Announcing General Availability of Python Data Source API
Unlock Custom Data Connectivity with the Simplicity of Python
by Allison Wang, Jules Damji, Ryan Nienhuis and Huanli Wang
- Developers can now build custom Spark connectors using Python, integrating with diverse data sources through the rich Python ecosystem.
- The Python Data Source API supports batch and streaming workloads, enabling real-time data ingestion pipelines across structured and unstructured sources and writing to destinations.
- With Databricks’ Unity Catalog integration, developers can govern, secure, and operationalize external data with data lineage, access control, and auditability.
- Use Declarative Pipeline sinks, implemented as a Python data source, to stream records to external services with Declarative Pipelines.
We are excited to announce the General Availability (GA) of PySpark’s Data Source API for Apache Spark™ 4.0 on Databricks Runtime (DBR) 15.4 LTS and above. This powerful feature allows developers to build custom data connectors with Spark using pure Python. It simplifies integration with external and non-Spark-native data sources, opening new possibilities for data pipelines and machine learning workflows.
Why This Matters
Today, data is ingested from myriad sources, some structured, some unstructured, and some multi-modal data like images and videos. Spark natively supports Data Source v1 (DSv1) and Data Source v2 (DSv2) standard formats like Delta, Iceberg, Parquet, JSON, CSV, and JDBC. However, it does not provide built-in support for many other sources, such as Google Sheets, REST APIs, HuggingFace datasets, tweets from X, or proprietary internal systems. While DSv1/DSv2 can technically be extended to implement these sources, the process is overly complex and often unnecessary for lightweight use cases.
What if you need these other custom data sources to read from or write to for your use case, or what if your ETL pipeline for a machine learning use case needs to consume this data to train a model? That’s exactly the gap the Python Data Source API fills.
This blog will explore how you can write custom data sources in PySpark. Using this API, you can easily bring diverse datasets not built into Spark into your data processing pipelines for your specific use case. We will also explore some examples of custom data sources. But first, let’s understand why and what.
What is the Python Data Source API?
Inspired by people’s love for writing in Python and the ease of installing packages with pip, the Python Data Source API makes it easy to build custom readers and writers for Spark using Python. This API unlocks access to any data source, eliminating the need for complex DSv1 and DSv2 development or Spark internals knowledge that was previously required for custom connectors.
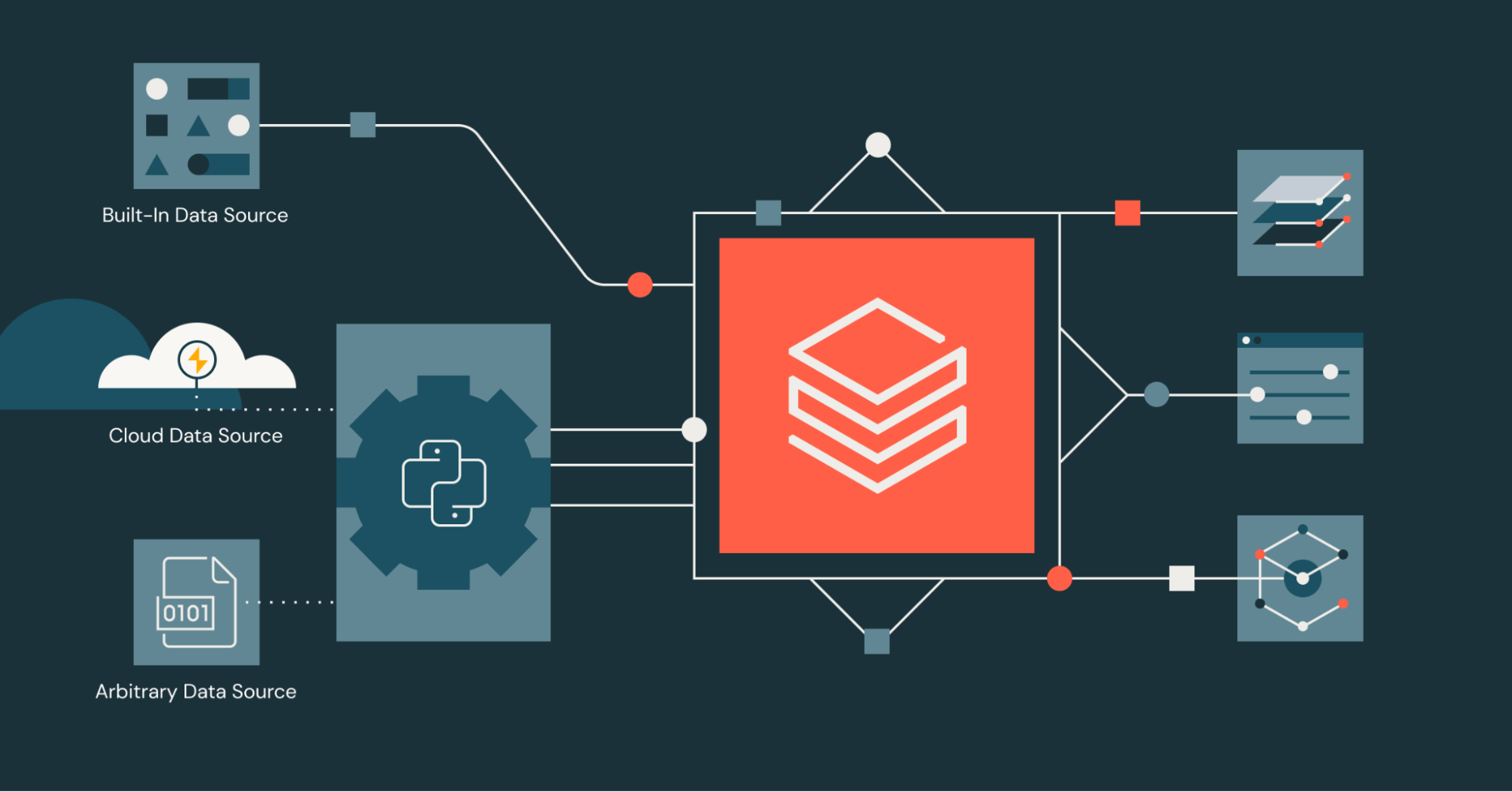
What are the Key Features and Benefits?
