Scale Vision Transformers (ViT) on the Databricks Lakehouse Platform with Spark NLP
Introduction
Back in 2017, a group of researchers at Google AI published a paper that introduced a transformer model architecture that changed all Natural Language Processing (NLP) standards. Although these new Transformer-based models seem to be revolutionizing NLP tasks, their usage in Computer Vision (CV) remained pretty much limited. The field of Computer Vision has been dominated by the usage of convolutional neural networks (CNNs). There are popular architectures based on CNNs (like ResNet). Another team of researchers at Google Brain introduced the “Vision Transformer” (ViT) in June 2021 in a paper titled “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” In this blog post I will demonstrate how to scale out Vision Transformer (ViT) models from Hugging Face and deploy them in production-ready environments for accelerated and high-performance inference, showing how to scale a ViT model by 21x times by using Databricks, Nvidia, and Spark NLP.
As a contributor to the Spark NLP open-source project, I am excited that this library has started supporting end-to-end Vision Transformers (ViT) models. I use Spark NLP and other ML/DL open-source libraries for work daily, and I have deployed a ViT pipeline for a state-of-the-art image classification task and to provide in-depth comparisons between Hugging Face and Spark NLP.
There is a longer version of this article, published as 3 part series on Medium:
The notebooks, logs, screenshots, and spreadsheets for this project are provided on GitHub.
Benchmark setting
Data set and models
- Dataset: ImageNet mini: sample (>3K) — full (>34K)
- I have downloaded ImageNet 1000 (mini) dataset from Kaggle
- I have chosen the train directory with over 34K images and called it imagenet-mini since all I needed was enough images to do benchmarks that take longer. - Model: The “vit-base-patch16–224” by Google.
We will be using this model from Google hosted on Hugging Face - Libraries: Transformers & Spark NLP
The Code
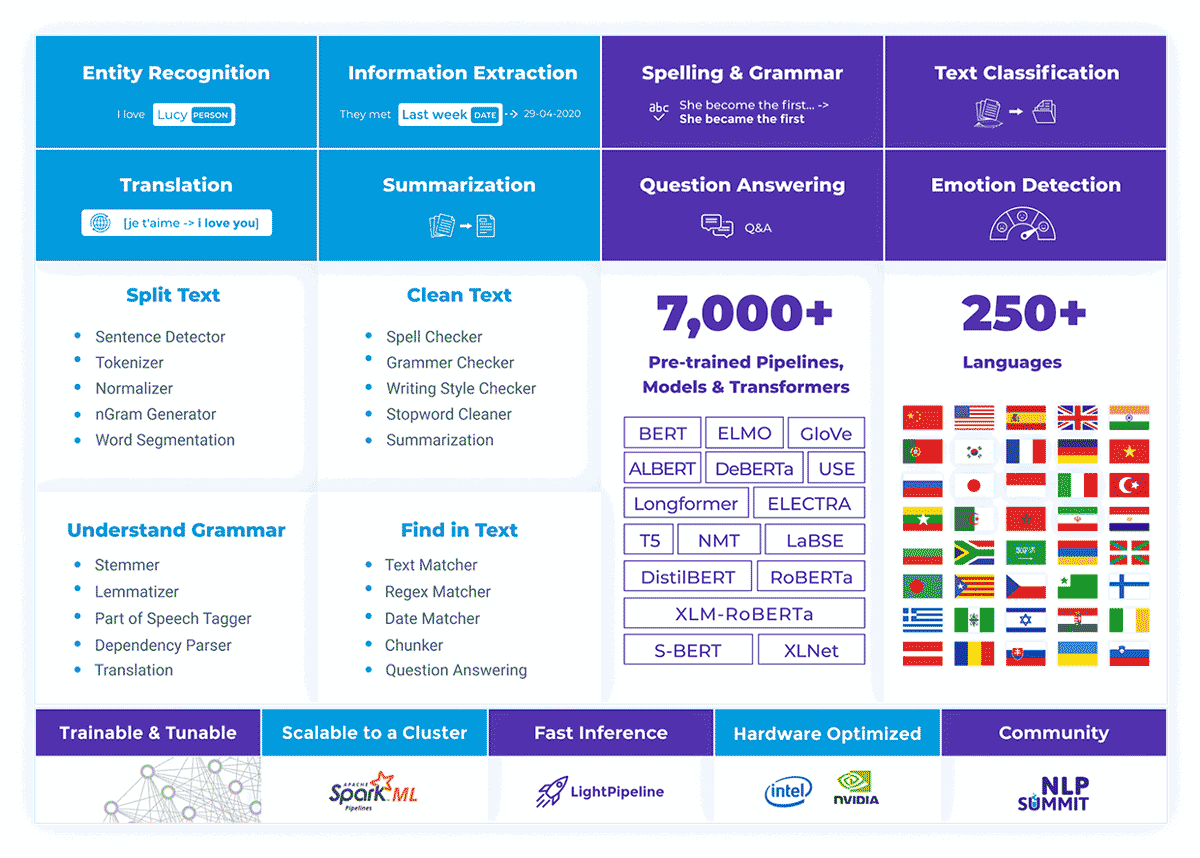
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark™. It provides simple, performant & accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 7000+ pretrained pipelines and models in more than 200+ languages. It also offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Word and Sentence Embeddings, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation (+180 languages), Summarization & Question Answering, Text Generation, Image Classification (ViT), and many more NLP tasks.
Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Google T5, MarianMT, GPT2, and Vision Transformer (ViT) not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.
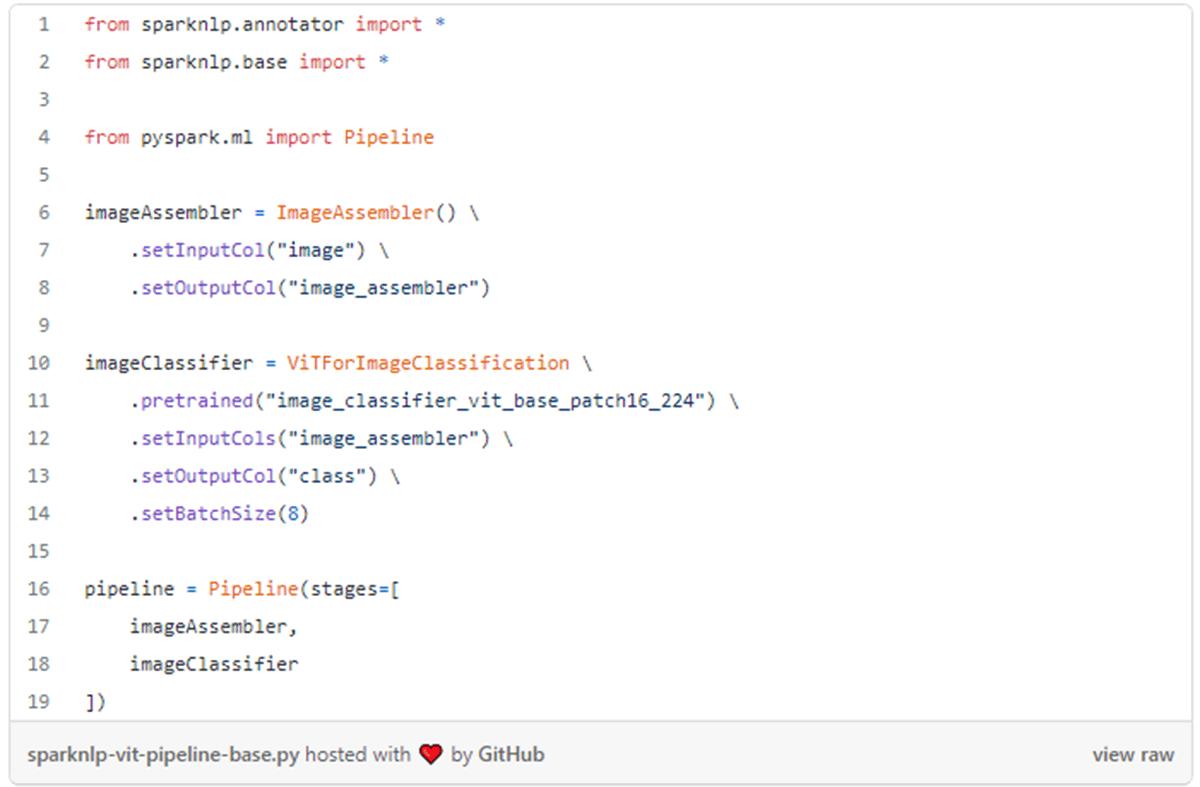
Once you have trained a model via ViT architecture, you can pre-train and fine-tune your transformer just as you do in NLP. Spark NLP has ViT features for Image Classification added in the recent 4.1.0 release. The feature is called ViT For Image Classification. It has over 240 pre-trained models ready to go, and a simple code to use this feature in Spark NLP looks like this:
Single-node comparison – Spark NLP is not just for clusters!
