Introducing MLflow 2.3: Enhanced with Native LLMOps Support and New Features
by Ben Wilson, Harutaka Kawamura, Liang Zhang, Corey Zumar, Jin Zhang and Sunish Sheth
With over 11 million monthly downloads, MLflow has established itself as the premier platform for end-to-end MLOps, empowering teams of all sizes to track, share, package, and deploy models for both batch and real-time inference. MLflow is employed daily by thousands of organizations to drive a diverse range of production machine learning applications, and is actively developed by a thriving community of over 500 contributors from industry and academia.
Today, we are thrilled to unveil MLflow 2.3, the latest update to this open-source machine learning platform, packed with innovative features that broaden its ability to manage and deploy large language models (LLMs) and integrate LLMs into the rest of your ML operations (LLMOps). This enhanced LLM support is delivered through:
- Three brand new model flavors: Hugging Face Transformers, OpenAI functions, and LangChain.
- Significantly improved model download and upload speed to and from cloud services via multi-part download and upload for model files.
Hugging Face transformers support
"The native support of Hugging Face transformers library in MLflow makes it easy to work with over 170,000 free and publicly accessible machine learning models available on the Hugging Face Hub, the largest community and open platform for AI." - Jeff Boudier, Product Director, Hugging Face
The new transformers flavor brings native integration of transformers pipelines, models, and processing components to the MLflow tracking service. With this new flavor, you can save or log a fully configured transformers pipeline or base model, including Dolly, via the common MLflow tracking interface. These logged artifacts can be loaded natively as either a collection of components, a pipeline, or via pyfunc.
When logging components or pipelines with the transformers flavor, a number of validations are automatically performed, ensuring that the pipeline or model that you save is compatible with deployable inference. In addition to the validations, valuable Model Card data is automatically fetched for you and added to the saved model or pipeline artifact. To aid in the usability of these models and pipelines, a model signature inference feature is included to simplify the process of deployment.
An integration with an open-source large language model such as Dolly, hosted on the Hugging Face Hub is as simple as:
With the new MLflow integration with Hugging Face transformers, you can even use the pyfunc version of the model as a lightweight chatbot interface, as shown below.
The MLflow transformers flavor supports automatic signature schema detection and passing of pipeline-specific input formats.
Usage of pyfunc models loaded from transformers pipelines aims to preserve the interface of the underlying pipeline, as shown below:
For each of the pipeline types supported by the transformers package, metadata is collected to ensure that the exact requirements, versions of components, and reference information is available for both future reference and for serving of the saved model or pipeline. Even without an explicitly declared input signature, the signature is inferred based on the representative input example provided during logging.
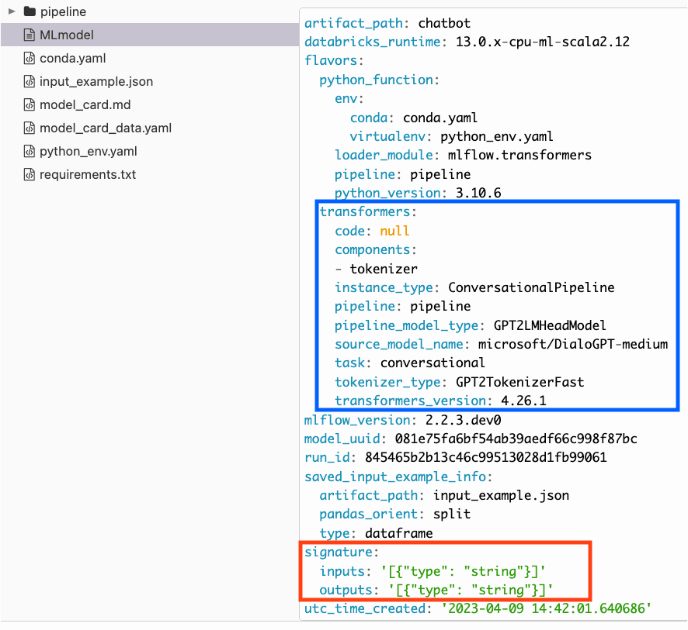
Additionally, the MLflow transformers flavor will automatically pull the state of the Model Card from the Hugging Face Hub upon saving or logging of a model or pipeline. This feature allows for a point-in-time reference of the state of the underlying model information for both general reference and auditing purposes.

With the addition of the transformers flavor, a very widely used and popular package now has first-class support in MLflow. Pipelines that have been retrained and logged with MLflow can easily be submitted back to the Hugging Face Repository, allowing others to use and benefit from novel model architectures to solve complex text-based problems.
OpenAI API support with function-based flavor
The OpenAI Python library provides convenient access to the OpenAI API from applications written in the Python language. It includes a predefined set of classes that map to OpenAI API resources. Usage of these provided classes will dynamically initialize connection, passing of data to, and retrieval of responses from a wide range of model versions and endpoints of the OpenAI API.
The MLflow OpenAI flavor supports:
- Automatic signature schema detection
- Parallelized API requests for faster inference.
- Automatic API request retry on transient errors such as a rate limit error.
Shown below is an example of logging the `openai.ChatCompletion` model and loading it back for inference:
MLflow 2.3 supports logging a function as a model and automatic signature detection from type annotations to simplify logging of a custom model. Shown below is an example of logging a functional OpenAI chat-completion model.
By utilizing the OpenAI flavor with MLflow, you can take full advantage of pre-trained models hosted by OpenAI while leveraging the tracking and deployment capabilities of MLflow.
Remember to manage your OpenAI API keys via environment variables and avoid logging them as run parameters or tags. On Databricks, you may add the API key via Databricks Secret Management to a desired scope with the key name “openai_api_key” like below. MLflow will automatically fetch the secret key from the Databricks Secret store when the OpenAI-flavored model is served in an endpoint.
The secret scope name can be specified with the MLFLOW_OPENAI_SECRET_SCOPE environment variable.
LangChain support
The LangChain flavor in MLflow simplifies the process of building and deploying LLM-based applications, such as question-answering systems and chatbots. Now, you can take advantage of LangChain's advanced capabilities with the streamlined development and deployment support of MLflow.
Here's an example of how to log an LLMChain (English to French translation) as a native LangChain flavor, and perform batch translation of English texts using Spark:
Load the LangChain model for distributed batch inference with Spark UDFs:
Note that this is an initial release of LangChain flavor, with model logging limited to LLMChain. Agent logging and other logging capabilities are in progress and will be added in upcoming MLflow releases.
Get started with MLflow 2.3
We invite you to try out MLflow 2.3 today! To upgrade and use the new features supporting LLMs, simply install the Python MLflow library using the following command:
For a complete list of new features and improvements in MLflow 2.3, see the release changelog. For more information on how to get started with MLflow and for full documentation of the new LLM-based features introduced in MLflow 2.3, see the MLflow documentation.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.