From Constant Firefighting to Innovation: How Databricks's Money Team Halved Their Ops Burden in One Year!
How Introducing an Ops Czar reduced operational burden and created collective empowered Ops ownership
by QIaochu Yang and Li Xiong
In the last year, the Databricks Money Engineering Team has embarked on an exhilarating journey, achieving nearly double our operational efficiency. We are excited to share this transformative experience with you, highlighting the specific strategies that fueled our success. In this post, we will discuss how introducing an Ops Czar reduced operational burden while at the same time empowered our engineering team. We will discuss pragmatism and Databricks first principles.
"In Unity, Strength": How Collective Effort and Strategic Efficiency Doubled Our Capabilities
The Money team is at the heart of commercializing Databricks's products, such as Workflows and Notebooks. We handle everything from metering product usage to calculating bills and clarifying costs for our customers. As Databricks expanded its product suite and customer base, our operations grew increasingly complex, risking a slowdown in our innovation.
This past year has been groundbreaking. Despite doubling our team size and continuously introducing new features, we've achieved significant improvements in operational health within the first six months. By the numbers, our achievements include:
- Cutting total operational costs by 50%
- Reducing time to mitigation (TTM) by 57%
- Decreasing time to resolution (TTR) by 28%
- Lowering monitoring gaps by 45%
- Diminishing incident volume by 64%
- Reducing pending repair items by 28%
The dramatic transformation we've achieved cannot be fully expressed by mere statistics. Instead, our progress is vividly illustrated through the direct experiences shared in our weekly on-call retrospectives:
- We moved from a chaotic scenario where 200 alerts bombarded us over a single issue, to a streamlined state with absolutely zero-noise alerts.
- Our team transitioned from a state of constant busyness, handling countless noisy alerts without any real emergencies, to a much calmer routine where only a couple of checks are needed daily.
- Even during our peak periods, on-call personnel now report, "It was a busy week, but still manageable. I had time to work on my projects." from previously – "all time is dedicated to the on-call work during the whole shift."
- Most compelling of all, the feedback that sums up our success: "There's been a day and night difference in just six months."
This feedback underscores the significant strides we've made in reducing stress, increasing efficiency, and fundamentally transforming our operational environment to a much better balance with feature work and reducing operational cost.
"When the Going Gets Tough, the Tough Get Going": The Ops Czar
With Databricks's hyper growth, the Money team struggled with a heavy on-call burden, with more than half the team rostered for on-call duties at any given time. This naturally started to create a victim mentality of "I didn't build this; it's not my fault."
How does one break a team free from the mindset of victimhood? How could we turn the situation around with already stretched resources? The fundamental question here is how could we change the culture? Traditionally, one might list tasks, assign costs in person-weeks, and distribute them among the team, a method assuming interchangeable skills—a flawed premise for complex tasks like improving operational health. However, this approach creates agency but without ownership.
To turn the situation around with our limited resources, we introduced the role of Ops Czar, who became the ultimate change agent. This shift from a shared responsibility model to a single ownership point eliminated inefficiencies and greatly enhanced our outcomes by focusing on high-ROI tasks and enabling decisive risk-taking.
"A Stitch in Time Saves Nine": Enhancing Efficiency through Proactive Monitoring and Noise Reduction
We aimed to enhance our monitoring systems and eliminate excessive alerts. Manual issue detection, as opposed to automatic detection, often resulted in significantly higher costs for several reasons:
- Delayed Detection: Issues detected manually tend to have already escalated in severity and impact, leading to a larger "blast radius" and requiring more extensive mitigation efforts.
- Increased Mitigation Efforts: A larger blast radius typically necessitates more comprehensive and resource-intensive mitigation strategies.
- Surprise Costs: The unexpected nature of manually detected issues adds additional engineering costs.
Addressing these monitoring gaps was crucial for cost reduction.
At the same time, we faced challenges with monitoring noise. There was a common belief that on-call engineers could easily dismiss 'transient' alerts without much trouble. However, our experience showed that this was not the case. On-call team members, being human, have limited working hours and a finite capacity for attention. Frequent context switches throughout the day diminished their ability to focus, making it difficult to manage serious incidents effectively. An overload of minor, misleading, or false alarms weakened their overall response capabilities.
Recognizing the negative impact of noisy alerts, we took a calculated risk and eliminated hundreds of them. We argued that a low-quality alert was just as detrimental as no alert at all. By freeing up resources previously devoted to managing these distractions, we were able to focus more on closing monitoring gaps, repaying technical debt, refining code and tests, and developing better tools like CICD automation.
