A data architecture pattern to maximize the value of the Lakehouse
by Bernhard Walter, Magnus Pierre, Marco Scagliola and Matthieu Lamairesse
One of Lakehouse's outstanding achievements is the ability to combine workloads for modern use cases, such as traditional BI, machine learning & AI on one platform. This blog post describes an architectural pattern that mitigates the risk of "two silos on one platform". Following the approach outlined in this blog, data scientists using Machine Learning and AI will have easy access to reliable data derived from the organization's business information model. At the same time, business analysts can leverage the capabilities of the lakehouse to accelerate the delivery of data warehouse (DWH) projects while keeping the core enterprise data warehouse (EDW) stable and conforming.
We will introduce the concept of semantic consistency, which helps to bridge the two worlds of the data lake and the DWH:
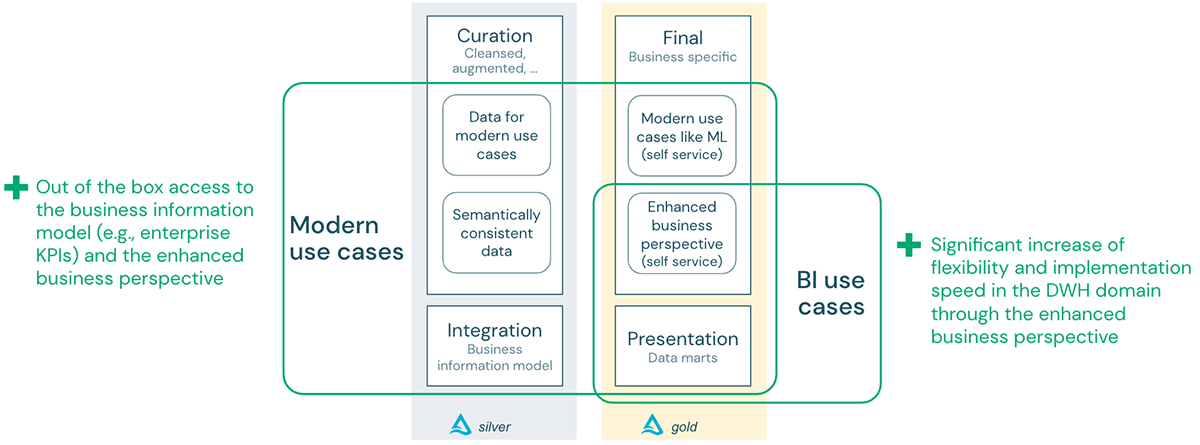
The background
In this blog post, we will distinguish between modern use cases on a data lake and traditional BI use cases on data warehouses:
Data lake for modern use cases: Modern use cases typically involve machine learning and AI on data stored in a data lake. Both approaches aim to create models that predict behaviors or possible outcomes so that business users can take appropriate action ahead of time.
Machine learning models are trained (supervised or unsupervised) on data sets and optimized to find patterns or make predictions from previously unseen data sets. Deep learning is a subset of machine learning that uses algorithms inspired by the structure and function of the human brain. It is part of a broader family of machine learning methods based on learning data representations instead of traditional task-specific algorithms. Machine learning often uses large data sets that are explicitly ingested for the use case into the data lake.
Data warehouses are data management systems that store current and historical data from multiple core business solutions. They are modeled after how an organization conducts business, allowing for easy insight and reporting. They extract and aggregate data from operational databases for BI, reporting, and data analysis. The benefits of data warehouses include consolidating data from many sources, providing historical information, and separating analytical processing from transactional databases. They ensure data quality and accuracy and standardize data by providing consistency, e.g., via naming conventions and codes for different product types, languages and currencies.
Building a data warehouse follows a rigorous and governed process: Business actors and processes are modeled in a business information model. The data flowing through this model is reflected as a logical data model (technology agnostic) and then implemented as a physical data model depending on the database technology of the data warehouse. This process is relatively slow, but it transforms raw data (without business value) into data compliant with the overall business context and generates actionable and trustworthy business information.
Traditionally, data warehousing was an introspection of a company's business processes. Integrating data from those processes typically contains master data unique to the company such as customer inventory, contracts and the like. As more and more data available to us is external data, the need to model this data is much less for several reasons:
1) it is not our data and does not describe our processes,
2) we may not fully understand how it relates to our "core data", and
3) it describes something external to the company that we may want to react to (data signal) but should not be elevated to the same level as "trusted information from business processes that we operate".
