Building an Agentic Food Label Reader for Greater Transparency
How Agent Bricks Simplifies Automated Label Processing at Scale
- Consumers demand food transparency but distrust producer claims, driving need for automated label processing
- Databricks Agent Bricks extracts and structures ingredient data from package images at scale
- Organizations can build production-ready label reading workflows in hours using no-code tools
Customer expectations for food labeling have undergone a fundamental shift. According to a recent survey, three-quarters of U.S. shoppers now demand comprehensive information about the food they buy, and nearly two-thirds scrutinize labels more carefully than they did five years ago. This isn't a passing trend, but rather is driven by more families managing allergies and intolerances, and more shoppers committed to specific diets, such as vegan, vegetarian, or gluten-free.
But here's the challenge: only 16% of consumers trust health claims from food producers. That means shoppers want to evaluate products themselves, on their own terms. They're scanning ingredient lists and carefully reviewing package labels to better understand sourcing, production practices, nutrition, and how these align with their specific health needs as part of their purchasing decision.
While regulators work on updated labeling requirements, leading retailers are already taking action. They're using advanced data extraction and ingredient analytics to transform packaging and nutrition labels into searchable, filterable digital experiences. This lets customers find exactly what they need, whether that's allergen-free options, gluten-free products, or sustainably sourced items. These transparency initiatives not only differentiate these retailers from their competitors but also drive deeper customer engagement and boost sales, especially of higher-margin products.
The Data + AI Solution
It is challenging to keep up with the 35,000 unique SKUs found in a typical U.S. grocery store, with 150 to 300 new ones introduced monthly. But with today's agentic AI applications, you can now automate food label reading at scale and at a reasonable cost.
With images of nutrient labels provided as inputs, these systems parse the images to extract raw ingredient and nutrition information. This information is then processed into structured data that can power both internal analytics and customer-facing digital experiences. From these data, you can then create custom classifications for allergens, ultra-processed ingredients, sustainability attributes, and lifestyle preferences, exactly what you need to support your customers.
In this blog, we'll show you how to implement an end-to-end process using Databricks' Agent Bricks capabilities to simplify and streamline the development and deployment of an automated food label reader for your organization.
