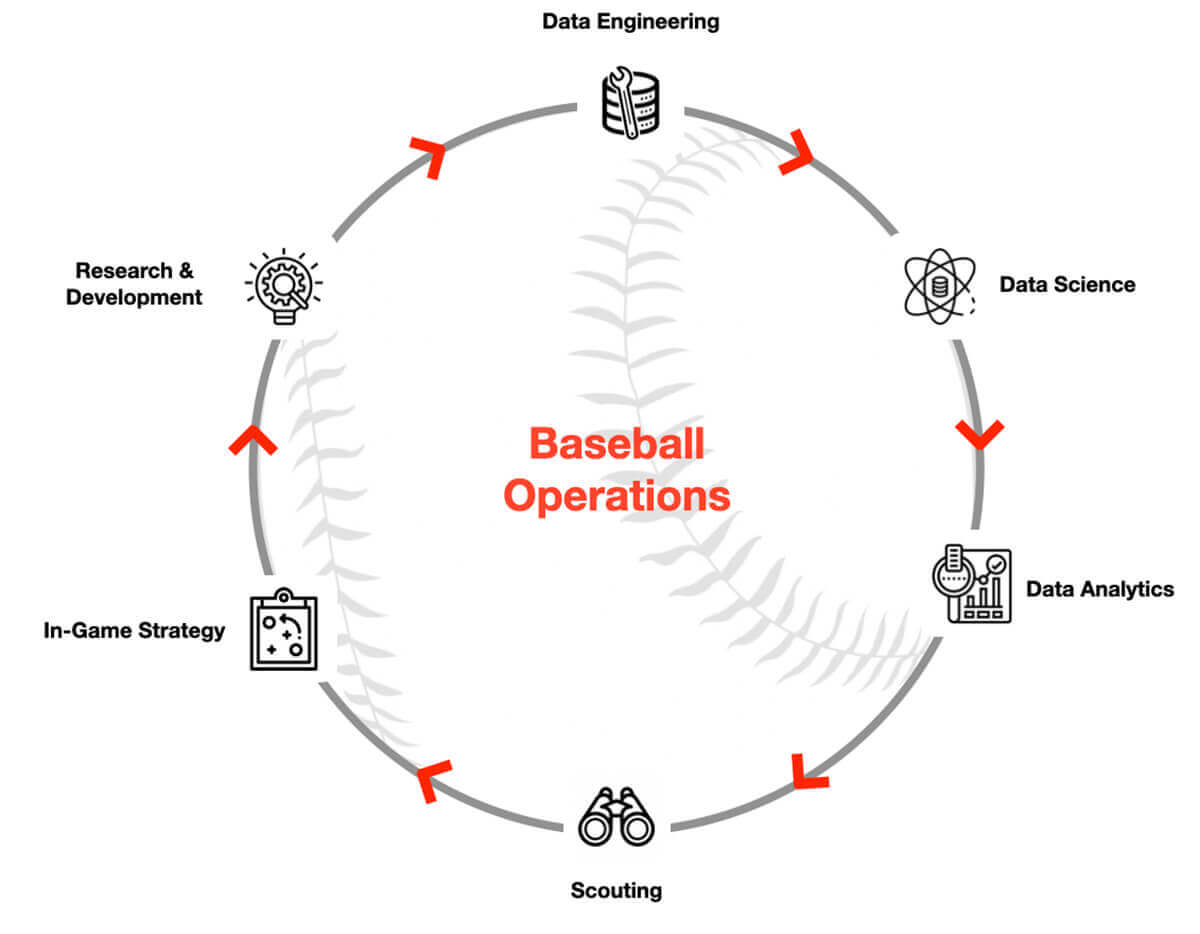
Cracking the code: how Databricks is reshaping professional baseball with biomechanics data

Biomechanical data has emerged as a game-changing factor for professional baseball teams, offering a competitive edge in enhancing player performance and reducing injuries. Yet, despite its potential, most teams have struggled to embrace its full capabilities.
Biomechanical data originates from diverse sources, including wearable sensors, force plates, mobile devices, and most notably, high-speed cameras. The advent of the Hawk-Eye Statcast system in 2020, featuring twelve strategically placed cameras in each stadium, marked a significant step forward. Five of these cameras were dedicated to pitching and hitting, operating at 100 Frames Per Second (FPS), a rate that was upgraded to 300 FPS in 2023 for improved tracking. The remaining seven cameras focus on field players and batted balls, capturing data at 50 FPS. These camera systems collectively generate a staggering 24 terabytes of data for each of the 2,430 regular-season professional baseball games.
