Creating a bespoke LLM for AI-generated documentation
It’s easier than you think: 2 engineers, 1 month, and less than $1,000
by Matthew Hayes, Hongyi Zhang, Tao Feng, Jan van der Vegt, Zaheera Valani and Reynold Xin
We recently announced our AI-generated documentation feature, which uses large language models (LLMs) to automatically generate documentation for tables and columns in Unity Catalog. We have been humbled by the reception of this feature among our customers. Today, more than 80% of the table metadata updates on Databricks are AI-assisted.
In this blog post, we share our experience developing this feature – from prototyping as a hackathon project using off-the-shelf SaaS-based LLMs to creating a bespoke LLM that is better, faster, and cheaper. The new model took 2 engineers, 1 month and less than $1,000 in compute cost to develop. We hope you will find the learnings useful, as we believe they apply to a wide class of GenAI use cases. More importantly, it has allowed us to take advantage of rapid advances being made in open-source LLMs.
What is AI-generated documentation?
At the center of each data platform lies a (potentially enormous) collection of datasets (often in the form of tables). In virtually every organization we have worked with, the vast majority of tables are not documented. The absence of documentation provides a number of challenges, including making it difficult for humans to discover the data needed for answering a business question, or more recently, for AI agents to automatically find datasets to use in response to questions (a key capability in our platform that we’re calling Data Intelligence).
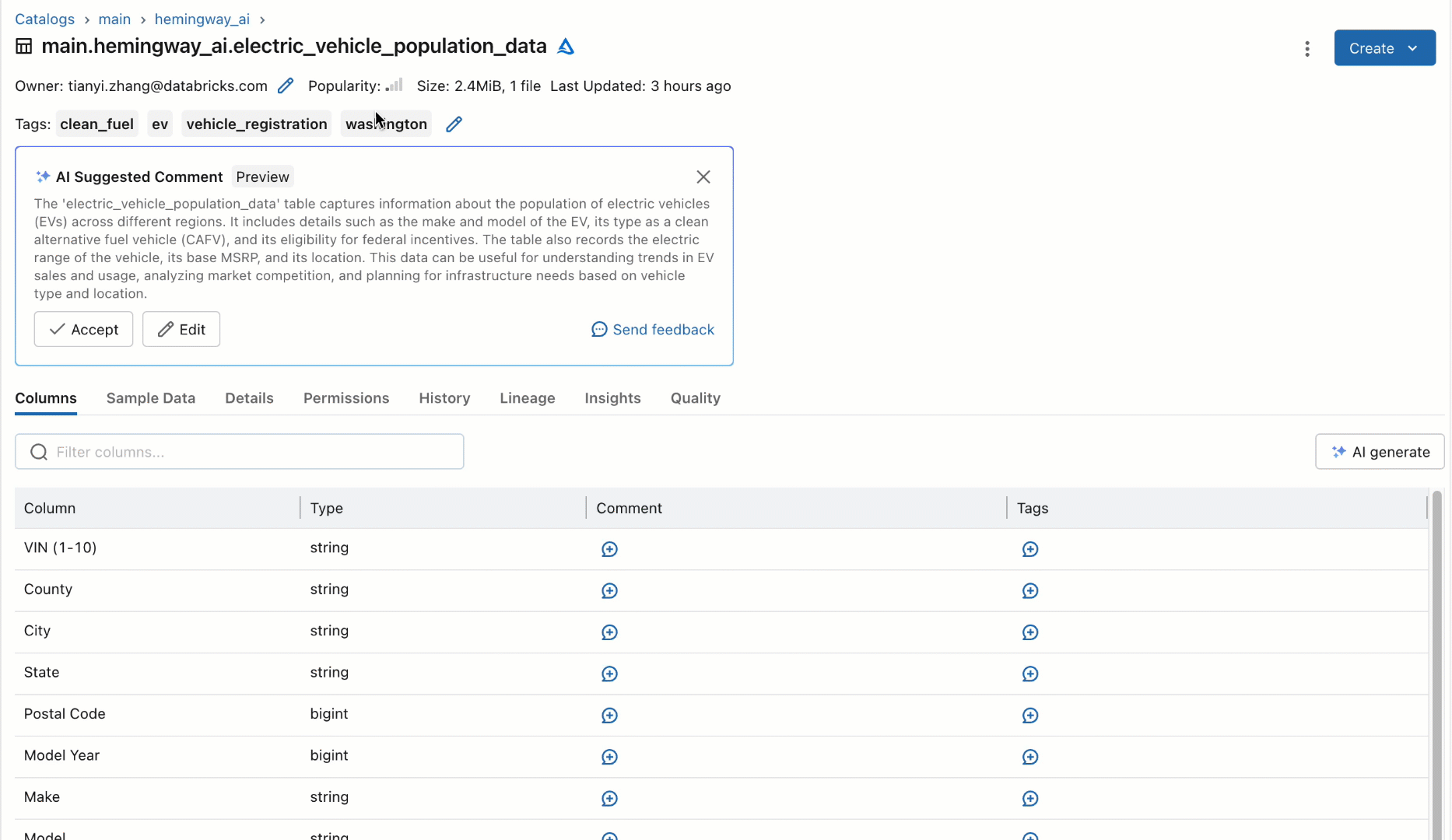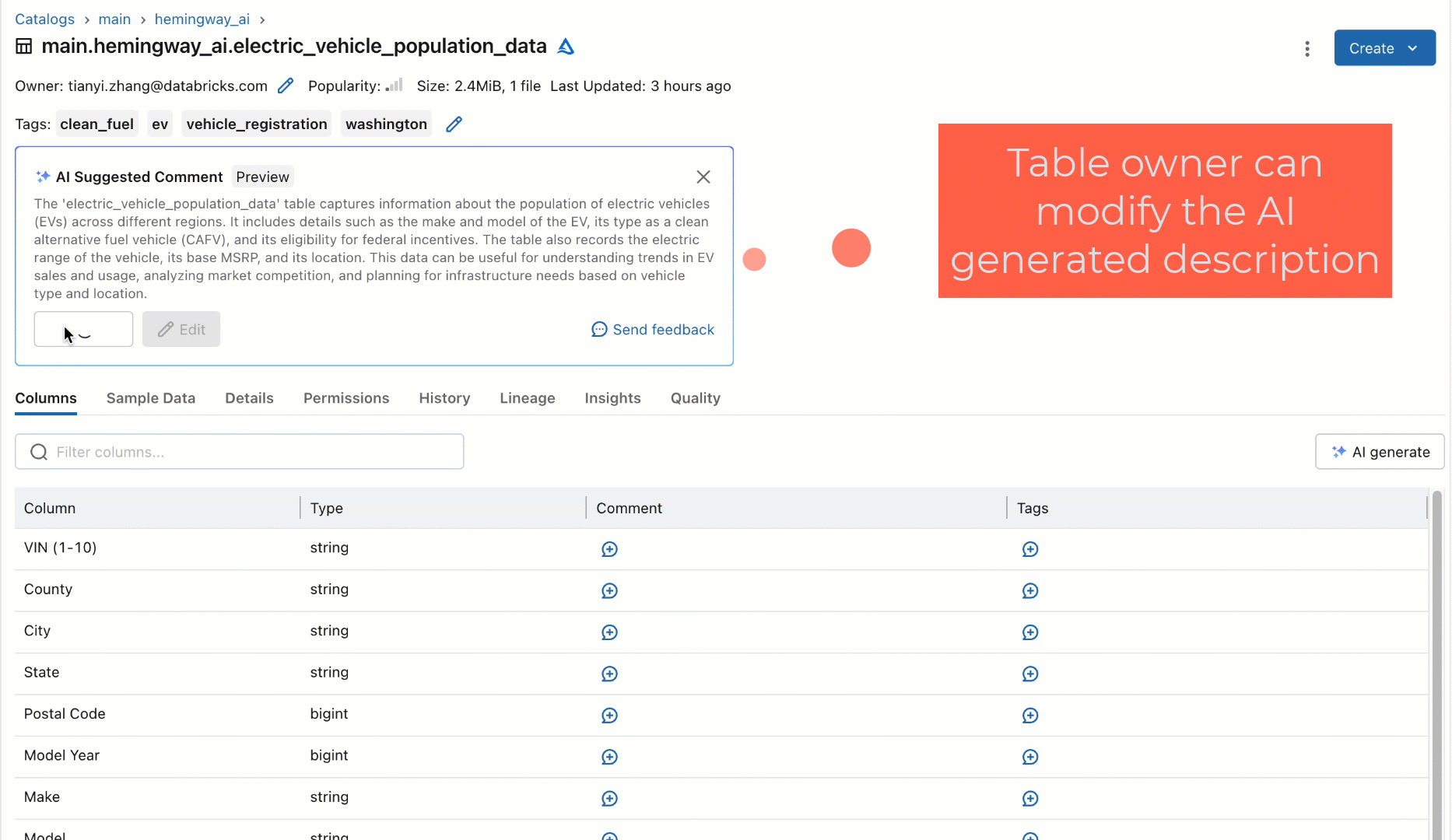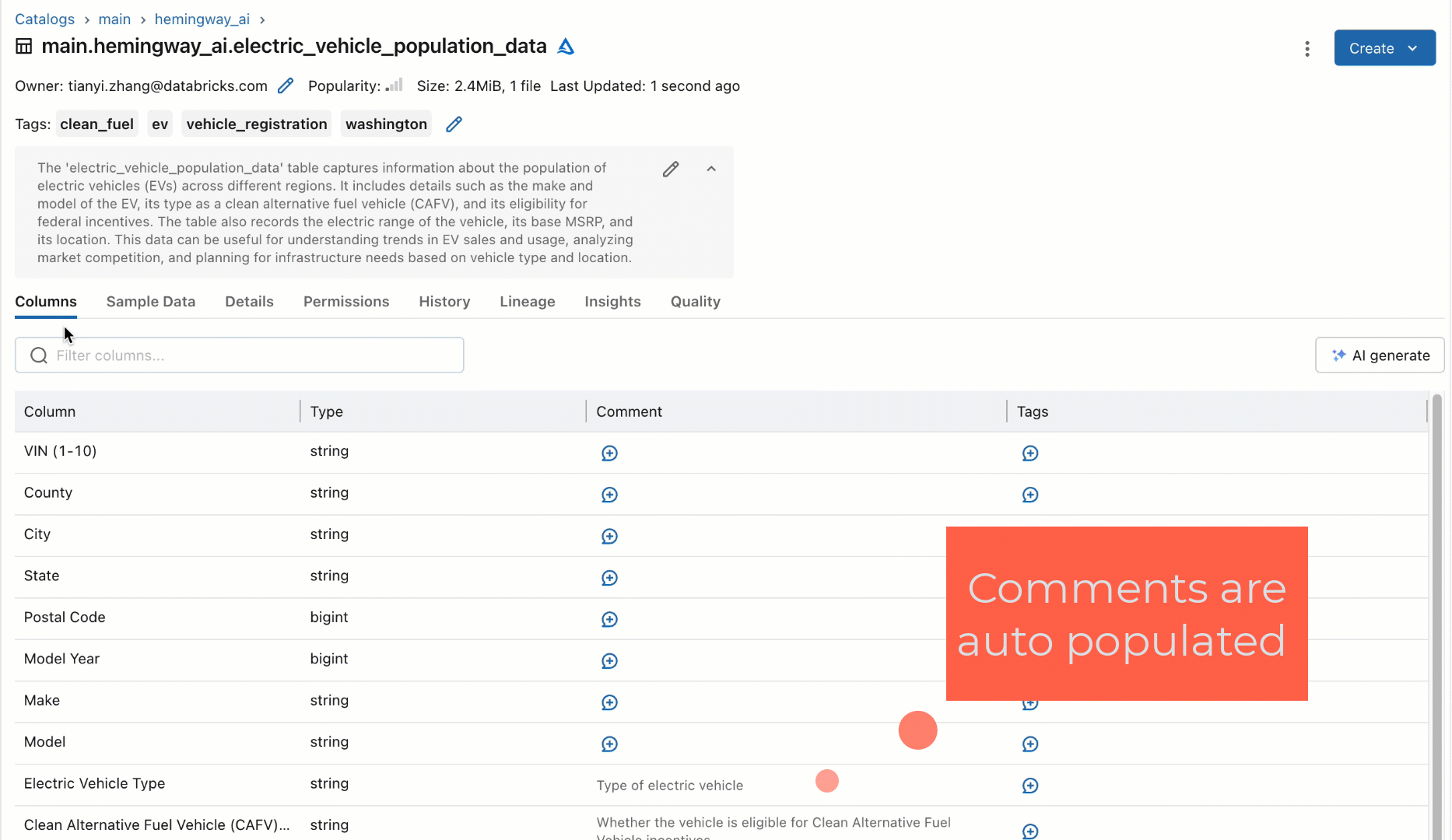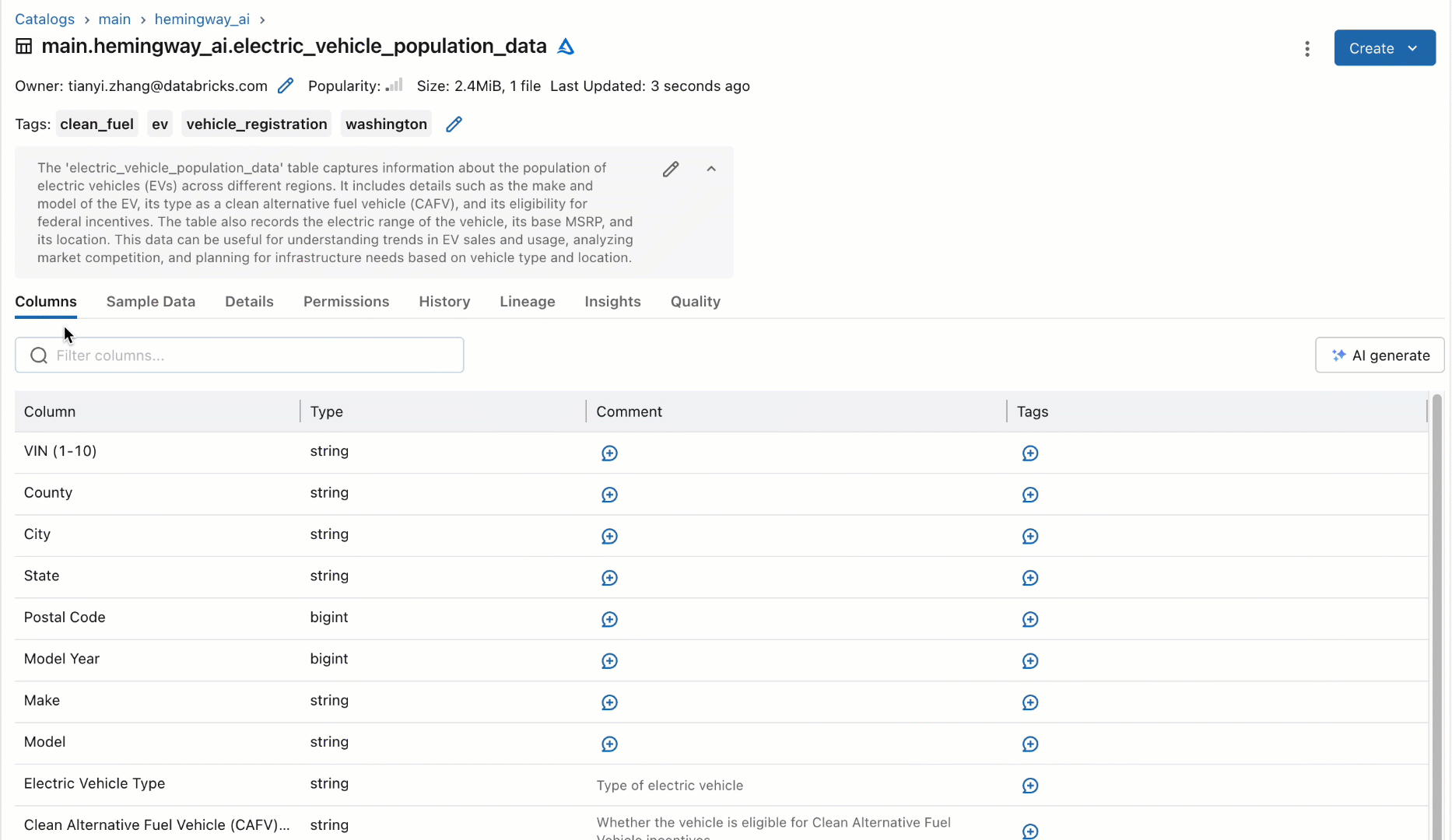
Rather than relying on humans to document these datasets, we prototyped as part of our quarterly hackathon a new workflow using an off-the-shelf SaaS-based LLM to automatically generate documentation for tables and their columns based on their schema. This new workflow would automatically suggest descriptions for the tables and columns and allow users to either individually accept, bulk accept, or modify the suggestions for higher fidelity, as shown below. When we showed this prototype to some users, their immediate question was universally, “When can I have it?!”