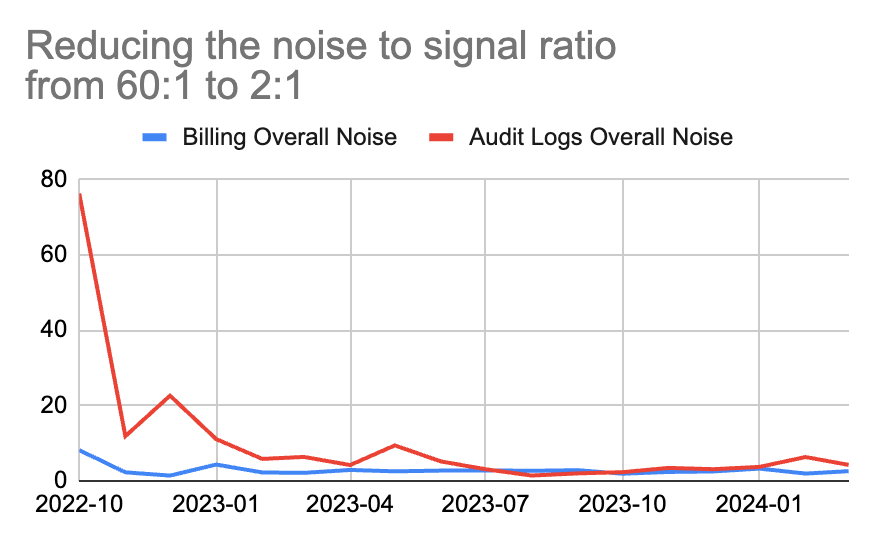
"Measure Twice, Cut Once": Embracing Precision and Pragmatism
From a company culture perspective, we adopted a first principles and truth seeking approach, setting a clear guiding principle at the forefront. For our billing business, "Correctness Above All" became the mantra, prioritized over other considerations like latency. We thoroughly evaluated all options, assessing their return on investment using meticulously chosen metrics. Our strategy was to invest incrementally, continuously gathering data and refining our approach based on the insights gained, waiting for a definitive positive signal before scaling our efforts.
Our most significant hurdle was quantifying the time engineers spent on operational costs, known as Keep-The-Lights-On (KTLO) costs. While the ideal scenario would be to measure this precisely, the high cost of precision led us to adopt simpler methods. Each team member dedicated one minute per week to log an estimate of the days spent on operational tasks. Though lacking in precision, this method, when aggregated across 20 people over three months, provided valuable insights. This pragmatic approach proved enlightening, despite our inherent desire for accuracy. For instance, one insight we got was the correlation between KTLO costs and percentage of the noisy alerts. Though neither number was perfect, the strong correlation was obvious enough for us to focus on noise reduction.
"Slow and Steady Wins the Race": Cultivating Endurance and Consistency in Transformation
Transforming our culture could be compared to the pursuit of weight loss: quick wins are possible, but lasting success is rare without a sustainable strategy. Hard work alone was not the answer; building enduring habits was. Habit formation could have been top-down, with managers and leads playing the enforcer's role. However, we argued that external motivations fall short in comparison to the power of intrinsic motivation. The team appreciated Ops Czar's contribution to lift the team's KTLO toil to a much better situation. With the trust and respect, Ops Czar championed a shift towards collective ownership, emphasizing: "Our achievements are a team effort. We've demonstrated our capability for improvement. Our future is in our hands."
Furthermore, the Ops Czar illustrated a compelling vision: If every on-call member makes small, consistent contributions each week by reducing noise, closing monitoring gaps, and resolving issues for the long term, the entire team will face fewer distractions, experience less stress, and encounter fewer incidents over time.
The Ops Czar organized weekly sessions to spotlight and praise team members who had made transformative contributions, ensuring their efforts were recognized by the entire team. Together, we examined the upward trends in our operational health metrics, reinforcing our shared successes. As a testament to our progress, we honored the entire team with a company-wide Engineering Reward.
"Many Hands Make Light Work": Leveraging Collective Effort for Operational Excellence
We started from a difficult position where outgoing on-call staff would routinely pass unresolved issues to their incoming counterparts. This practice resulted in a lack of sustained focus and continuous engagement with incidents, leading the team to face recurring, fragmented challenges each week. To address this and harness the team's collective efforts effectively, we recognized the need to establish clear ownership of issues.
We revamped our operational procedures for on-call transition and review. Each week, we ensured the outgoing on-call passed all open incidents to their successor, aiming for a clean slate for the incoming on-call. Before our weekly ops review, the outgoing on-call tagged all service health dashboard anomalies. They documented symptoms and root causes for the week's incidents. We suggested on-calls to tackle at least one task to diminish noise, bridge monitoring gaps, or enhance a runbook. We consistently reminded the team of unresolved incidents and open follow-up tasks every week. They appeared demanding, but offered reciprocal benefits: On-calls not only enhanced system hygiene but also reaped the team's efforts by having less to do. The significant effects of their contributions, along with the progress and reduced toil presented at weekly reviews, energized our cultural shift.