Single node Databricks CPU cluster configuration
Databricks offers a “Single Node” cluster type when creating a cluster suitable for those who want to use Apache Spark with only 1 machine or use non-spark applications, especially ML and DL-based Python libraries. Here is what the cluster configurations look like for my Single Node Databricks (only CPUs) before we start our benchmarks:
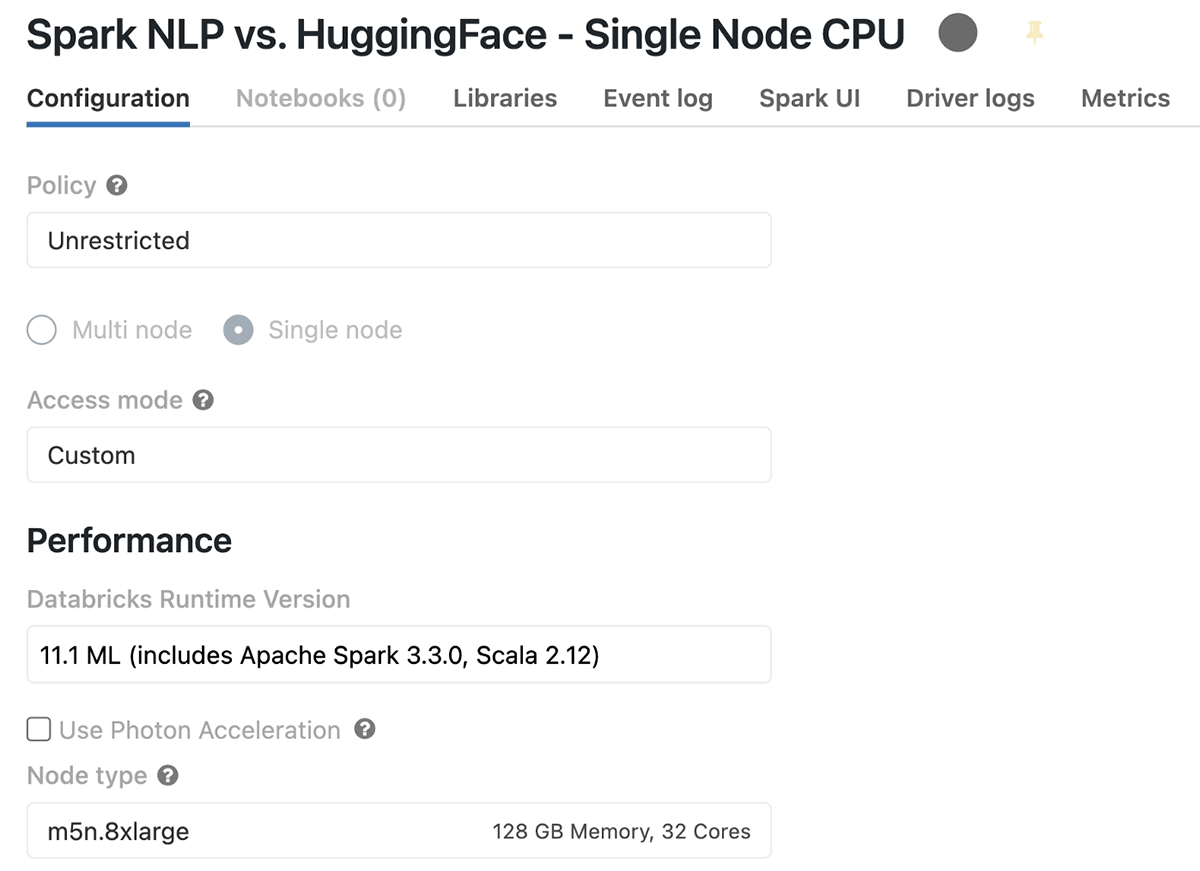
The summary of this cluster that uses m5n.8xlarge instance on AWS is that it has 1 Driver (only 1 node), 128 GB of memory, 32 Cores of CPU, and it costs 5.71 DBU per hour.
