Synthetic Data for Better Machine Learning
Leverage AI to generate synthetic data for better models, or safer data sharing with data teams
by Sean Owen
You've likely tried the buzziest advances in generative AI in the past year, tools like ChatGPT and DALL-E. They consume complex data and generate more data in ways that feel startlingly like something intelligent. These and other new ideas (diffusion models, generative adversarial networks or GANs) are entertaining, even frightening to play with.
However, the median daily machine learning task is to forecast sales, predict customer churn with a mess of tabular data and 'normal' data science tools, and so on – not imagining how Bosch would have drawn a still life on Mars.

What if generative AI could help with, say, a simple regression problem? There is a related class of ideas that can generate synthetic data like the real business data you have. Synthetic data is a key application of generative AI, conceived broadly.
This blog examines a few uses for synthetic data in a typical machine learning process. How can it assist that regression problem, or help with operational concerns about handling sensitive data? It will use the open source library SDV (Synthetic Data Vault) for synthetic data modeling, and use MLflow, Apache Spark and Delta to manage the synthetic data generation, and finally explore how this impacts a regression problem with Databricks Auto ML.
Why Synthetic Data for Machine Learning?
What use is made-up data for learning about the real world? Randomly made-up data wouldn't be useful. Data that closely resembles real data might be.
First, everyone wants more data, because it (sometimes) means better machine learning models. Machine learning models the real world, and so more data can create a fuller picture of that world, of what happens in corner cases, of what is just anomalous and what is repeatedly observed. Real data can be hard to come by, while an infinite amount of real-ish data is simple to obtain.
Yet synthetic data can only mimic the real data that is actually available. It can't reveal new subtleties that the real data set does not. Nevertheless, it's possible that it helpfully extrapolates what the real data implies, and that this can be beneficial in some cases.
Secondly, data is sometimes not freely shareable. It could contain sensitive personally identifiable information (PII). While it might be desirable to share the data with new teams to expedite their exploration and analysis work, sharing could require lengthy redaction, special handling, form-filling and other bureaucracy.
Synthetic data offers a middle ground, sharing data that is like sensitive data, but isn't real data. In some cases, even this may be problematic -- what if the synthetic data looks a little too like an actual data point in some cases? In other cases, it may be insufficient.
However, there are plenty of use cases where sharing synthetic data is good enough, and can speed up collaboration while retaining sufficient data security. Imagine you want a team of contractors to develop a reliable machine learning pipeline that solves a new problem, but you can't just share your sensitive data set with them. Sharing synthetic data might be more than enough for them to build a pipeline that will also work well when run on real data.
Problem: Big Tippers
To illustrate, this blog will use a well-known NYC Taxi data set. In Databricks, this is available in /databricks-datasets/nyctaxi/tables/nyctaxi_yellow. It records basic information about taxi rides in New York City over more than a decade, including pickup and drop-off point, distance, fare, tolls, and tip. It's big, billions of rows, and this example will work on a sample that starts like this:

It's simple tabular data for a simple example, and here the problem will be to predict the tip that a rider adds at the end of a trip. Maybe the in-taxi payment system wants to tactfully suggest a tip amount, where it pays to not suggest something too high -- or low.
This is an unremarkable regression problem. Yet suppose that, for various reasons, this data is considered sensitive. It would be nice to share it with contractors or data science teams, but that could mean jumping through all kinds of legal hoops. How could one expect them to make an accurate model without sharing this data?
Don't share the raw data; try sharing a synthetic version of it.