"Iron Sharpens Iron": Forging Operational Excellence Through Shared Wisdom
Our journey did not end with merely overcoming our internal challenges. We capitalized on our accumulated experiences, lessons, and inspirations to develop a suite of tools that significantly elevate operational practices. To enhance the on-call experience, we introduced a GenerativeAI recommendation system that utilizes the rich contexts of historical issues to suggest relevant past incidents whenever new issues arise. Recognizing the inefficiency of manually transferring incident details from one on-call to another, we created an incident playback visualizer. This tool enables the upcoming on-call staff to asynchronously understand key issues, streamlining the transition process. Additionally, acknowledging the importance of backlog, noise, and monitoring gaps as critical indicators of operational health, we designed a comprehensive dashboard that not only displays these metrics but also harnesses these insights to prioritize areas needing attention.
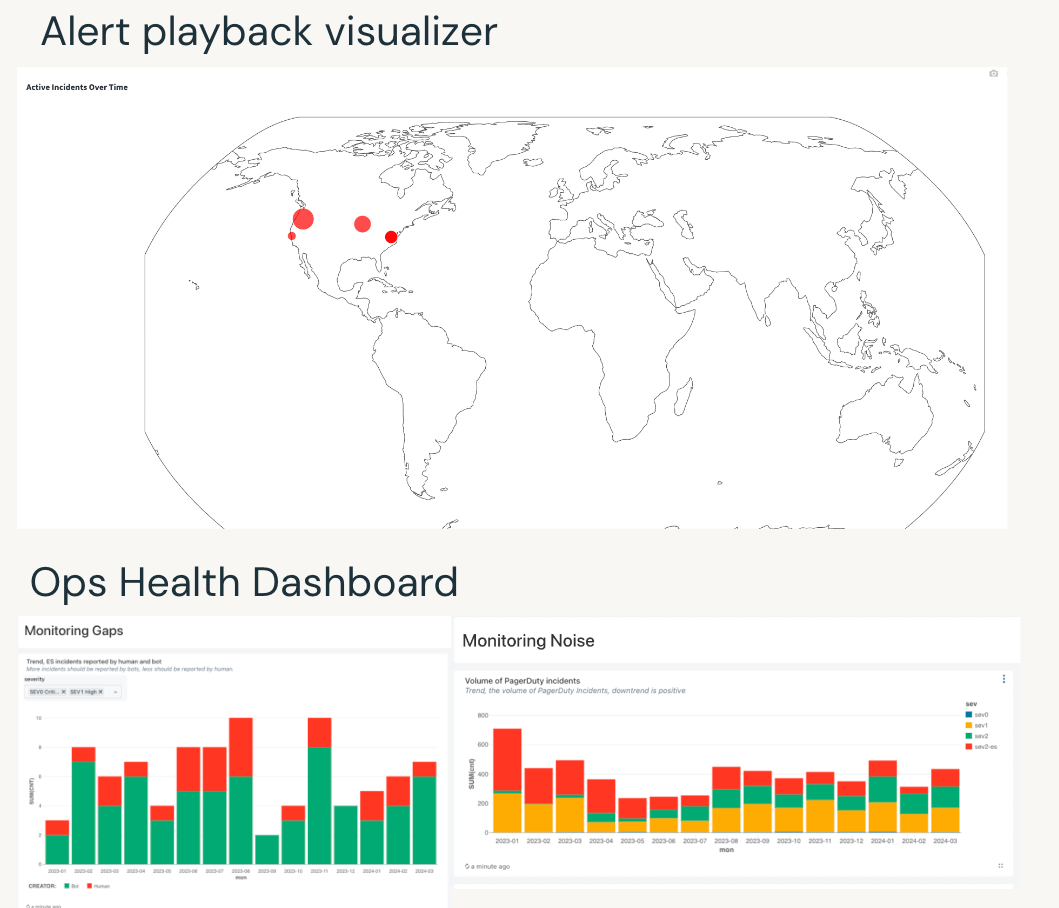
Upon sharing our developments with sister teams, their universal applicability became apparent—operational hygiene, efficiency, and rigor are pivotal for most engineering teams in the cloud sector. This realization spurred a collaborative effort with approximately twenty teams within Databricks to establish a unified dashboard. This tool empowers any team to access and analyze their operational health, thereby nurturing a culture of continuous improvement across the entire organization.
"From Small Seeds Grow Mighty Trees": Reflecting on a Year of Growth and Achievement
Reflecting on the past year fills us with excitement. The improvements we've achieved are impressive, but even more significant is the transformation in our team's mindset and culture. The once daunting on-call shifts have evolved into an enriching experience that everyone looks forward to. To achieve our core goals of accurate billing and cost optimization, we streamlined our operations to reduce on-call busyness. With the introduction of the Ops Czar, we could further reduce operational burden, employ smoother handoff processes, and most importantly empower our own team. Through pragmatism and first principles, we could share this success with many other engineering teams in Databricks.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.