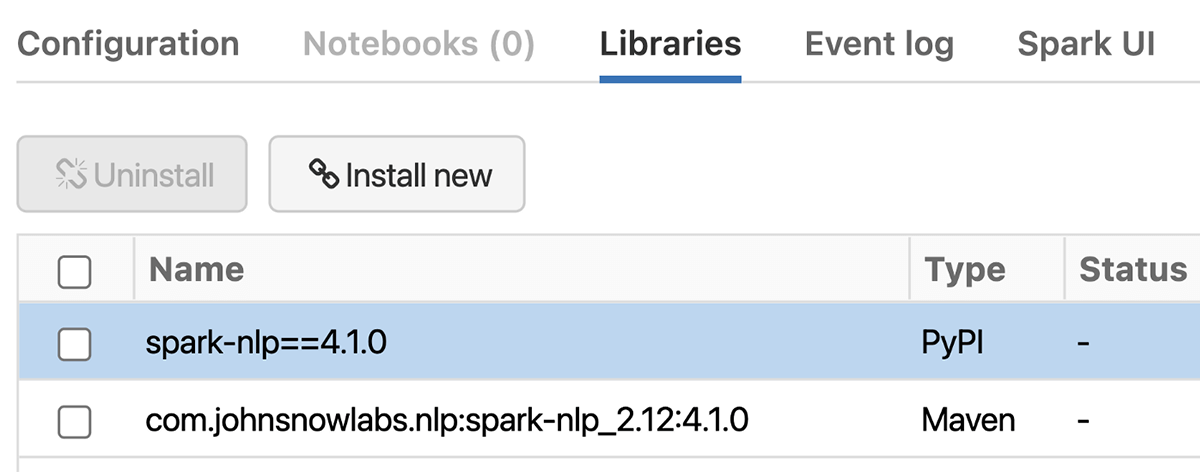
First, let’s install Spark NLP in your Single Node Databricks CPUs. In the Libraries tab inside your cluster, you need to follow these steps:
- Install New -> PyPI -> spark-nlp==4.1.0 -> Install
- Install New -> Maven -> Coordinates -> com.johnsnowlabs.nlp:spark-nlp_2.12:4.1.0 -> Install
- Will add `TF_ENABLE_ONEDNN_OPTS=1` to `Cluster->Advanced Options->Spark->Environment variables` to enable oneDNN.
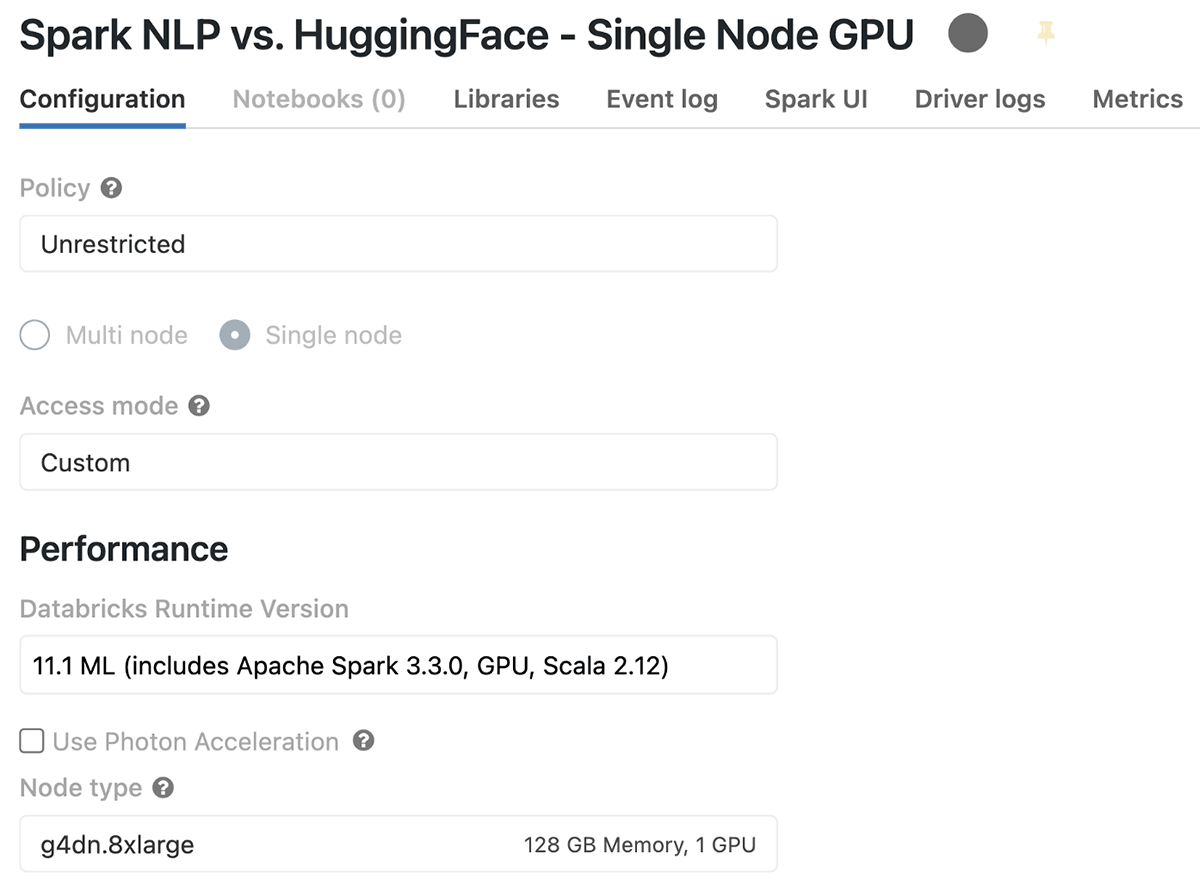
Single node Databricks GPU cluster configuration
Let’s create a new cluster, and this time we are going to choose a runtime with GPU, which in this case is called 11.1 ML (includes Apache Spark 3.3.0, GPU, Scala 2.12), and it comes with all required CUDA and NVIDIA software installed. The next thing we need is to also select an AWS instance that has a GPU, and I have chosen a g4dn.8xlarge cluster that has 1 GPU and the same number of cores/memory as the other cluster. This GPU instance comes with a Tesla T4 and 16 GB memory (15 GB usable GPU memory).