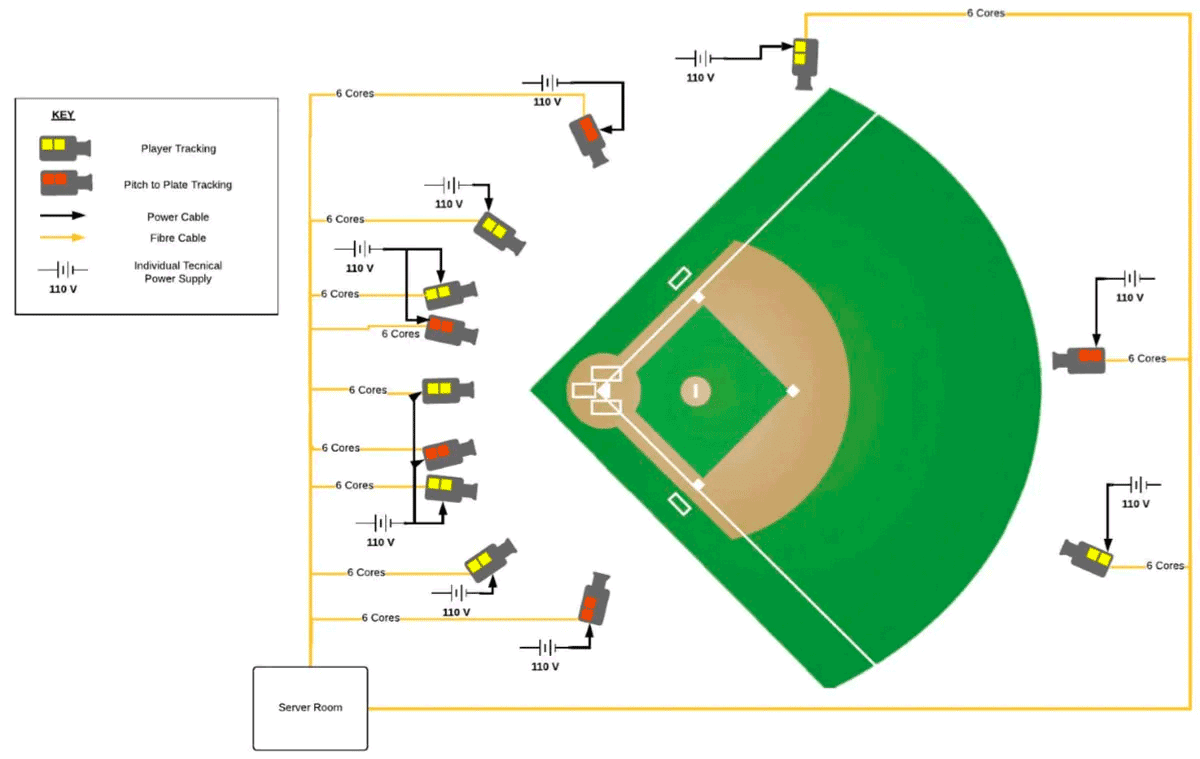
However, despite the enormous volume of data and the innovative technology used to capture it, many professional baseball teams are still using traditional methods to analyze it. There are several reasons why, but the most common obstacles in adoption of more advanced methods are due to a lack of resources such as cost, skill sets, and technology constraints.
Traditional Analytical Tools: Data Warehouses
Traditional analytical tools, such as data warehouses, face several shortcomings when dealing with biomechanical data and analysis. Here are four areas of concern in the adaptation of biomechanical data with a data warehouse.
First, establishing accurate and scalable data pipelines for biomechanical data is inherently complex. Two-tier data architectures are commonly seen, with separate data lakes and warehouses. Most teams currently land raw data in their data lakes, with the hope of being able to perform some analysis on it by duplicating the data in a data warehouse. These disparate systems often have discrepancies in data types, SQL dialects, and data schemas. This leads to inconsistencies and an increased risk of failures or errors in the extraction, transformation, and loading (ETL/ELT) processes.
Secondly, many biomechanics applications require access to more real-time data. However, the existing data architectures introduce data staleness issues by employing separate staging areas and periodic ETL/ELT jobs for data loading. Coaches and athletes need quicker feedback to enhance performance in preparation for the next game and prevent injuries.