Building the Solution
Our food label reading workflow is pretty straightforward (Figure 1). We will load images taken from food packages into an accessible storage location, use AI to extract text from the images and convert it into a table, and then apply AI to align the extracted text to a known schema.

In our first step, we collect a number of images of product packages displaying ingredient lists, like the one shown in Figure 2. These images in .png, .jpeg, or .pdf format are then loaded into a Unity Catalog (UC) volume, making them available within Databricks.

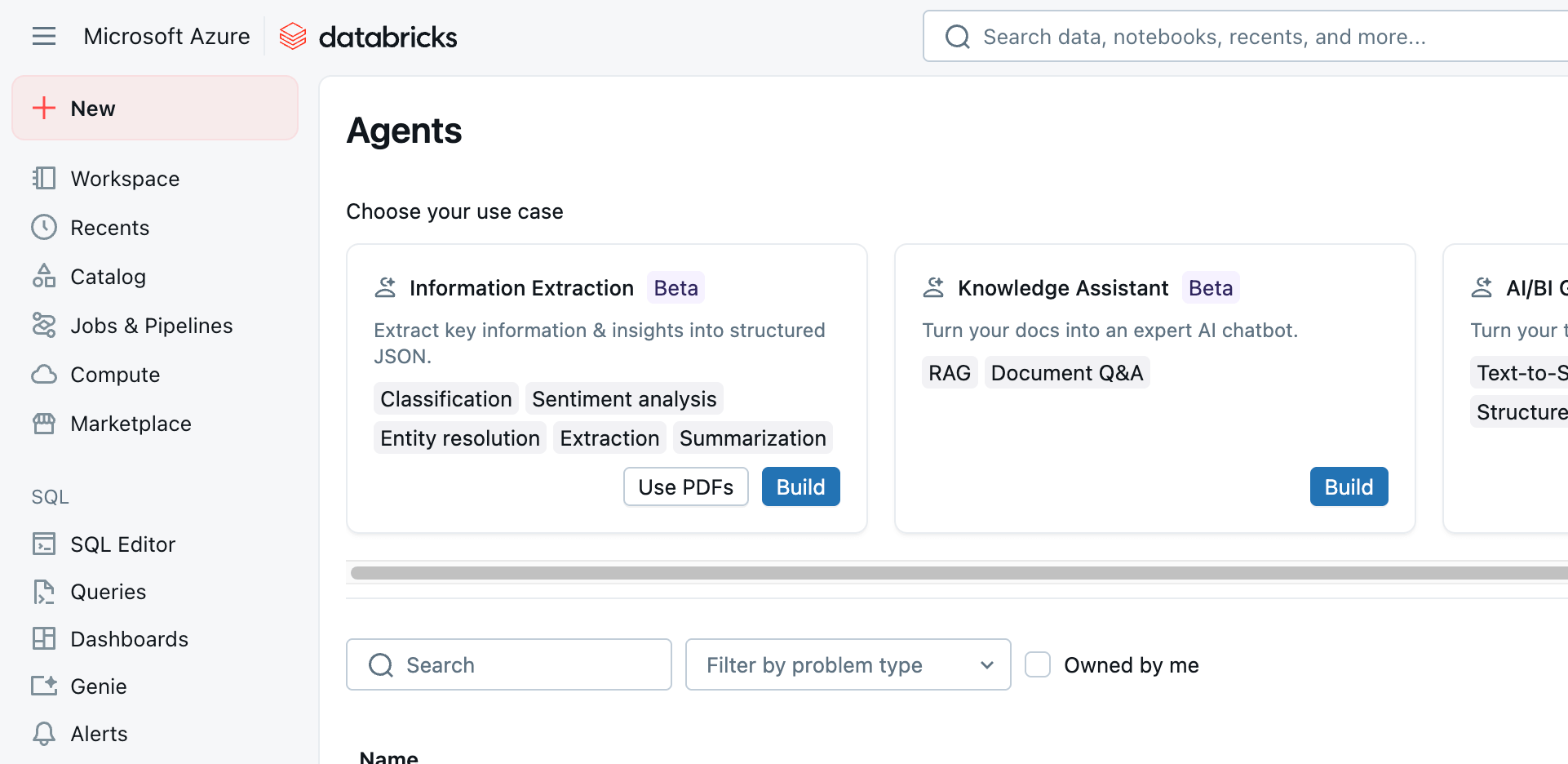
With our images loaded, we select Agents from the left-hand menu of the Databricks workspace and navigate to the Information Extraction agent shown at the top of the page (Figure 3).
{kind=link}
The Information Extraction agent provides us with two options: Use PDFs and Build. We will start by selecting the Use PDFs option, which will allow us to define a job extracting text from various image formats. (While the .pdf format is indicated in the name of the option selected, other standard image formats are supported.)
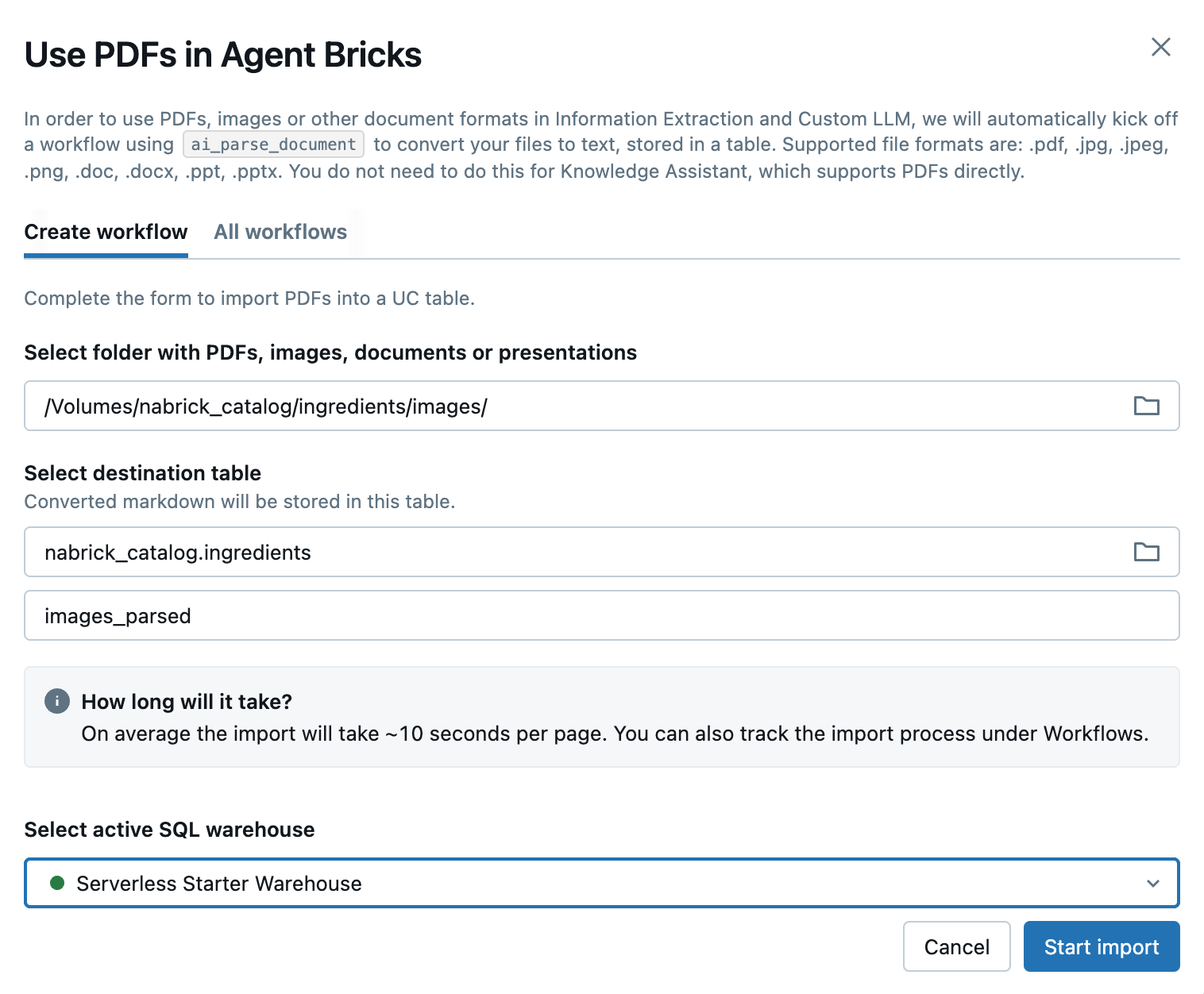
Clicking the Use PDFs option, we are presented with a dialog wherein we will identify the UC volume in which our image files reside and the name of the (as of yet non-existing) table into which extracted information will be loaded (Figure 4)