Synthetic Data in Minutes
SDV is a Python library for synthesizing data. It can mimic data in a table, across multiple relational tables, or time series. It supports approaches to modeling data like variational autoencoders (VAEs), generative adversarial networks (GANs), and copulas. SDV can enforce generated data constraints, redact PII, and more. It's pleasantly simple to use, and in fact a first pass at modeling needs no more than this snippet, using the easy-mode TabularPreset class:

At a glance, it sure looks plausible! Also included are data quality reports, which give some sense of how well the model believes its results match original data:
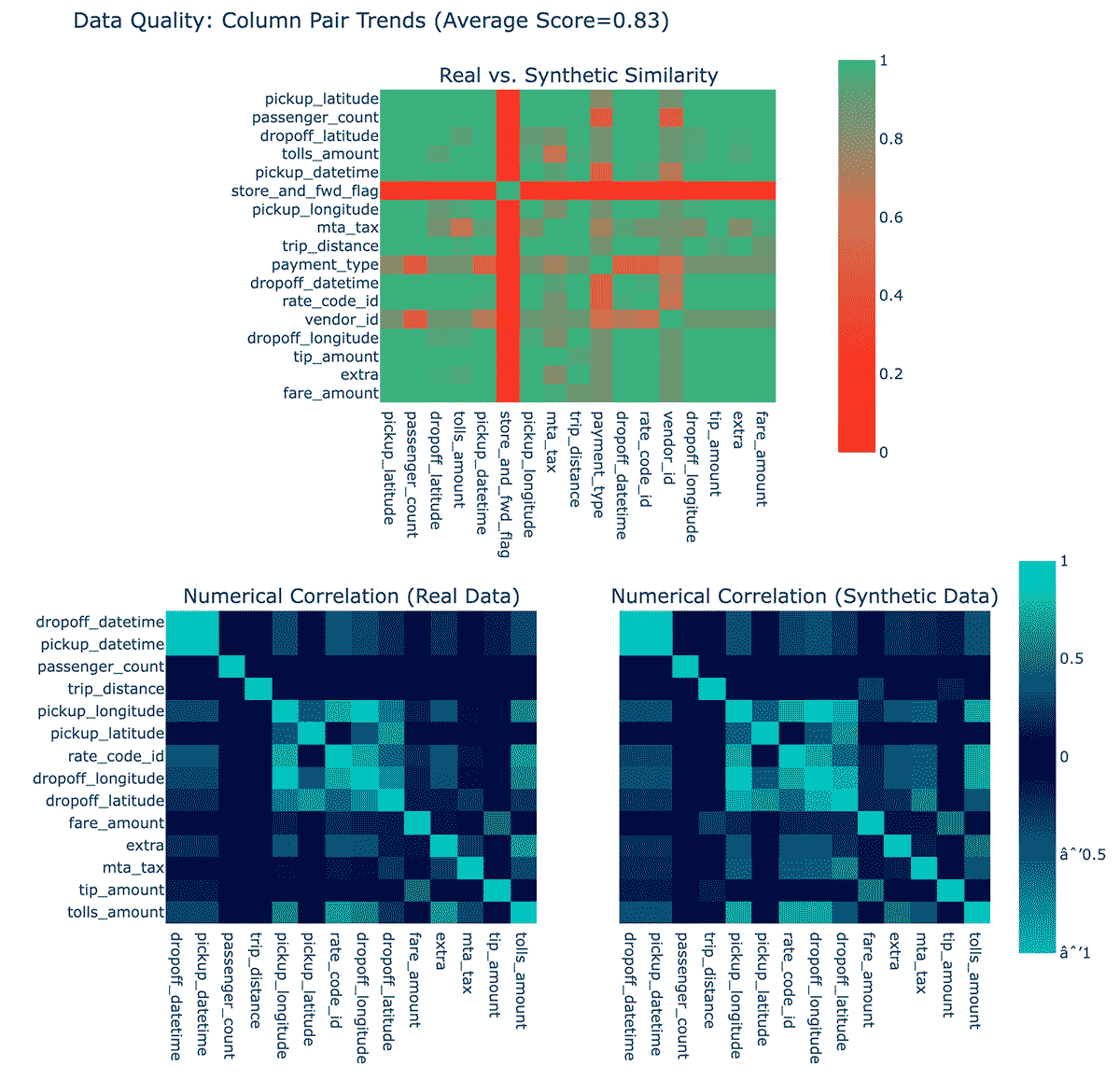
These plots show how much each column's distribution of synthetic data matches the original, and how correlated the synthetic and real data is. It boils these down into scores between 0 and 100%, and overall gives this 75%. This is "OK". (The SDMetrics library explains this in a bit more detail.) It's unclear at this point why the column store_and_fwd_flag shows much worse fidelity than other columns.
