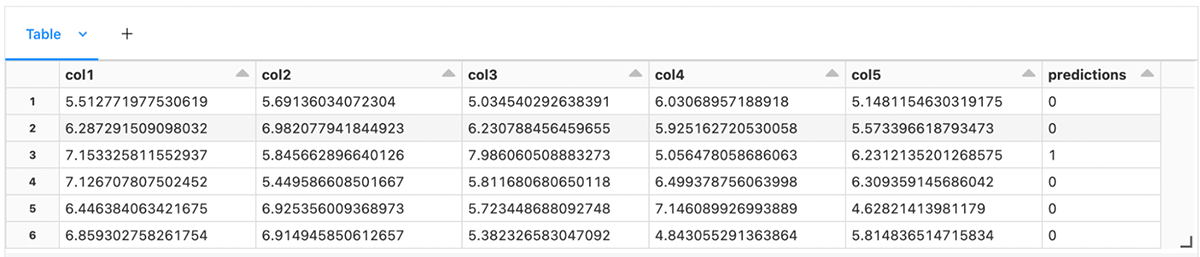
Similarly to how we loaded our best performing model based on a metric, we can also load many models in succession, generate multiple predictions per observation and aggregate the individual scores. This can be a great way to combine multiple models that have different strengths and provide higher quality predictions when used as an ensemble.
Throughout this blog we covered one approach to integrating the popular ML library - PyOD - with the best practices of the MLflow platform and taking advantage of the scaling that Hyperopt provides. We proposed a simple and extendable framework that supports both supervised and unsupervised anomaly detection modeling.
This toolbox is intended to give a quick start in the ML journey on Databricks and something that can be taken and extended with personal or company best practices.
All the code examples covered in this blog can be found in this notebook
P.S. In case you were still wondering about our naming choice for the package, Kakapo is one of the rarest birds in the world and the name seemed fitting when looking for rare and unique events!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.