{kind=link}
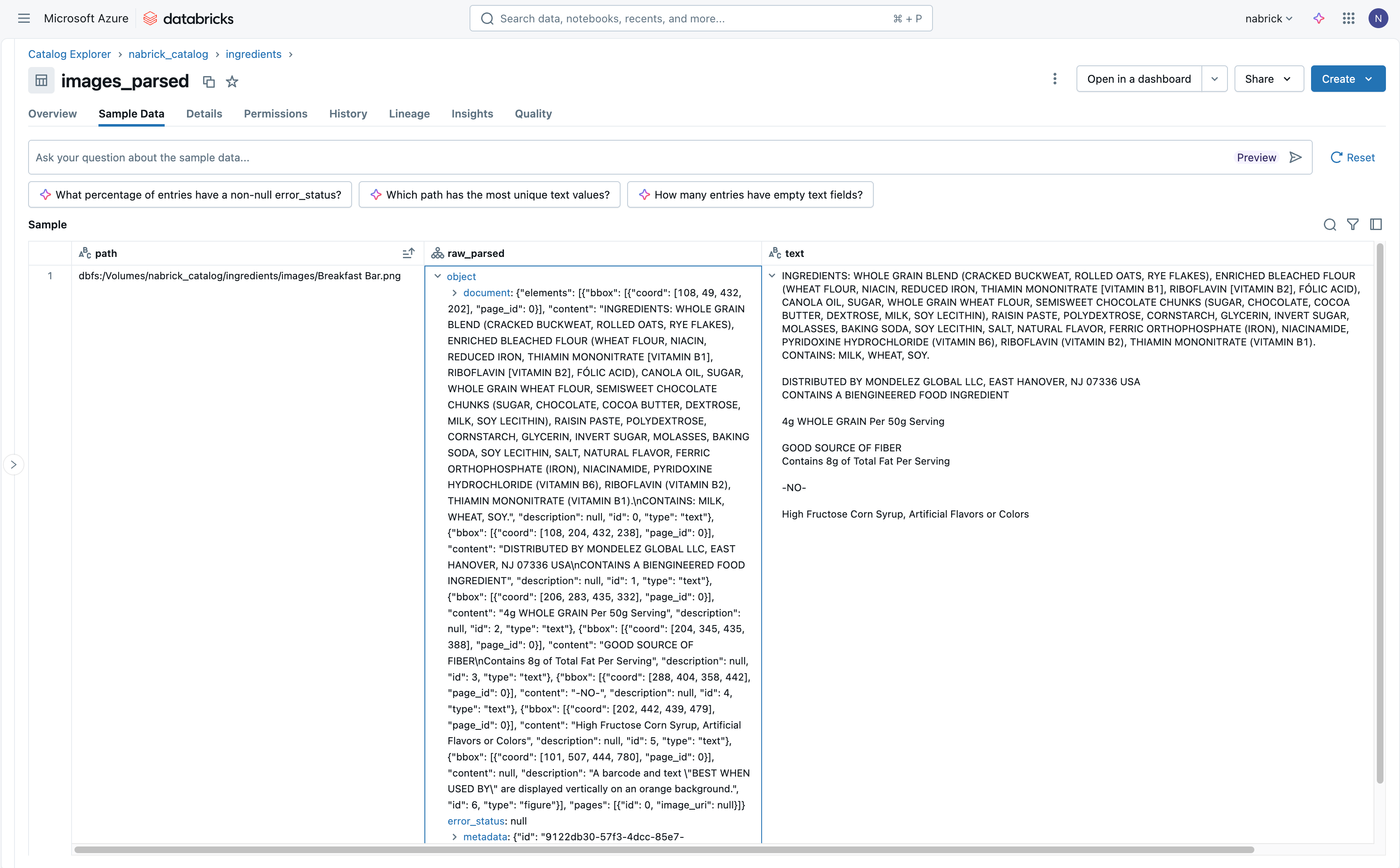
Clicking the Start Import button launches a job that extracts text details from the images in our UC volume and loads them into our target table. (We will return to this job as we move to operationalize our workflow). The resulting table contains a field identifying the file from which text has been extracted, along with a struct (JSON) field and a raw text field containing the text information captured from the image (Figure 5).
{kind=link}
Reviewing the text information delivered to our target table, we can see the full range of content extracted from each image. Any text readable from the image is extracted and placed in the raw_parsed and text fields for our access.
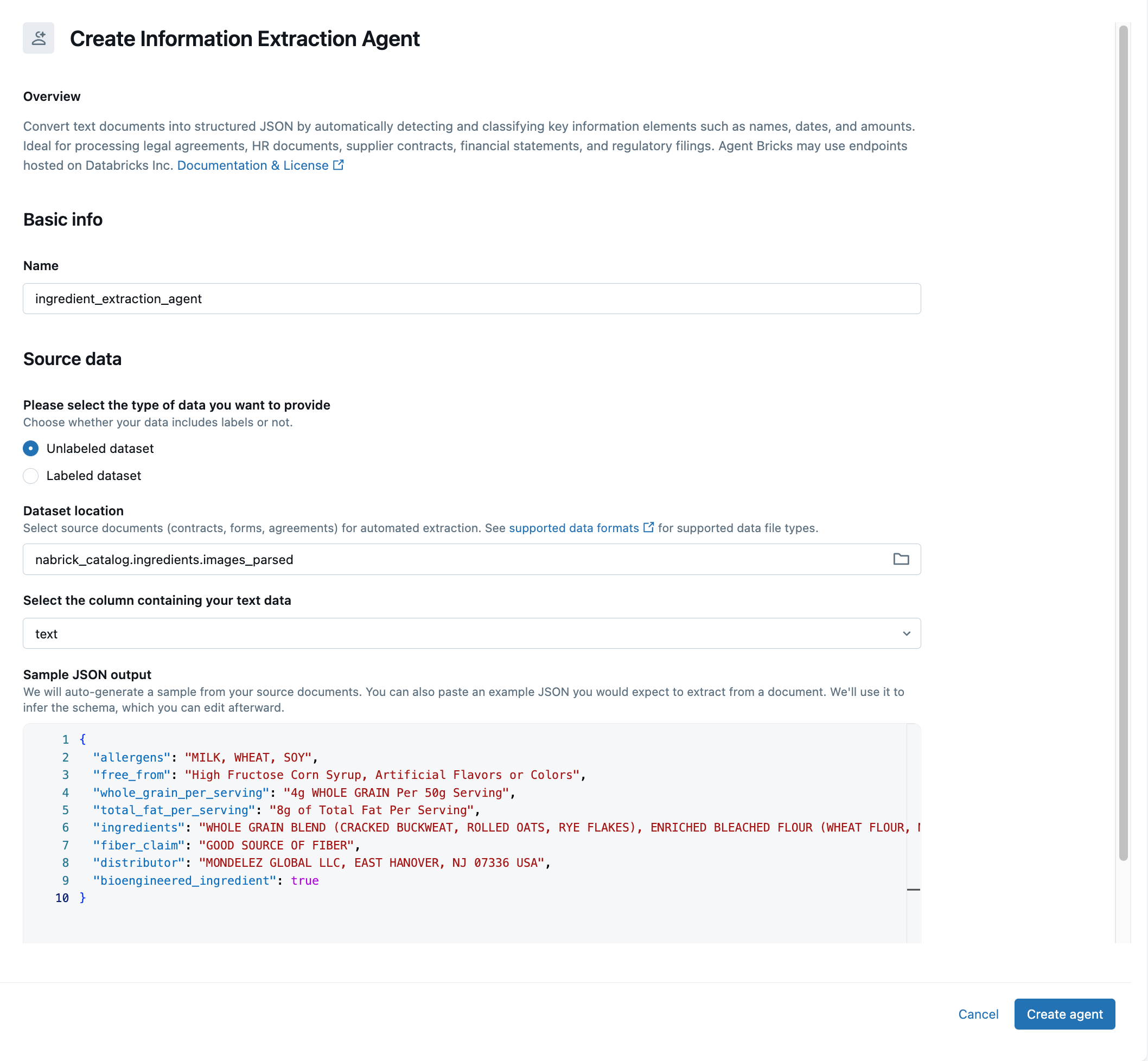
As we are only interested in the text associated with the ingredients list found in each image, we will need to implement an agent to narrow our focus to select portions of the extracted text. To do this, we return to the Agents page and click the Build option associated with the Information Extraction agent. In the resulting dialog, we identify the table to which we previously landed our extracted text and identify the text field in that table as the one containing the raw text we wish to process (Figure 6).
{kind=link}