Evaluating Synthetic Data Quality
A closer look at that synthetic data (perhaps using the Data Visualization tab in Databricks!) reveals issues:
- Some monetary amounts are negative, in MTA tax or tip
- Passenger count and distance are 0 sometimes
- Distance is occasionally impossibly shorter than straight line distance
- Longitude and latitude are sometimes nowhere near New York City (or entirely invalid, like >90 degrees latitude)
- Monetary amounts have more than two decimal places
- Pickup time is occasionally after drop-off time, or sometimes more than a 12-hour shift long
In fact, many of these issues are found in the original data set. Like with any machine learning model -- garbage in, garbage out. It's worth fixing the issues in the source data, rather than attempting to emulate data with obvious problems. For simplicity, rows with evidently bad data can be removed, like any row where:
- Monetary amounts are negative
- Drop-off is before pickup, or unreasonably long after
- Locations are nowhere near New York City
- Distances aren't positive, or unreasonably large
- Distances are impossibly short given start and end point
To cut to the chase, starting over with an improved, filtered data set gives an 82% quality score. There is more to be done to improve the quality aside from fixing source data, however.
Using Constraints
Above are some conditions that the real and synthetic data should meet. The models that generate data don't by nature have a semantic understanding of the values they're generating. For example, the original data set has no fractional passenger counts or negative distances (not anymore, at least). A good model would generally learn to imitate this, but may not perfectly, if it does not otherwise know these must be integers.
SDV provides a means to express these constraints. This helps the modeling process not spend time learning to not emit obviously bad data. Constraints look like this:
It's also possible to write custom constraints, involving user-supplied logic and multiple columns. For instance, pickup and drop-off latitude/longitude are given, as well as the taxi trip distance. While the trip distance between those two points can be more than the straight line distance between them, it can't be less! That's a non-obvious required relationship among five columns, involving Haversine distance. It's easy enough to write this as a custom constraint, even allowing a little bit of wiggle-room to account for imprecision in latitude/longitude from taxi GPS:
Before trying again, it's worth looking at more powerful models as well.
Advanced Synthetic Data Modeling
The easy TabularPreset approach in SDV, used above, employs Gaussian copulas. It may be an unfamiliar name, but it's surprisingly simple, fast and effective for many problems. Look no further if TabularPreset is working well for a problem.
For complex problems, more complex models could yield better results. SDV also supports approaches based on GANs and VAEs. Both ideas employ deep learning, but in different ways. GANs pit two models against each other, one generating data and one learning to spot synthetic data, in order to refine the generator until its output is hard to distinguish from the real thing. VAEs learn to encode real data such that not only can the real data be decoded afterwards, but new synthetic data can be 'decoded' out of thin air too.
Both are much more computationally intensive, and likely require a GPU to fit in reasonable time. If a data set is hard to emulate with simple approaches, or it'd just be great to say "yeah, we are leveraging GANs," at a cocktail party, then SDV's CTGAN and TVAE are for you.
It's no more work to try TVAE in the upgraded example that follows. In addition, MLflow can be added to log the metrics, and even manage the TVAE model itself as a model whose predict function just generates more data:
Note the use of MLflow! Registering the model with MLflow records the exact model in a versioned registry. In addition to providing a record of the various models created during iterative development, the MLflow registry allows you to grant access to other users to take your model and generate synthetic data for themselves.