There are several key benefits to using Python data sources.
1. Pure Python Implementation
Consider the pythonic feel first. The Python Data Source API removes the barriers of a more complicated JVM-based connector development. Data engineers building complex ETL pipelines using myriad data sources in Python can now leverage their existing Python skills to create custom connectors without diving into Spark's internal complexities.
2. Support for Both Batch and Streaming Operations
The API supports both batch and streaming reads, allowing you to build connectors that handle multiple data access patterns:
- Batch Reading: Pull data from APIs, databases, or other sources in a single operation
- Stream Reading: Continuously ingest data from event-based or real-time sources
- Batch and Stream writing: Write to the data sink, including Declarative Pipeline sinks.
3. Accessibility from SQL
Like any supported data source in Spark SQL, you can equally and easily access your custom Python Data Source from Spark SQL. Once a data source has been loaded as a DataFrame, you can save it as a temp view or a persistent Unity Catalog managed table. This allows you to incorporate your custom data sources into your SQL analytics downstream.
4. Simplified Integration with External Services
You can easily connect to external systems by passing in your custom options, like API keys, endpoints, or other configs, using the DataFrame API. This gives you complete control over how your connector behaves. See the real-world examples below for details.
5. Community-Driven Connector Ecosystem
Since its preview release, the community has already begun building valuable connectors with the Python Data Source API :
- Example Connectors: Reference implementations for REST APIs, CSV variants, and more (GitHub repository)
- HuggingFace Connector: Direct access to datasets from HuggingFace (GitHub repository)
6. Speed without the complexity
The Python Data Source API is designed not just for ease of use, but also for speed. It’s built on Apache Arrow, an in-memory data format optimized for fast data processing. This means your data can move between your custom connector and Spark with minimal overhead, making ingestion and writing much faster.
Python Data Source Real-World Use Cases
Let's explore real-world use cases for feeding data into your pipelines using Python Data Sources.
Custom API Integrations
First, let’s examine how you can benefit from integrating REST APIs.
Many data engineering teams are building custom connectors to pull data from REST APIs and use it in downstream transformations. Instead of writing custom code to fetch the data, save it to disk or memory, and then load it into Spark, you can use the Python Data Source API to skip those steps.
With a custom data source, you can read data directly from an API into a Spark DataFrame, and no intermediate storage is needed. For example, here’s how to fetch the full output from a REST API call and load it straight into Spark.
The REST API data source and its full implementation are here as a reference example.
Unity Catalog Integration
The second integration is with data catalogs. More developers in the enterprise are turning toward data catalogs, such as Unity Catalog, to store their AI and Data assets in a central repository for central data governance and security. As this second trend continues, your data pipeline jobs should be able to read and write to these data assets in a secure and controlled manner.
You can read data directly from these custom data sources and write to Unity Catalog tables, bringing governance, security, and discoverability to data from any source:
This integration ensures that data from your specialized sources can be properly governed and secured through Unity Catalog.
Machine Learning Pipeline Integration
The third integration is with machine learning external datasets. Data scientists use the Python Data Source API to directly connect to specialized Machine Learning (ML) datasets and model repositories. HuggingFace has a ton of datasets explicitly curated for training and testing classical ML models.
To fetch this dataset as a Spark DataFrame, you can use the HuggingFace connector. This connector leverages the power of the Python Data Source API to easily fetch ML assets that can be integrated into your data pipeline.
Once fetched, the appropriate Spark DataFrame can be used with the relevant machine learning algorithm to train, test, and evaluate the model. Simple!
For more examples, check out the HuggingFace DataSource Connector.