The agent will attempt to infer a schema for the extracted text and present data elements mapped to this schema as sample JSON output at the bottom of the screen. We can accept the data in this structure or manually reorganize the data as a JSON document of our own definition. If we take the latter approach (as will most often be the case), we simply paste the re-organized JSON into the output window, allowing the agent to infer an alternative schema for the text data. It might take several iterations for the agent to deliver exactly what you want from the data.
Once we have the data organized the way we want it, we click the Create Agent button to complete the build. The UI now displays parse output from across multiple records, allowing us an opportunity to validate its work and make further modifications to arrive at a consistent set of results (Figure 7).
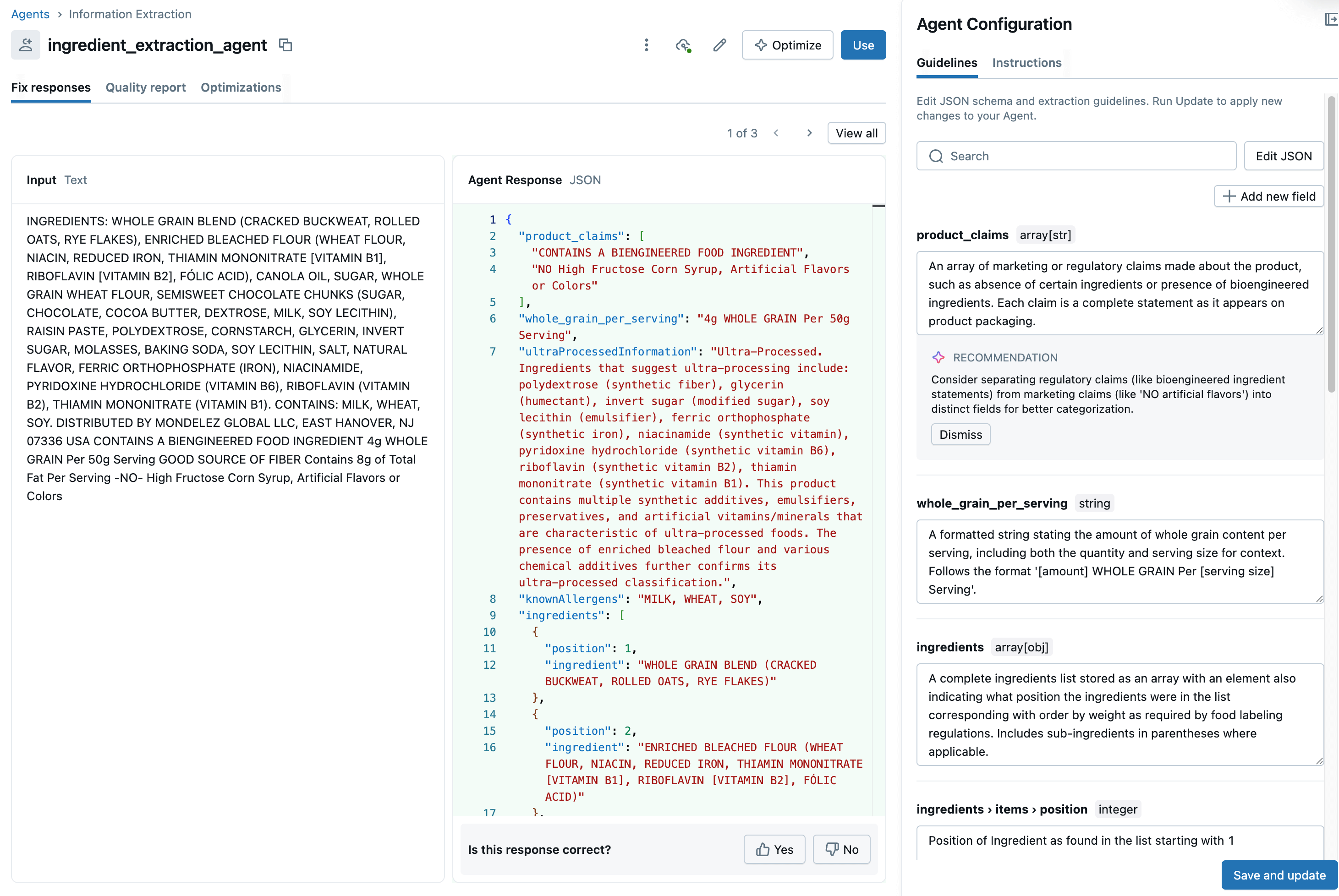
{kind=link}
In addition to validating the schematized text, we can add additional fields using simple prompts that examine our data to arrive at a value. For example, we might search our ingredient list for items likely to contain gluten to infer if a product is gluten-free or identify animal-derived ingredients to identify a product as vegan-friendly. The agent will combine our data with knowledge embedded in an underlying model to arrive at these results.
Clicking Save and Update saves our adjusted agent. We can use the Quality Report and Optimization tabs to further enhance our agent as described here. Once we are satisfied with our agent, we click Use to complete our build. Selecting the Create ETL Pipeline option will generate a declarative pipeline that will allow us to operationalize our workflow.
Note: You can watch a video demonstration of the following steps here.
Operationalizing the Solution
At this point, we have defined a job for extracting text from images and loading it into a table. We have also defined an ETL pipeline for mapping the extracted text to a well-defined schema. We can now combine these two elements to create an end-to-end job by which we can process images on an ongoing basis.
Returning to the job created in our first step, i.e. Use PDFs, we can see this job consists of a single step. This step is defined as a SQL query that uses a generative AI model through a call to the ai_query() function. What’s nice about this approach is that it makes it simple for developers to customize the logic surrounding the text extract step, such as modifying to logic to only process new files in the UC volume.
Assuming we are satisfied with the logic in the first step of our job, we can now add a subsequent step to the job, calling the ETL pipeline we defined previously. The high-level actions required for this are found here. The end result is we now have a two-step job capturing our end-to-end workflow for ingredient list extraction that we can now schedule to run on an ongoing basis (Figure 8).