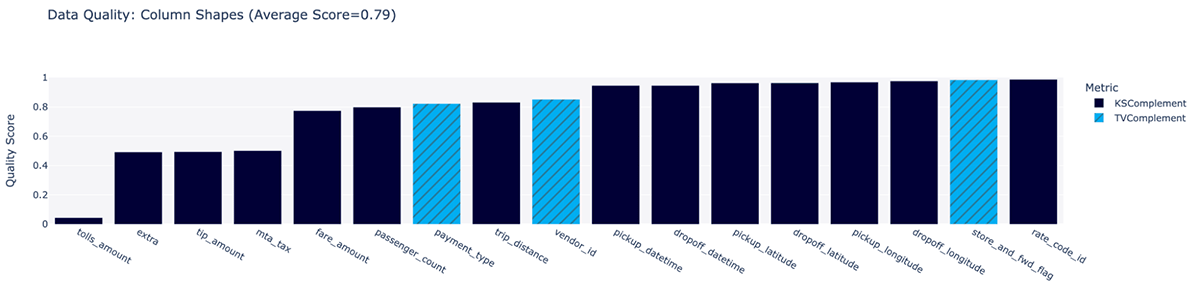
In fact, from MLflow we can check out these plots. Quality is up slightly to 83%, and a new plot is available, breaking down quality of synthesis for each column by itself:
Generating Synthetic Data
With that homework done, generating any amount of synthetic data is easy! Here some fresh new generated data lands in a Delta table. Just load the model from MLflow, write a simple Python function that uses the data generation model, and then "apply" it to dummy inputs in parallel with Spark (the UDF needs some input, but the data generation process doesn't actually need any input), and simply write the result.

Spark is very useful here to parallelize the generation, in case one needs to generate terabytes of it. This parallelizes as wide as desired.
Times, locations, and more are looking better indeed. pandas-profiling can offer a different look at how the real and synthetic data compare. This is just a slice of the report:
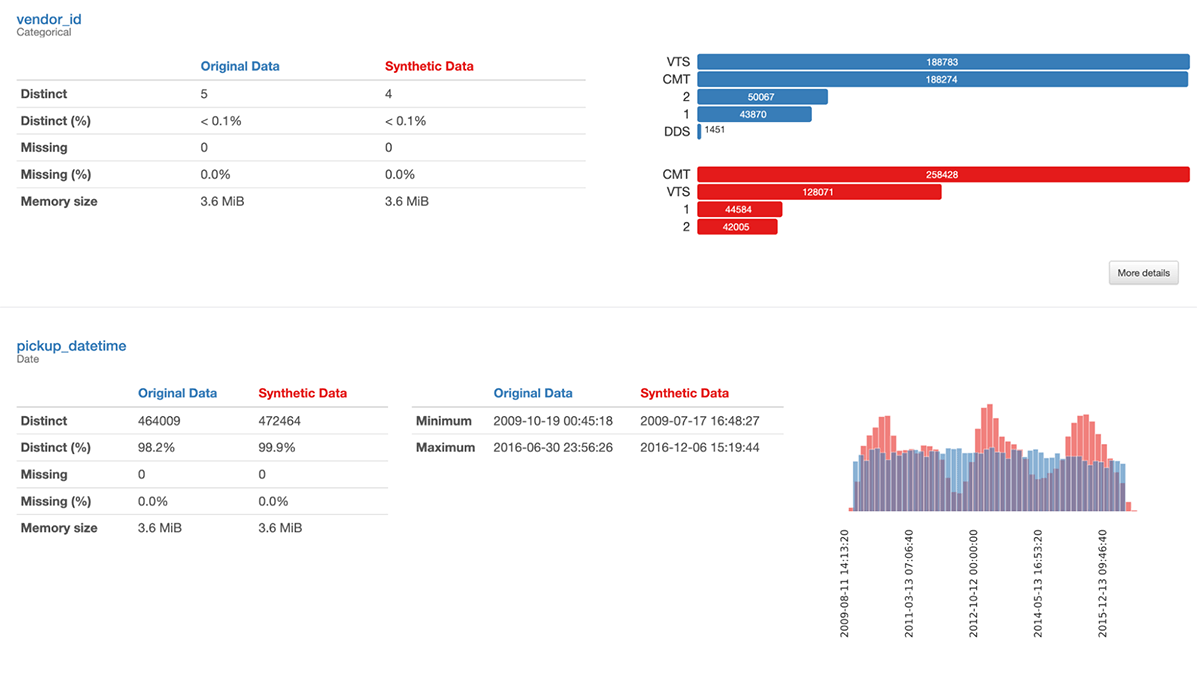
This gives more detail on why the quality isn't 100%. There is for example curious non-uniformity in pickup and drop-off time in the synthetic data, whereas the original data was pretty uniform.