However, we still want to be able to augment our "enterprise view" with this data to gain new insights.
And … what is the problem?
Both platforms can provide tremendous value to the organizations that use them. However, many organizations struggle with data warehouse and data lake integration:
- The data warehouse and data lake are typically two silos with little or no interaction. Sometimes data is duplicated from the data lake to the data warehouse (or vice versa), creating data silos that create new problems.
- Accessing a data warehouse for modern use cases can be challenging and sometimes comes at a high cost (there may be fees for both the ML&AI platform and the data warehouse).
- Data warehouses usually lack support for built-in machine learning and AI capabilities. They are SQL-only and limited in their ability to store unstructured data, such as images, or semi-structured data, such as JSON.
- Data is often copied to the data lake without respect to overall consistency. This implies that data in the data warehouse and data in the data lake cannot be merged easily.
- The rigorous design process makes changes and enhancements to the DWH slow and expensive.
Bringing both worlds together in the lakehouse
As mentioned above, one of Lakehouse's outstanding achievements is the ability to combine workloads for modern use cases and traditional BI on one platform. This leads to several advantages.
So, let’s look at an example.
A large enterprise operates with Salesforce (CRM) throughout its Sales cycle. When a deal is closed, an order is created in Salesforce and forwarded to SAP via a process integration phase. The logic during process integration transforms the data for ‘order’ and ‘customer’ into the SAP data model context.
For reporting purposes, the data of both systems get ingested into the Lakehouse:
- SAP data, relevant for financial reporting, is integrated into the DHW part of the Lakehouse.
- Salesforce pipeline data is integrated into the data lake part for advanced analytics, and AI use cases in the Lakehouse.
The data sets are projected onto business-specific tables or BI data marts in the gold layer.
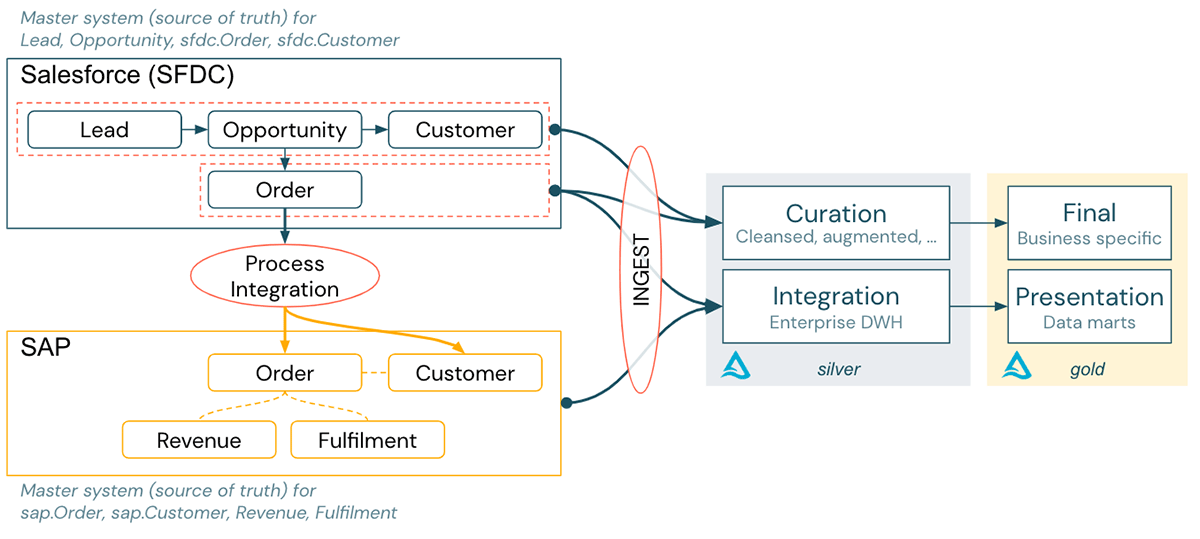
Given this setup, we will be able to create the following:
- A sales forecast report from the gold layer's business-specific data.
- A revenue recognition report from a data mart in the context of the overall financial reporting.
Both reports are independent, so combining data ingested from Salesforce and SAP is not necessary.
