7x Faster Medical Image Ingestion with Python Data Source API
Leverage industry standard libraries, pydicom and zipfile with Python Data Source API to accelerate DICOM data ingestion pipeline
by Douglas Moore and Allison Wang
- Healthcare and life sciences organizations handle diverse data formats beyond structured data, like DICOM imaging, lab instruments, genomic outputs, and biomedical files, often stored in zipped format, posing challenges for traditional platforms.
- The Python Data Source API integrates healthcare Python libraries into Spark, allowing single-step processing of compressed files instead of complex ETL pipelines with unzipping and UDFs.
- Using the Python Data Source API achieves 7x faster processing by eliminating temporary files (57x savings) through in-memory operations and minimizing I/O operations.
The Healthcare Data Challenge: Beyond Standard Formats
Healthcare and life sciences organizations deal with an extraordinary diversity of data formats that extend far beyond traditional structured data. Medical imaging standards like DICOM, proprietary laboratory instruments, genomic sequencing outputs, and specialized biomedical file formats represent a significant challenge for traditional data platforms. While Apache Spark™ provides robust support for approximately 10 standard data source types, the healthcare domain requires access to hundreds of specialized formats and protocols.
Medical images, encompassing modalities like CT, X-Ray, PET, Ultrasound, and MRI, are essential to many diagnostic and treatment processes in healthcare in specialties ranging from orthopedics to oncology to obstetrics. The challenge becomes even more complex when these medical images are compressed, archived, or stored in proprietary formats that require specialized Python libraries for processing.
DICOM files contain a header section of rich metadata. There are over 4200 standard defined DICOM tags. Some customers implement custom metadata tags. The “zipdcm” data source was built to speed the extraction of these metadata tags.
The Problem: Slow Medical Image Processing
Healthcare organizations often store medical images in compressed ZIP archives containing thousands of DICOM files. Processing these archives at scale typically requires multiple steps:
- Extract ZIP files to temporary storage
- Process individual DICOM files using Python libraries like pydicom
- Load results into Delta Lake for analysis
Databricks has released a Solution Accelerator, dbx.pixels, which makes integrating hundreds of imaging formats easy at scale. However, the process can still be slow due to the disk I/O operations and temporary file handling.
The Solution: Python Data Source API
The new Python Data Source API solves this by enabling direct integration of healthcare-specific Python libraries into Spark's distributed processing framework. Instead of building complex ETL pipelines to first unzip files and then processing them with User Defined Functions (UDFs), you can process compressed medical images in a single step.
A custom data source, implemented using Python Data Source API, combining ZIP file extraction with DICOM processing delivers impressive results: 7x faster processing compared to the traditional approach.
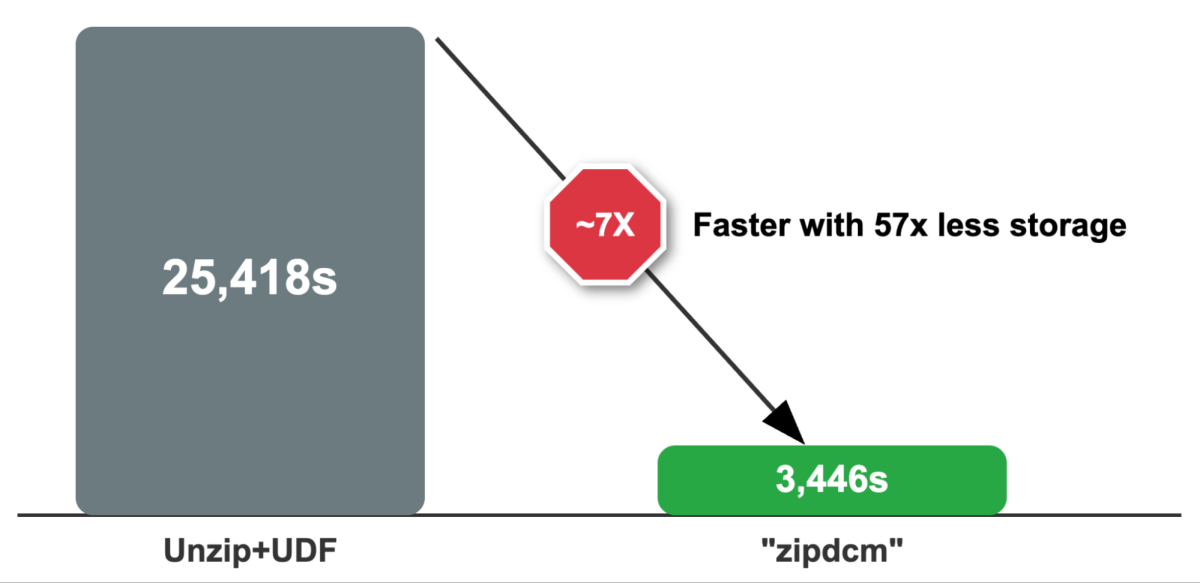
”zipdcm” reader processed 1,416 zipfile archives containing 107,000+ total DICOM files at 2.43 core seconds per DICOM file. Independent testers reported 10x faster performance. The cluster used had two worker nodes, 8 v-cores each. The wall clock time to run the ”zipdcm” reader was only 3.5 minutes.
