Creating a Community of Industry Practitioners With Databricks Solutions Accelerators
by Antoine Amend, Rob Saker, Nicole Jingting Lu, Sam Steiny and Vaibhav Sethi
Photosynthesis is the process that transforms carbon dioxide, water and energy into sugars and oxygen. Harmful on its own, CO2 is transformed into something human beings could not live without. The same happens today with enterprise data and innovation. Just like carbon dioxide, data can be toxic for many industries that fail at converting it into commercial insights quickly. Today's most iconic companies are not successful 'just' because of the quantity of data they collect or the competencies of their data science team. They succeed because of their ability to embed data science into their core business processes as well as connect business, science and technology teams. Data photosynthesis is the ability for an organization to convert raw data into commercially valuable insight to deliver business value such as improving margins, creating new products, and innovating faster.
Solution accelerators, a catalyst to data photosynthesis
Proud of 200+ years worth of industry experience combined within our industry team, we wanted to offer more than just a performant platform, but a true destination for each of our 7,000 customers to solve industries' most pressing data challenges. In the last two years, we released over 50 solutions accelerators and successfully launched four industry Lakehouses with two more underway – a platform that delivers partner solutions, use-case accelerators, and data monetization capabilities designed to address the unique requirements the specific industry (see example of Lakehouse for Financial Services) - as a means to bring business and technology closer together through data partnership, industry standards and best practices, use case examples and reusable libraries.

Available in the form of fully functioning notebooks, these solutions accelerators address business challenges we observe daily – from risk management in financial services, churn prevention in consumer goods, digital pathology in healthcare or gaming toxicity in media. Underpinning our solutions are technical concepts, reference architectures and technical building blocks spanning from geospatial analysis, time series processing, computer vision, natural language processing, etc.
Given that no two customers are the same, our solutions are not meant to be used as off the shelf products but are carefully designed as educational material to accelerate innovation through industry blueprints and best practices, showing our customers the art of the possible and helping them reduce time to value across common business use cases. For instance, our solution accelerator for ESG investing (environmental, social, governance) was downloaded over 40,000 times in the last two years and has been used to kickstart many strategic initiatives across different industries, contributing to a more sustainable future for many organizations and their respective customers.
Creating a community of practitioners
However, making code publicly available on a website is not what truly defines an open source initiative. Most open source top-level projects are not just 'publicly facing' assets. Successful initiatives are built around the idea of creating a community of practitioners rallied behind the same vision, collaborating on new ideas, and contributing to its code base. Today, we are taking a step forward by open sourcing our solution accelerators to our entire community through the use of Github organization.
Available on github, anyone can access our content with minimal support, run our solution on a Databricks instance with one-click deployment, and interact with our community of practitioners through live discussions or active issues tracking.
Databricks repository
Although specific solutions can always be downloaded as .dbc archives from our websites, we recommend cloning these repositories onto your Databricks environment.
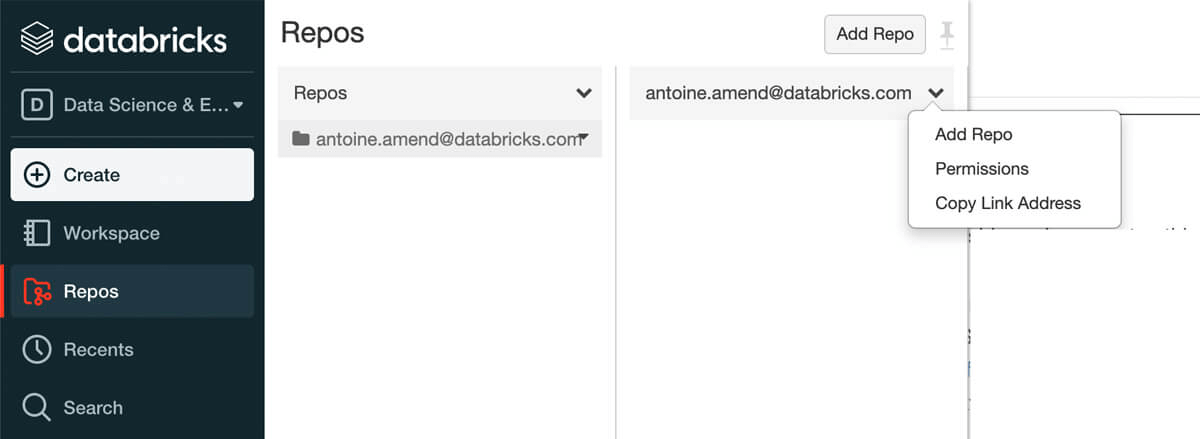
To start using a solution accelerator in Databricks, simply follow these steps:
- Clone solution accelerator repository in Databricks using Databricks Repos
- Familiarize yourself with the reference architecture and markdown files
- Execute sample notebooks, changing configuration as you see fits
- Modify the samples in the solution accelerator to your need, collaborate with other users internally and run the code samples against your own data.
To collaborate further, start by changing the Git remote of your repository to your organization's repository. You can now commit and push code, collaborate with other user's via Git and follow your organization's processes for code development. Ultimately, you can request a change to the solution repository through the use of pull requests and contribute back to your industry.
Get Started
Check out our solution accelerators on our github organization and stay up to date with latest industry trends and reusable solutions. Do not hesitate to like, comment, suggest changes and become part of a community of industry practitioners driving the future of our respective industries – accelerating data photosynthesis – collaboratively. You can help deliver business value to your firm: create new products, grow revenue and innovate faster.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.