The setup of libraries for the GPU cluster is similar to the CPU case. The only difference is the use of “spark-nlp-gpu” from Maven, i.e., “com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:4.1.0” instead of “com.johnsnowlabs.nlp:spark-nlp_2.12:4.1.0”.
Benchmarking
Now that we have Spark NLP installed on our Databricks single-node cluster, we can repeat the benchmarks for sample and full datasets on both CPU and GPU. Let’s start with the benchmark on CPUs first over the sample dataset. It took almost 12 minutes (1072 seconds) to finish processing 34K images, with batch size 16, and predicting their classes. Benchmarking for optimal batch size is described in the original revision of this post.
On a larger dataset, it took almost 7 and a half minutes (435 seconds) to finish predicting classes for over 34K images with a batch size of 8. If we compare the results from our benchmarks on a single node with CPUs and a single node that comes with 1 GPU we can see that the GPU node here is the winner:
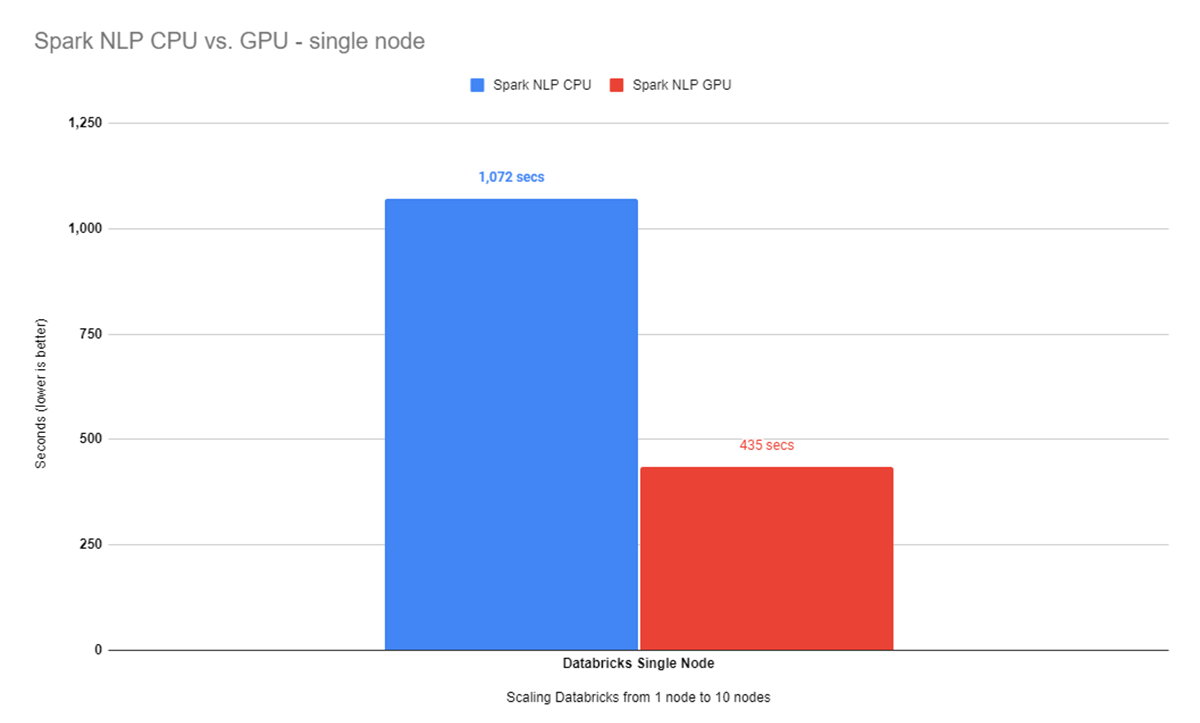
This is great! We can see Spark NLP on GPU is around 2.5x times faster than CPUs even with oneDNN enabled.