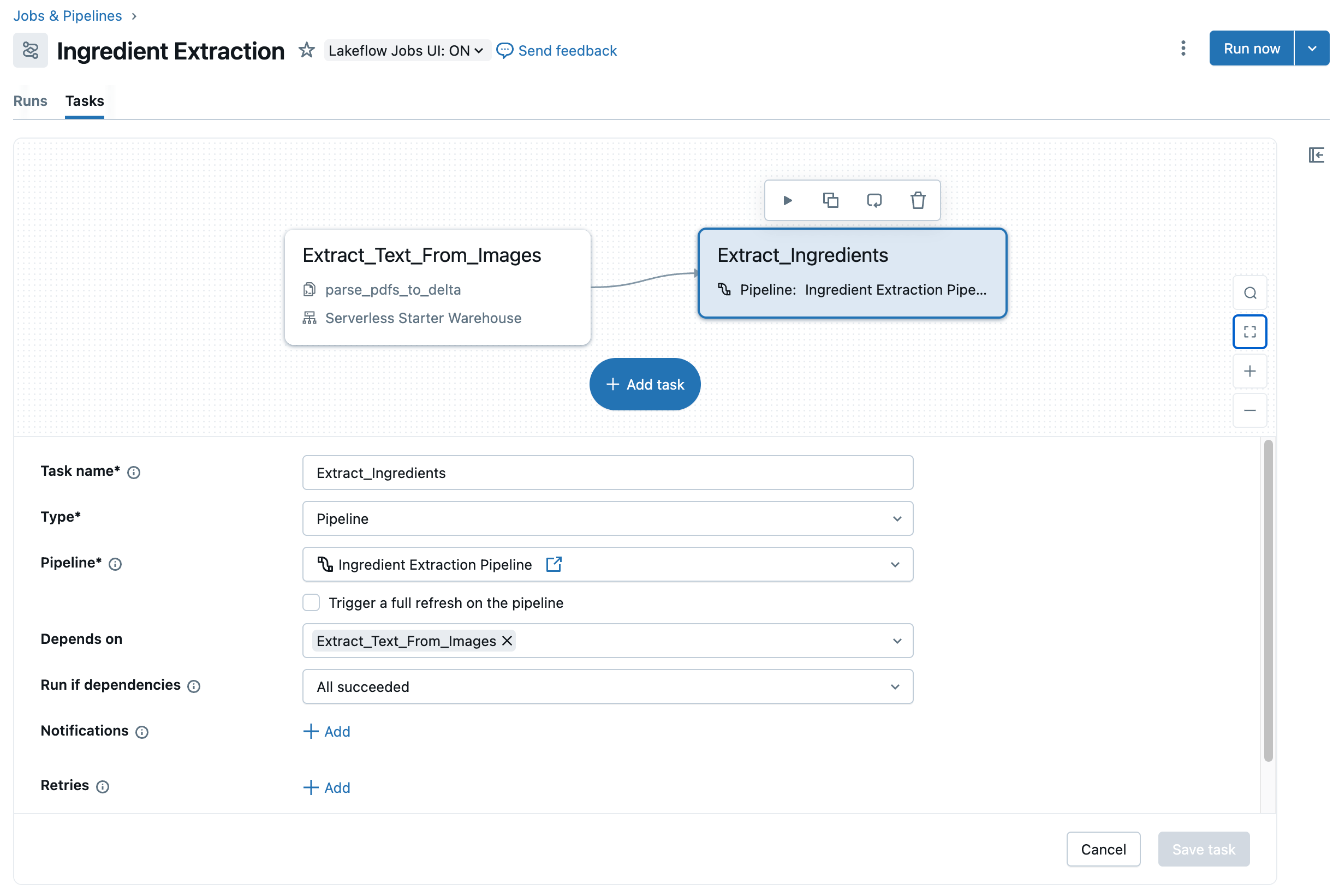
Get Started Today
Using Databricks' new Agent Bricks capability, it is relatively easy to build agentic workflows capable of tackling previously challenging or cumbersome manual tasks. This opens up a range of possibilities for organizations ready to automate document processing at scale, whether for food labels, supplier compliance, sustainability reporting, or any other challenge involving unstructured data.
Ready to build your first agent? Start with Agent Bricks today and experience what leading organizations have already discovered: automatic optimization, no-code development, and production-ready quality in hours instead of weeks. Visit your Databricks workspace, navigate to the Agents page, and transform your document intelligence operations with the same proven technology that's already processing millions of documents for enterprise customers worldwide.
- Start building your first agent with Agent Bricks today in your Databricks workspace
- Experience no-code development and production-ready quality in hours instead of weeks
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.