By leaving the source data zipped, and not expanding the source zip archives, we realized a remarkable (4TB unzipped vs 70GB zipped) 57 times lower cloud storage costs.
Implementing the Zipped DICOM Data Source
Here's how to build a custom data source that processes ZIP files containing DICOM images found on github
The crux of reading DICOM files in a Zip file (original source):
Alter this loop to process other types of files nested inside a zip archive, zip_fp is the file handle of the file inside the zip archive. With the code snippet above, you can start to see how individual zip archive members are individually addressed.
A few important aspects of this code design:
- The DICOM metadata is returned via
yieldwhich is a memory efficient technique because we’re not accumulating the entirety of the metadata in memory. The metadata of a single DICOM file is just a few kilobytes. - We discard the pixel data to further trim down the memory footprint of this data source.
With additional modifications to the partitions() method you can even have multiple Spark tasks operate on the same zipfile. For DICOMs, typically, zip archives are used to keep individual slices or frames from a 3D scan all together in one file.
Overall, at a high level, the <name_of_data_source>) as shown in the code snippet below:
Where the data folder looks like (the data source can read bare and zipped dcm files):
Why 7x Faster?
A number of factors contribute to 7x faster improvement by implementing a custom data source using Python Data Source APi. They include the following:
- No temporary files: Traditional approaches write decompressed DICOM files to disk. The custom data source processes everything in memory.
- Reduction in # files to open: In our dataset [DOI: 10.7937/cf2p-aw56]1 from The Cancer Imaging Archive (TCIA), we found 1,412 zip files containing 107,000 individual DICOM and License text files. This is a 100x expansion in the number of files to open and process.
- Partial reads: Our DICOM metadata zipdcm data source discards the larger image data related tags
"60003000,7FE00010,00283010,00283006") - Lower IO to and from storage: Before, with unzip, we had to write out 107,000 files, for a total of 4TB of storage. The compressed data downloaded from TCIA was only 71 GB. With the
zipdcmreader, we save 210,000+ individual file IOs. - Partition‑Aware Parallelism: Because the iterator exposes both top‑level ZIPs and the members inside each archive, the data source can create multiple logical partitions against a single ZIP file. Spark therefore spreads the workload across many executor cores without first inflating the archive on a shared disk.
Taken together, these optimizations shift the bottleneck from disk and network I/O to pure CPU parsing, delivering an observed 7× reduction in end‑to‑end runtime on the reference dataset while keeping memory usage predictable and bounded.
Beyond Medical Imaging: The Healthcare Python Ecosystem
The Python Data Source API opens access to the rich ecosystem of healthcare and life sciences Python packages:
- Medical Imaging: pydicom, SimpleITK, scikit-image for processing various medical image formats
- Genomics: BioPython, pysam, genomics-python for processing genomic sequencing data
- Laboratory Data: Specialized parsers for flow cytometry, mass spectrometry, and clinical lab instruments
- Pharmaceutical: RDKit for chemical informatics and drug discovery workflows
- Clinical Data: HL7 processing libraries for healthcare interoperability standards
Each of these domains has mature, battle-tested Python libraries that can now be integrated into scalable Spark pipelines. Python's dominance in healthcare data science finally translates to production-scale data engineering.
Getting Started
The blog post discusses how the Python Data Source API, combined with Apache Spark, significantly improves medical image ingestion. It highlights a 7x acceleration in DICOM file indexing and hashing, processing over 100,000 DICOM files in under four minutes, and reducing storage by 57x. The market for radiology imaging analytics is valued at over $40 billion annually, making these performance gains an opportunity to help lower cost while speeding automation of workflows. The authors acknowledge the creators of the benchmark dataset used in their study.
Rutherford, M. W., Nolan, T., Pei, L., Wagner, U., Pan, Q., Farmer, P., Smith, K., Kopchick, B., Laura Opsahl-Ong, Sutton, G., Clunie, D. A., Farahani, K., & Prior, F. (2025). Data in Support of the MIDI-B Challenge (MIDI-B-Synthetic-Validation, MIDI-B-Curated-Validation, MIDI-B-Synthetic-Test, MIDI-B-Curated-Test) (Version 1) [Dataset]. The Cancer Imaging Archive. https://doi.org/10.7937/CF2P-AW56
Try out the data sources (“fake”, “zipcsv” and “zipdcm”) with supplied sample data, all found here: https://github.com/databricks-industry-solutions/python-data-sources
Reach out to your Databricks account team to share your use case and strategize on how to scale up the ingestion of your favorite data sources for your analytic use cases.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.