In this post's extended version, we benchmarked the impact of using the oneDNN library for modern Intel architecture. OneDNN improves results on CPUs between 10% to 20%.
Scaling beyond a single machine
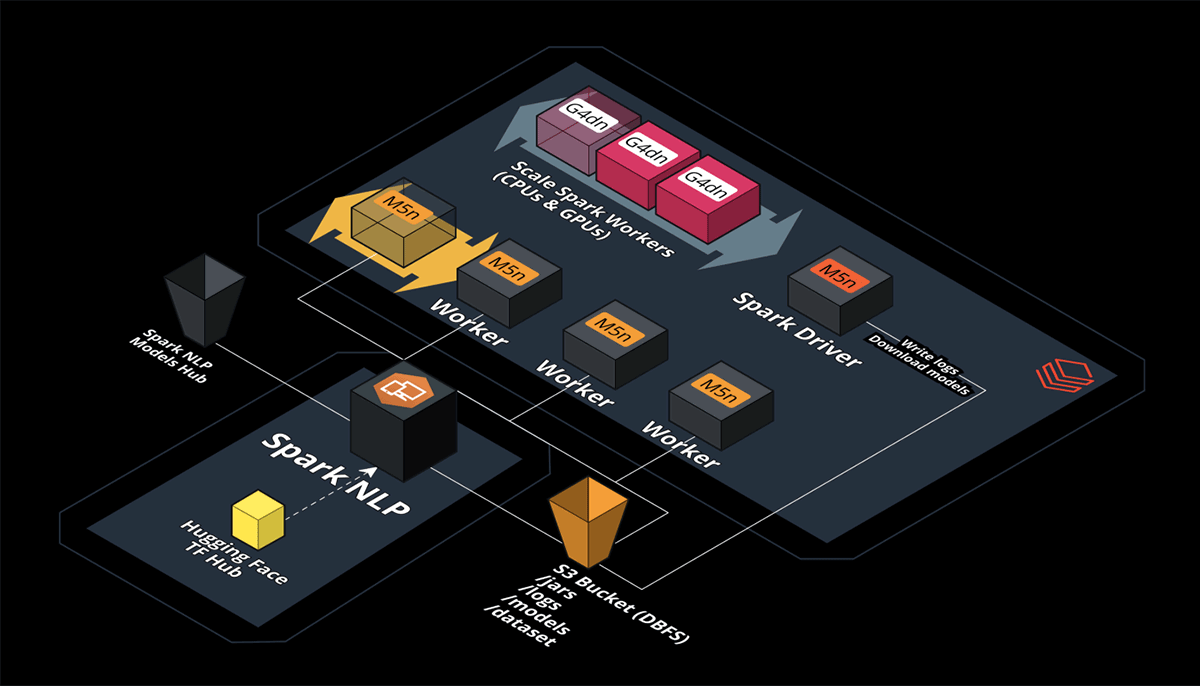
Spark NLP is an extension of Spark ML. It scales natively and seamlessly over all supported platforms by Apache Spark, including Databricks. Zero code changes are needed! Spark NLP can scale from a single machine to an infinite number of machines without changing anything in the code!