For now, this will do, but a synthetic data generation process might iterate from here just like any machine learning process, discovering new improvements in the data and synthesis process to improve quality.
Modeling with Synthetic Data
The original task was to predict tips, not merely make up data. Can one usefully build machine learning models on synthetic data? Rather than spend time figuring out what a decent model might do with this data by hand, use Databricks Auto ML to make a first pass:
A few hours later:
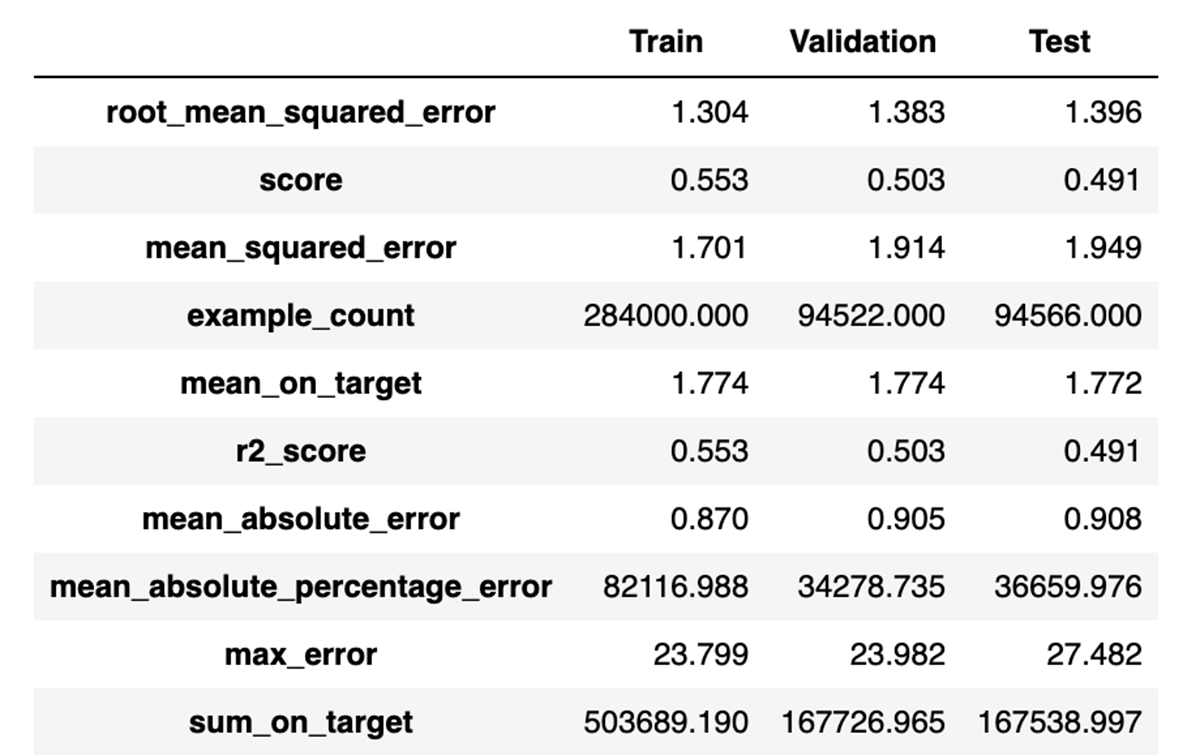
The details of what model worked best don't matter here (congratulations, lightgbm), but this suggests that a decent model could achieve about an RMSE of 1.4 when predicting tips, with R2 of 0.49.
Does this hold up when the model is evaluated on a held-out sample of real data? Yes, as it turns out, this best model built on synthetic data also achieves an RMSE of about 1.52 and R2 of about 0.49. This is not great model performance, but it's not terrible.
