Adaptive Query Execution in Structured Streaming
Improving ForeachBatch Sink in Project Lightspeed
by Steven Chen, MaryAnn Xue and Jungtaek Lim
In Databricks Runtime, Adaptive Query Execution (AQE) is a performance feature that continuously re-optimizes batch queries using runtime statistics during query execution. Starting from Databricks Runtime 13.1, real-time streaming queries that use the ForeachBatch Sink will also leverage AQE for dynamic re-optimizations as part of Project Lightspeed.
Limitations with Static Planning and Statistics
At Databricks, Structured Streaming handles petabytes of real-time data daily. The ForeachBatch streaming sink, used by over 40% of customers, often incorporates the most resource-intensive operations, such as joins and Delta MERGE with large volumes of data. The resulting multi-staged execution plans have the most potential to be re-optimized by AQE.
Streaming queries have relied on static query planning and estimated statistics, leading to several known issues previously seen in batch queries, including poor physical strategy decisions and skewed data distributions that degrade performance.
Application of Dynamic Optimizations
To address those challenges, we exploit the runtime statistics collected during the micro-batch execution of the ForeachBatch Sink for dynamic optimizations. Adaptive query replanning will be triggered independently on each micro-batch because the characteristics of the data may change over time across different micro-batches.
The effect of AQE is isolated on stateless operators and is applied to the micro-batch DataFrame within the ForeachBatch callable function. Operators directly applied to the streaming DataFrame before invoking ForeachBatch are executed in a different query plan without AQE because those operators could be stateful. Separation of execution prevents AQE repartitioning on stateful operators, which can take away locality and cause correctness issues.
For Photon-enabled clusters, each micro-batch from a stateless query is executed with a cohesive query plan practically identical to that of a batch Photon query. This design allows the widest range of logical and physical optimizations. AQE will take effect for most stateless Photon-enabled queries using the ForeachBatch Sink.
Generally, AQE will be most effective when transformations can be applied within the ForeachBatch Sink. The sample code below shows two semantically identical streaming queries. The second query is recommended for potentially better AQE coverage since the join is moved inside the ForeachBatch function.
Interpretation of Query Plans with AQE
Consider a simplified example of a streaming Delta MERGE query which is used for upserting real-time data into a Delta table:
Scanning for matches is often the most costly part of a Delta Merge query. Let’s examine the Spark UI snippets of a query plan that executes the matching process on a sample micro-batch.
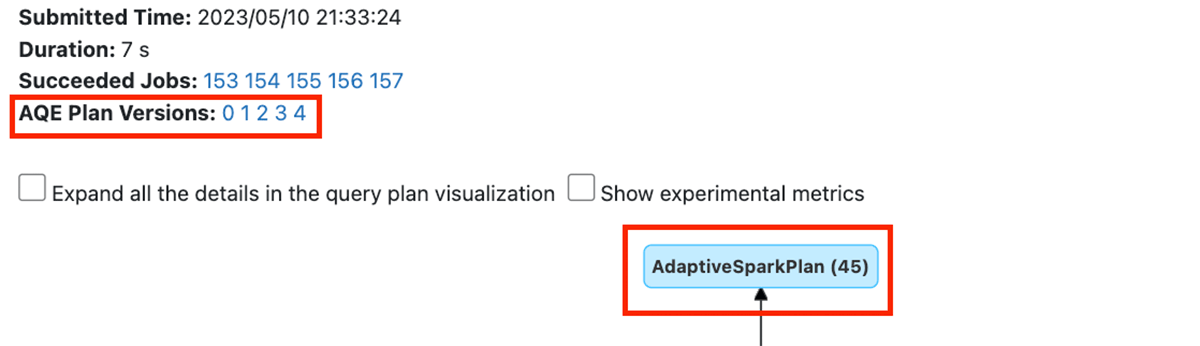
First, AQE Plan Versions contain links that show how the plan evolved during execution. The AdaptiveSparkPlan root node indicates that AQE was applied to this query plan because it contained at least one shuffle.