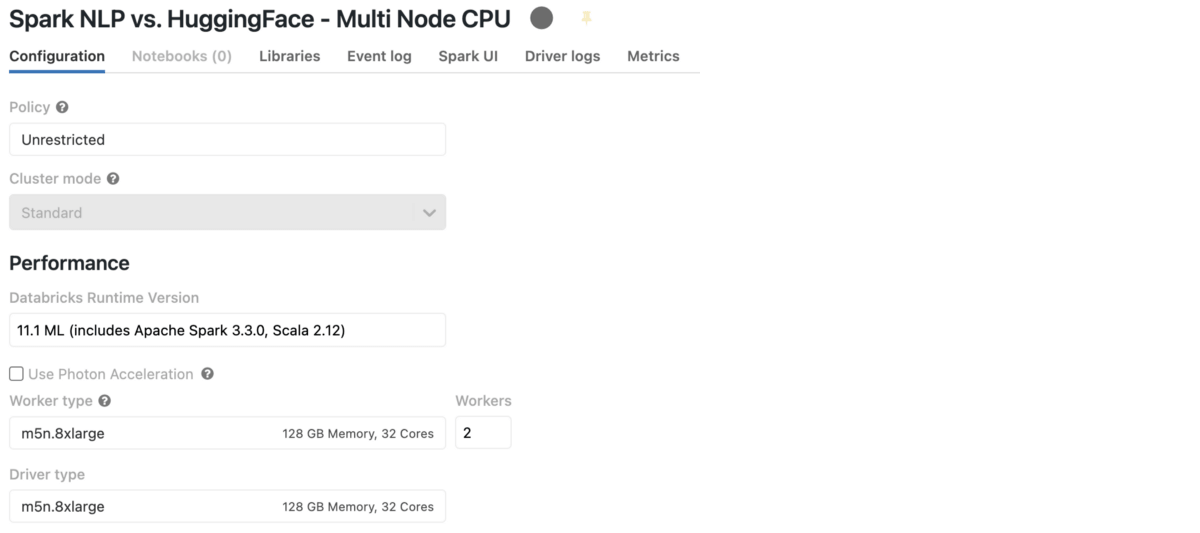
Databricks Multi-Node with CPUs on AWS
Let’s create a cluster and this time we choose Standard inside Cluster mode. This means we can have more than 1 node in our cluster, which in Apache Spark terminology means 1 Driver and N number of Workers (Executors).

We also need to install Spark NLP in this new cluster via the Libraries tab. You can follow the steps I mentioned in the previous section for Single Node Databricks with CPUs. As you can see, I have chosen the same CPU-based AWS instance I used to benchmark both Hugging Face and Spark NLP so we can see how it scales out when we add more nodes.
This is what our Cluster configurations look like:
I will reuse the Spark NLP pipeline I used in previous benchmarks (no need to change any code), and I will only use the larger dataset with 34K images. We have gradually scaled the number of workers from 2 to 10.
Databricks Multi-Node with GPUs on AWS
Having a GPU-based multi-node Databricks cluster is pretty much the same as having a single-node cluster. The only difference is choosing Standard and keeping the same ML/GPU Runtime with the same AWS Instance specs we chose in our benchmarks for GPU on a single node.
We also need to install Spark NLP in this new cluster via the Libraries tab. Same as before, you can follow the steps I mentioned in Single Node Databricks with a GPU.
Just as a reminder, each AWS instance (g4dn.8xlarge) has 1 NVIDIA T4 GPU 16GB (15GB usable memory).
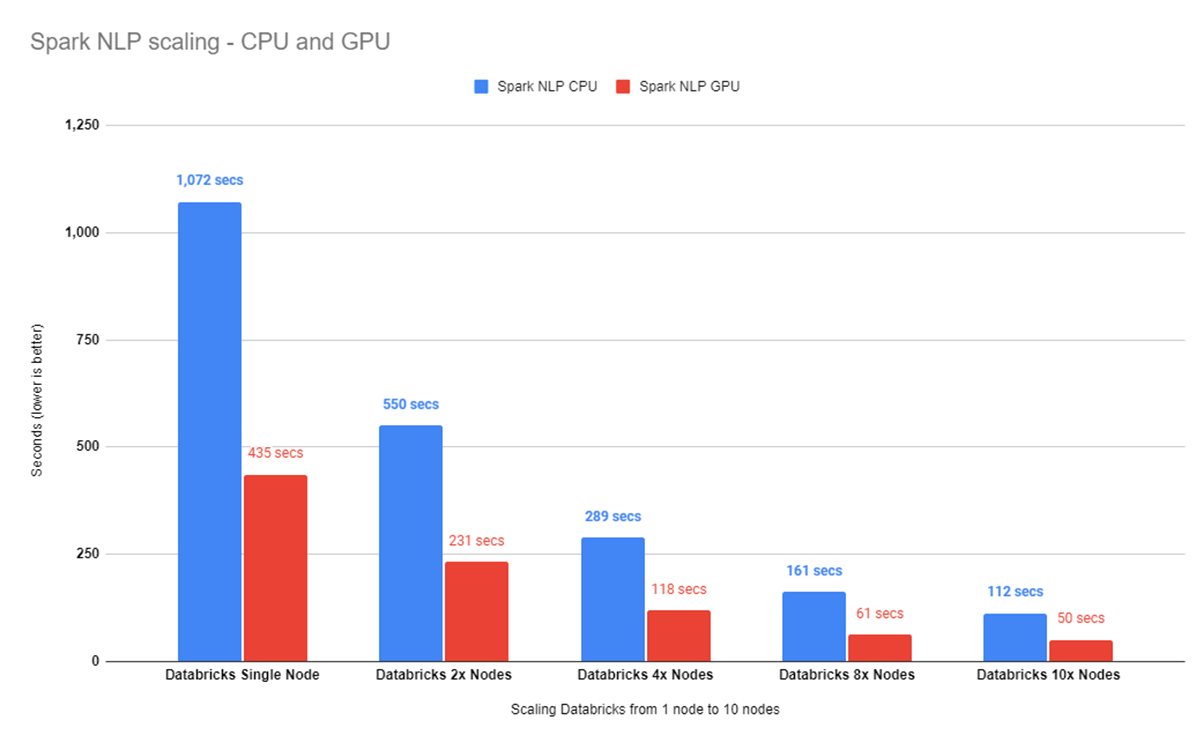
Running the 34K images benchmark for 2, 4, 8, and 10 Databricks nodes takes 112 seconds on the CPU (versus 1,072 seconds on the single node). The GPU cluster scales from 435 seconds to 50 seconds.