In comparison, what would have happened here if starting instead from real data, not synthetic data? Re-run Auto ML, take a couple hours' break, and come back to find:
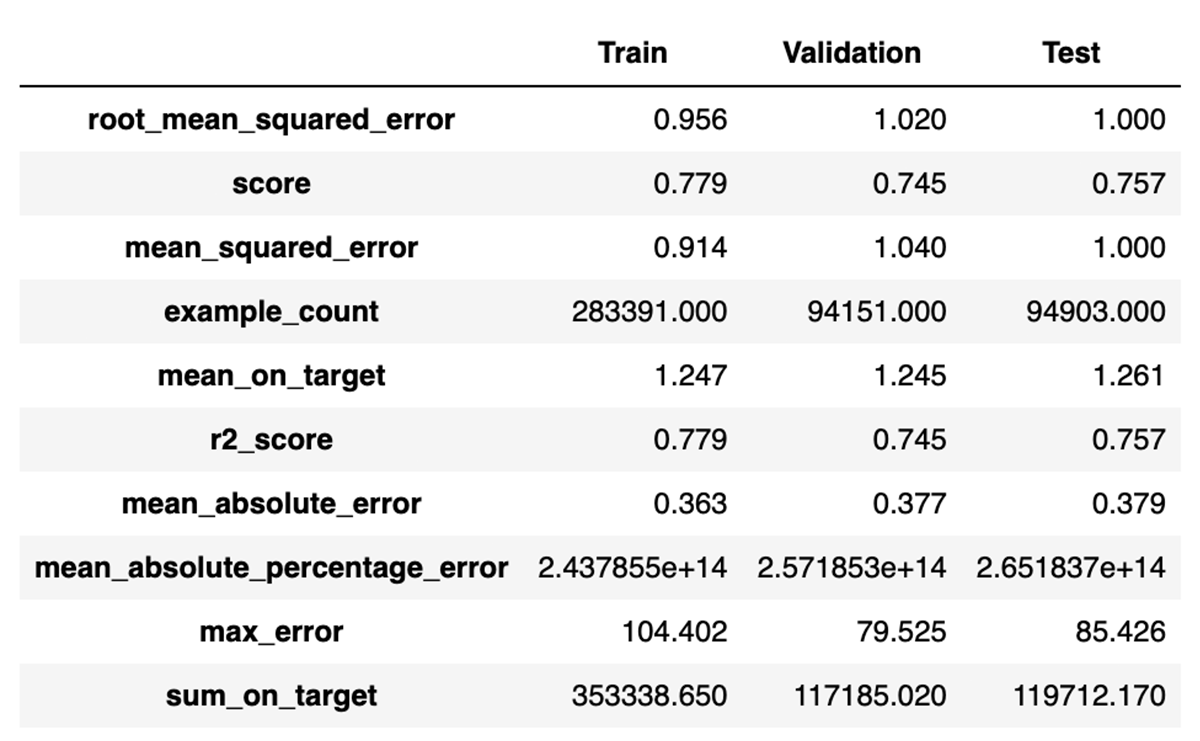
Well, that's significantly better. Further, testing this best model on the same held-out sample of real data gives similar results: RMSE of 0.94 and R2 of 0.78.
In this case, modeling on real data would have produced a significantly more accurate model. Yet something was achieved by modeling on synthetic data. It proved out a viable approach to building models on this data set, without access to the real data. It even produced a passable model, and in other use cases, performance on synthetic data might even be comparable.
Don't underestimate this. This means that the modeling approach could be hashed out by, for example, contractors that can't access sensitive data. The pipeline was the important deliverable rather than the model; the pipeline could then be applied to real data by other teams. For more discussion of dividing up development and deployment of pipelines across teams, see the Big Book of MLops.
Finally, synthetic data can also be a strategy for data augmentation. For teams that do have access to real data, adding synthetic data could slightly improve a model. Without repeating the results, for the curious: this same approach with Auto ML, using a mix of real and synthetic data, yields RMSE of 0.95 and R2 of 0.77. Practically no difference, in this case, but possibly in others.
Summary
The power of generative AI extends beyond funny chats. It can create realistic synthetic business data, which can be a useful stand-in for machine learning teams that are not easily able to secure access to sensitive real data. Tools like SDV can make this process just a few lines of code, and pairs well with Spark, Delta and MLflow for managing the resulting model and data.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.