Challenges with LLMs
As we moved towards launching this feature to all our customers, we ran into three challenges with the model:
- Quality: The ultimate success of this feature depends on the quality of the generated documentation. Although we could measure the quality (in terms of how often they are accepted), we had limited knobs at our disposal to improve it, aside from basic prompting. During the private preview period, we also sometimes noticed the quality of the suggestions degrading, without any change to our codebase. Our speculation is that the SaaS LLM controller rolled out updates to the model that sometimes affected performance on specific tasks.
- Performance (throughput): We had limited API quota provisioned with the SaaS LLM provider. We work with tens of thousands of organizations, and it is not uncommon that a single organization would have millions of tables. It would take too long to generate documentation for all the tables based on the throughput quota.
- Cost: Related to the above, it was not cost-effective unless we started charging customers for using this specific feature.
We have heard similar concerns from a variety of customers as they try to move their LLM-based applications from a proof-of-concept to production and saw this as an excellent opportunity for us to explore alternatives for an organization like ours.
We experimented with different versions of the SaaS LLMs, but they all had the same challenges. This is not surprising in hindsight. The SaaS LLMs are an engineering marvel, but they are very general models that need to address all the use cases from table generation to conversing about the meaning of life. The generality means it needs to have an extremely large number of parameters, which limits how fast and how cheap it can return answers. As it continues to evolve to optimize for different use cases, it might also regress the narrower use case we have.
Building a bespoke model
To address the aforementioned challenges, we started building a bespoke model. It took a team of two engineers one month to build a customized, smaller LLM that was better, faster, and cheaper:
- Quality: Based on our evaluation (see below), the model is significantly better than the cheaper version of the SaaS model, and roughly equivalent to the more expensive version.
- Performance (throughput): Because the bespoke model is a lot smaller, it can fit in A10 GPUs, and we can increase the inference throughput with horizontal scaling. The smaller GPUs are also more available, which enables us to generate the descriptions for all tables faster.
- Cost: Each fine-tuning run of the model only costs a few dollars, and in aggregate, it cost less than $1000 to develop because we did a lot of experiments. It also resulted in a 10 fold reduction in inference cost.
The first step was to treat this as an applied machine learning problem. “Applied machine learning” sounds daunting and complicated, but all it meant was that we needed to:
- Find training datasets so we can bootstrap an initial model
- Identify an evaluation mechanism so we can measure the quality, before rolling it out to production
- Train and select models
- Collect real-world usage metrics, so we can monitor how well a monitor does in production
- Iterate and roll out new models to continuously improve the three dimensions: quality, performance, cost
Training data
We created the initial training dataset for this fine-tuning task, using two different sources of data:
- North American Industry Classification System (NAICS) codes. This is a public dataset used by Federal statistical agencies in classifying business establishments for the purpose of collecting, analyzing, and publishing statistical data related to the U.S. business economy.
- Databricks’ internal use case taxonomy curation datasets. This is a series of internal datasets created by our solution architects to show customers best practice architectures.
Then we synthesized CREATE TABLE statements using the above use cases to yield a diverse set of tables and generated sample responses including table descriptions and column comments using another LLM. In total, we generated ~3600 training examples.
Notably, we didn’t use any customer data for training this powerful feature that all of our customers can benefit from.
Bootstrapping model evaluation
After the feature launch, we could measure a model’s quality through production metrics such as the rate of users accepting the suggestions. But before we made it to the launch, we needed a way to evaluate the model’s quality against that of the SaaS LLM.
To do that in an unbiased fashion, we set up a simple double-blind evaluation framework in which we asked 4 employees to rate table descriptions generated from the two models we wanted to compare using a set of 62 unseen tables. Our framework then generated a sheet where each row showed the input and showed both outputs in a randomized order. The evaluator would vote on the better sample (or give a tie). The framework then processed the votes from different evaluators to generate a report; it also summarizes the degree to which each of the evaluators agreed.
Based on our experiences so far, having an evaluation dataset of tens to hundreds of data points is a sufficient initial milestone and can be generalized to other use cases as well.