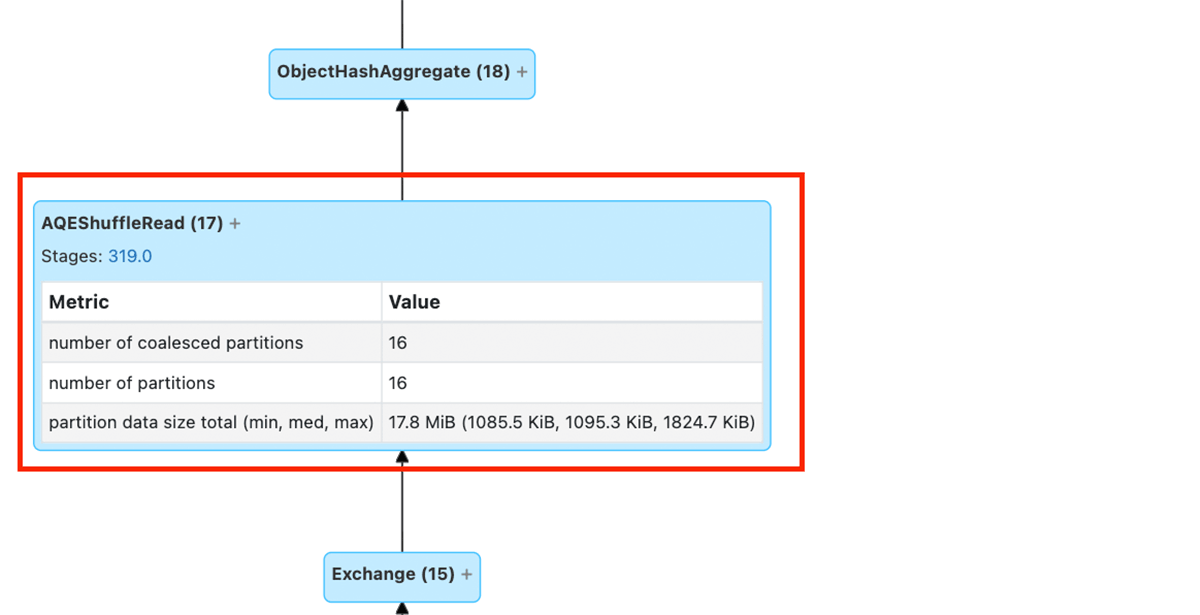
The snippet below shows that AQE applied dynamic coalescing of small partitions in this particular example.
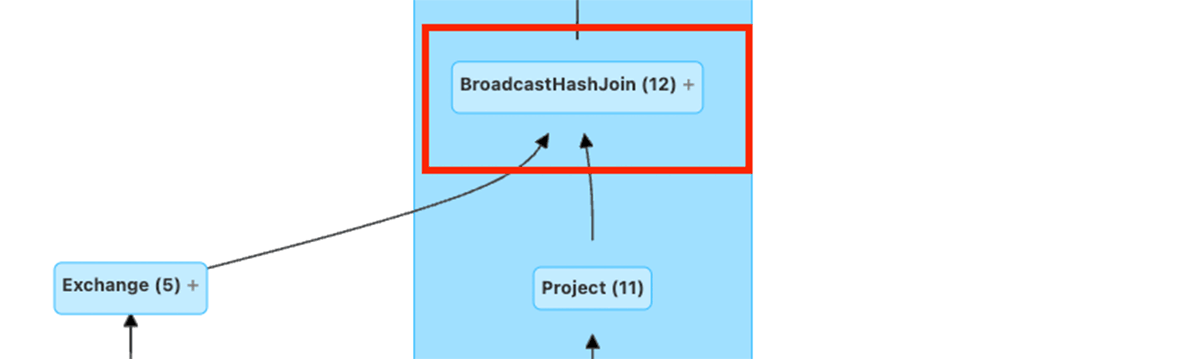
Comparing plan versions in this example also shows that AQE dynamically switched from a SortMergeJoin to a BroadcastHashJoin, which can significantly speed up the join.
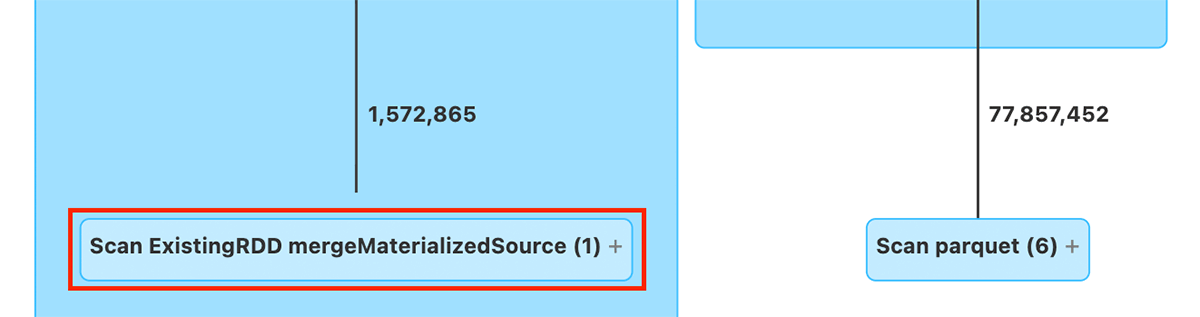
As shown below, one of the leaf nodes of the query plan is an RDD Scan which reads the materialized micro-batch data from the streaming subplan which may contain stateful operators.