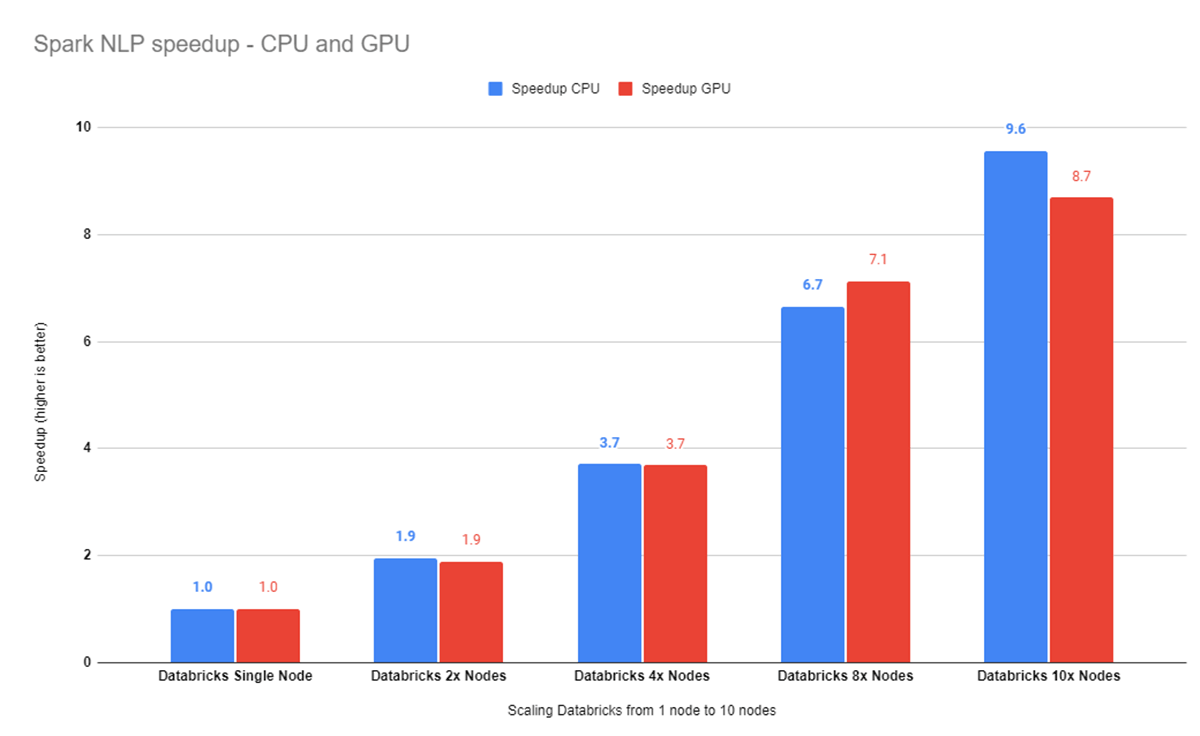
Using ten nodes cluster achieves 96% efficiency, i.e., it is 9.6x faster than running on a single-node setup. The ten-node GPU cluster runs 8.7x faster.
Conclusions
Spark NLP is 21.4x faster on a 10-node GPU cluster than on a single-node CPU cluster, without changing a single line in the python code.
Spark NLP is fully integrated with the Databricks platform. Give it try!
- Visit web https://johnsnowlabs.com for more information.
- Installation instructions are available here.
- Join John Snow Labs’ Slack channel to get help.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.