Model selection and fine-tuning
We considered the following criteria for model selection:
- Whether the license supports commercial use
- Performance (quality) of the model for text generation
- Speed of the model
Based on these criteria, MPT-7B and Llama2-7B were the leading candidates, as shown in our LLM guide. We considered larger models such as MPT-30B and Llama-2-13B. In the end we chose MPT-7B, as it has the best combination of quality and inference performance:
- There was no discernable difference in the quality between the MPT-7B and Llama-2-7B fine-tuned models for this task.
- The smaller 7B models, after fine-tuning, were already meeting the quality bar. It was significantly better than the cheaper version of the SaaS model, and roughly equivalent to the more expensive version.
- We did not yet observe a measurable benefit of using larger models for this task that would justify the increased serving costs.
- The latency for the smaller models was significantly better than the larger models while offering comparable quality so we could deliver a much snappier product experience.
- The smaller model could fit comfortably and be served using A10 GPUs, which were more readily available. Their abundance would mean higher inference throughput for the task.
The total time it took to finetune the model on the ~3600 examples was only around 15 minutes!
While we chose MPT-7B for our model, we believe the LLM landscape is changing rapidly and the best model today won’t be the best model tomorrow. That’s why we consider this to be an iterative and continuous process and are focused on using tools that make our evaluation efficient and fast.
Key architectural components of our production pipeline
We were able to build this quickly by relying on the following key components of the Databricks Data Intelligence Platform:
- Databricks LLM finetuning. It provides a very simple infrastructure for fine-tuning the models for our task. We prepared the training data in JSON format, and with a one-line CLI command, we were able to fine-tune the LLMs.
- Unity Catalog: The models that we use in production are registered in Unity Catalog (UC), providing the governance we need to not just for the data, but also the models. With its end-to-end lineage feature, UC also gives us traceability from the models back to the datasets they are trained on.
- Delta Sharing: We used Delta Sharing to distribute the model to all production regions we have around the world for faster serving.
- Databricks optimized LLM serving: Once the models are registered in UC, they can be served using the new optimized LLM serving, which provides significant performance improvement in terms of throughput and latency improvement compared to traditional serving for LLM serving.
Cost
The fine-tuning compute cost for the whole project was less than $1000 (each fine-tuning run cost only a few dollars). And the final result is a more than 10-fold reduction in cost. Why is the cost-saving so significant? It is not surprising if we consider the following:
- As mentioned earlier, the SaaS LLMs need to address all the use cases, including acting as a general chatbot. The generality requires an extremely large number of parameters, which incurs significant compute costs in inference.
- When we fine-tune for a more specific task, we can use a much smaller prompt. Larger, general-purpose models require longer prompts that include detailed instructions on what the input is and what form the output should take. Fine-tuned models can bake instructions and expected structure into the model itself. We found we were able to reduce the number of input tokens with no impact on performance by more than half.
- Inference costs scale with the number of input and output tokens, and costs scale linearly for SaaS services that are charged per token. With Databricks’ LLM Serving offering, we offer provisioned throughput charged per hour, which provides consistent latencies, uptime SLAs, and autoscaling. Because smaller LLMs can fit in smaller GPUs that are much cheaper and more available and because we offer a highly optimized runtime, we can aggressively drive down costs. Also, smaller LLMs scale up and down faster, meaning we can quickly scale up to meet peaks of demand and aggressively scale down when usage is lighter, creating substantial cost efficiency in production.
Conclusion
Having well-documented data is critical to all data users, and growing more important day-by-day to power AI-based data platforms (what we’re calling Data Intelligence). We started with SaaS LLMs for prototyping this new GenAI feature but ran into challenges with quality, performance, and cost. We built a bespoke model to do the same task at better quality, and yet resulting in higher throughput with scale-out and 10x cost reduction. To recap what it took:
- 2 engineers
- 1 month
- Less than $1000 in compute for training and experimentation
- MPT-7B finetuned on 3600 synthetically generated examples, in under 15 minutes
- 4 human evaluators, with 62 initial evaluation examples
This experience demonstrates how easy it is to develop and deploy bespoke LLMs for specific tasks. This model is now live on Databricks in Amazon Web Services and Google Cloud and is being used to power most data annotations on the platform.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.