If the same query was executed in Photon, instead of an RDD Scan, the execution plan would incorporate all downstream operators, including the data stream source.
Performance Results
Leveraging AQE, stateless benchmark queries bottlenecked by expensive joins and aggregations typically experienced a speedup ranging from 1.2x to 2x, with one query that had particularly poor static planning experiencing a 16x speedup. Partition size re-optimizations and dynamic join strategy selections were observed in the speedup queries. As expected, AQE did not impact the performance for stateful queries and queries with few transformations.
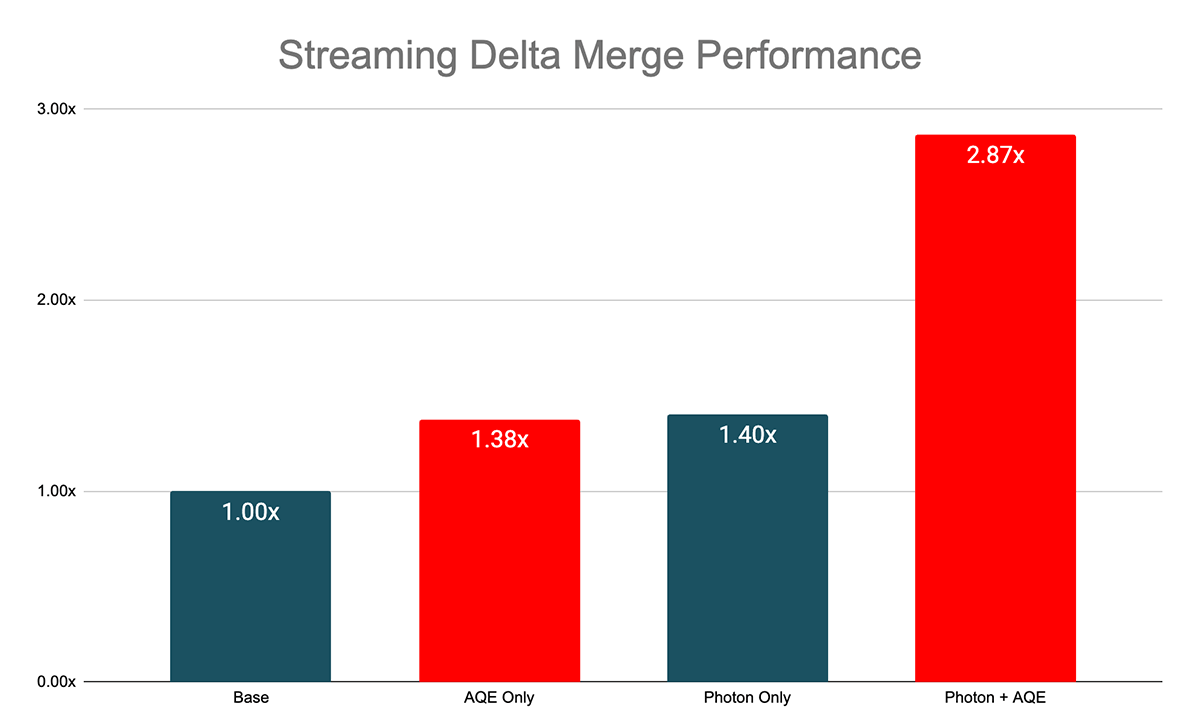
The additional dynamic filters enabled by AQE and join re-optimizations can be particularly effective with Delta MERGE, which is a common streaming use case. As shown in the chart below, internal benchmarks demonstrated a median 1.38x speedup with just AQE and 2.87x speedup if AQE is enabled along with the Photon engine.
Looking Forward
AQE in streaming will be enabled by default in Runtime 13.1 for non-Photon clusters and in Runtime 13.2 for Photon clusters. With AQE in ForeachBatch, customers can now benefit from the same dynamic optimizations used in batch queries for their streaming workloads. Also, look forward to the coming improvements to AQE, including Adaptive Join Fallback and other AI-powered features enabled by AQE.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.