Stream Processing with Custom Sources
Moreover, as a fourth integration point, streaming data sources are as much part of your daily ETL pipelines as static sources in storage. You can also build streaming applications with custom sources that continuously ingest data.
Here is a code snippet for a custom Spark data source for streaming real-time aircraft tracking data from the OpenSky Network API. The OpenSky Network, a community-driven receiver network, gathers air traffic surveillance data and offers it as open data to researchers and enthusiasts. To view a full implementation of this streaming custom data source, check the GitHub source here.
Declarative Pipeline Integration
Finally, as a data engineer, you can easily integrate Python Data Sources with Declarative Pipeline Integration.
Reading From Custom Data Source
In Declarative Pipeline, ingesting data from the custom data source works the same way as in regular Databricks Jobs.
Writing to external services via Custom Data Source
In this example blog, Alex Ott demonstrates how the new Declarative Pipelines Sinks API allows you to use a sink object that points to an external Delta table or other streaming targets like Kafka as a built-in data source.
However, you can also write to a custom sink implemented as a Python Data Source. In our custom Python data source in the code below, we create a sink using the sink API and use that as the “sink” object. Once defined and developed, you can append flows. You can peruse the full implementation of this code here.
Building your Custom Connectors
To start using the Python Data Source API to build your custom connector, follow these four steps:
- Ensure you have Spark 4.0 or Databricks Runtime 15.4 LTS or later: The Python Data Source API is available in DBR 15.4 LTS and above, or use Databricks Serverless Generic Compute.
- Use the implementation template: Reference the base classes in pyspark.sql.datasource module.
- Register your connector: Make your connector discoverable in your Databricks workspace.
Use your connector: Your connector can be used just like any built-in data source.
Customer Success Stories using Python Data Source API
At Shell, data engineers often needed to combine data from built-in Spark sources like Apache Kafka with external sources accessed via REST APIs or SDKs. This led to one-off, or bespoke, custom code that was hard to maintain and inconsistent across teams. Shell’s chief digital technology officer noted that it wasted time and added complexity.
“We write a lot of cool REST APIs, including for streaming use cases, and would love to just use them as a data source in Databricks instead of writing all the plumbing code ourselves.” — Bryce Bartmann, Chief Digital Technology Advisor, Shell.
To take advantage of their cool REST APIs, the solution for the Shell data engineers was to use the new Python custom data source API to implement their REST APIs as a data source. It allowed developers to treat APIs and other non-standard sources as first-class Spark data sources. With object-oriented abstractions, it was easier to plug in custom logic cleanly—no more messy glue code.
Conclusion
In summary, PySpark’s Python Data Source API enables Python developers to bring custom data into Apache Spark™ using familiar and lovely Python, combining simplicity and performance without requiring deep knowledge of Spark internals. Whether connecting to REST APIs, accessing machine learning datasets like HuggingFace, or streaming data from social platforms, this API simplifies custom connector development with a clean, Pythonic interface. It bypasses the complexity of JVM-based connectors and gives data teams the flexibility to build, register, and use their sources directly in PySpark and SQL.
By supporting batch and streaming workloads and integrating with Unity Catalog, the API ensures your external data remains governed and accessible. From real-time ML pipelines to analytics or data ingestion, the Python Data Source API turns Spark into an extensible data platform.
Future Roadmap
As the Python Data Source API continues to evolve, we're excited about several upcoming enhancements:
- Column Pruning and Filter Pushdown: More sophisticated capabilities to optimize data transfer by moving filtering and column selection closer to the source
- Support for Custom Statistics: Allow connectors to provide source-specific statistics to improve query planning and optimization
- Better Observability and Debuggability: Enhanced logging tools to simplify connector development and troubleshooting
- Expanded Example Library: More reference implementations for familiar data sources and usage patterns
- Performance Optimizations: Continued improvements to reduce serialization overhead and increase throughput
Try It Today
The Python Data Source API is generally available today across the Databricks Intelligence Platform, including Databricks Runtime 15.4 LTS and above and Serverless Environments.
Start building custom connectors to integrate any data source with your data Lakehouse! And to learn how others have implemented Python DataSource by listening to these talks presented at the Data + AI Summit, 2025:
- Breaking Barriers: Building Custom Apache Spark™ 4.0 Data Source Connectors with Python
- Creating a Custom PySpark Stream Reader with PySpark 4.0
- Simplify Data Ingest and Egress with New Python Source API
Want to learn more? Contact us for a personalized Python Data Source API demo or explore our documentation to get started.
Documentation and Resources
- Python Data Source Documentation
- Declarative Pipelines
- Sinks with Declarative Pipelines
- Example Connectors Repository
- HuggingFace Connector
- Efficient use of the latest Declarative Pipelines features for cybersecurity use cases
- Delta Live Tables recipes: Consuming from Azure Event Hubs using Unity Catalog Service Credentials
- News Data Source API for PySpark
- Apache Spark™ Data Source for HugginFace AI Datasets
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.