Thirdly, a substantial portion of biomechanics data is unstructured, including video footage, tracking data, derived metrics and metadata. However, traditional SQL data warehouses and associated APIs are not well-suited for handling such unstructured biomechanics data.
Finally, the growing adoption of machine learning and data science in biomechanics highlights the limitations of traditional data warehouses and lakes. These applications often involve processing large volumes of non-SQL data, making them inefficient when relying solely on ODBC/JDBC connections. Therefore, providing direct access to biomechanics data in an open format becomes increasingly important to support the evolving needs of biomechanical analysis and modeling.

The Cutting Edge: Databricks Lakehouse for Biomechanics
Databricks, the creator of the Lakehouse architecture, is optimized for big data processing. It is quickly emerging as the platform of choice for biomechanical analysis across the professional baseball.
Here are a few of the reasons why Databricks is favored in the professional baseball:
Large Scale Data Processing
Databricks is inherently designed to manage vast data volumes with distributed computing. Given the multitude of sources capturing biomechanical data, there is a need for centralized data management. Currently, most teams employ a patchwork of software systems, leading to redundancy, data silos, sluggish processing times, and exorbitant costs.
Databricks enables teams to centralize all their data, regardless of its structure, under one roof. This is made possible by the Lakehouse architecture, which combines the storage capabilities of a data lake with the organizational prowess of a data warehouse. With Databricks, teams can swiftly process both current and historical data to derive meaningful insights.
Streaming
The ability to pull real-time insights is invaluable as it empowers coaches and players to make informed decisions during practice or games. Databricks easily facilitates streaming in biomechanics on an event-by-event basis with exactly-once processing guarantees. This significantly reduces the amount of data being processed within a single pass, making the process event-driven and the data processing incremental.
In many cases, professional baseball teams have waited for hours or even days to receive information that could have impacted a game or prevented injuries to key players. However, Databricks Structured Streaming alleviates this issue.
Machine Learning
Databricks has native support for advanced machine learning capabilities. This simplifies the end-to-end machine learning life cycle directly on data in the lake without the need for copying data into a separate platform. Databricks open-source MLOps offering, MLflow, empowers users with a suite of machine learning features:
- Experiment Tracking - record and compare model parameters, evaluate performance, and manage artifacts.
- Code Packaging - reuse and reproduce code effortlessly to streamline workflows.
- Model Deployment - deploy models from a range of machine learning libraries to real-time and batch serving and inference platforms.
- Centralized Model Management - collaboratively manage models in a central repository, complete with version control and seamless stage transitions.
Relating this to real world implications, Databricks and MLflow enable teams to discover invaluable insights for baseball player development. For instance, undrafted or recently drafted players create a considerable amount of uncertainty. This is because it can take 3-4 years for new recruits to make a substantial impact on a team. As a result, professional baseball organizations must strategize for the long term.
Evan Carter's story with the Texas Rangers' minor league team exemplifies the potential of ML. Carter did not get scouted heavily as an amateur because he attended few showcase events. Despite the limited availability of data, ML analysis on his biomechanics unearthed his innate talent.
Scalability
As the amount of data generated in biomechanics continues to increase, the ability to scale processing both up and down is essential. With Databricks, teams have access to as much compute as needed instantly and elastically. Jobs can be directly orchestrated in the platform via Databricks Workflows.
The Databricks platform separates storage and compute, reducing total cost of ownership.This allows capital to be reinvested in new data sets or projects. An example of this was shown with the Texas Rangers during their presentation at the 2023 Data+AI Summit, which can be found here. The Rangers experienced a 7x increase in data velocity when producing new data pipelines, without altering their budget.
Collaborative Environment
Professional baseball affiliates span across professional and minor league teams, both domestically and internationally. Databricks provides a collaborative environment for data engineers, data scientists, and data analysts, regardless of an organization's dispersion. This facilitates seamless data sharing, model development, and refinement under one roof.
Conclusion
In conclusion, the potential of biomechanics to revolutionize player performance and injury prevention in professional baseball is undeniable. However, realizing these benefits requires a modern, agile, and scalable data processing platform. Databricks, with its Lakehouse architecture, is the game-changing solution that empowers professional baseball teams to harness the full potential of biomechanics data. With Databricks, you can conquer the challenges of data volume, variety, velocity, real-time insights, unstructured data handling, and robust support for advanced analytics. So, why wait? Join the future of biomechanics analysis today and unlock new possibilities for your team with Databricks. Try it for yourself and experience the competitive edge that awaits your organization.
To speak with the Sports Team at Databricks contact Harrison Flax
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.