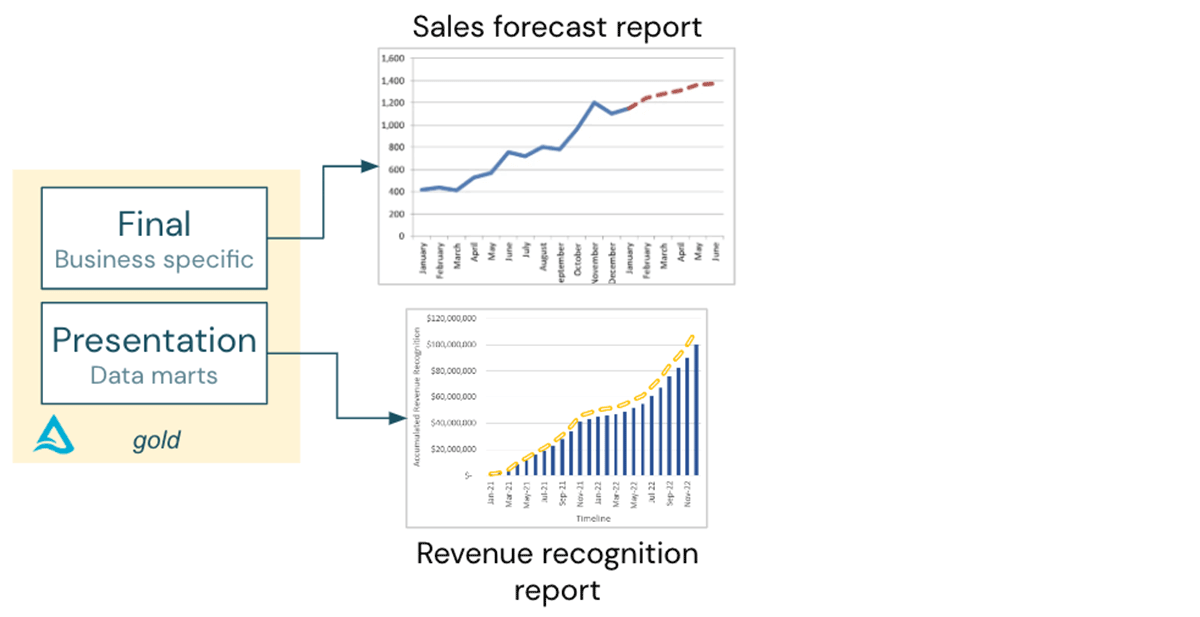
Now the CFO asks for a “revenue recognition forecast report”!
From a business perspective, the new request from the CFO requires modeling a canonical revenue recognition pattern for the company (typically, revenue gets recognized when a product or service has been delivered to a customer. Some services are provided over an extended period, so a model for recognized revenue over time is required). This model can be simplified but must be consistent with the implemented SAP revenue recognition logic.
From a data perspective, the revenue recognition forecast requires combining the sales pipeline data from Salesforce and the revenue data from SAP.
The “process integration” step mentioned before applies transformation and business logic to the Salesforce entities to comply with the requirements of the SAP data model. Hence, one cannot simply combine data from two systems in the Lakehouse since vocabulary and granularity will most probably differ.
There are two options
- Add the Salesforce objects into the Integration layer (i.e., enhance the business information and the data models). This approach is typically slow and can easily take months. Furthermore, these objects should only be added to the business information model once it is proven that this report is a necessary business asset.
- Merge data from the Integration layer (e.g., sap.order, revenue) with data from the curation layer (lead, opportunity, sfdc.order). However, this approach is only possible if the Salesforce tables in the Curation layer are semantically consistent with the data in the Integration layer.
Option 1 isn’t the easiest and fastest approach, so let’s understand option 2.
Semantic Consistency
What does semantically consistent mean?
As usual, data ingested into the data lake is cleansed as it moves from the ingestion layer to the curation layer. To make the data semantically consistent, it must also be aligned in terms of business context. For example, customer or revenue data from different systems must have the same meaning in both layers. And, on an appropriate level, the data must be de-duplicated.
This additional step ensures that semantically consistent data in the Curation layer can be securely merged with data from the Integration layer to provide business-ready tables in the gold layer: The revenue recognition forecast report can be successfully created, as shown in the following diagram.
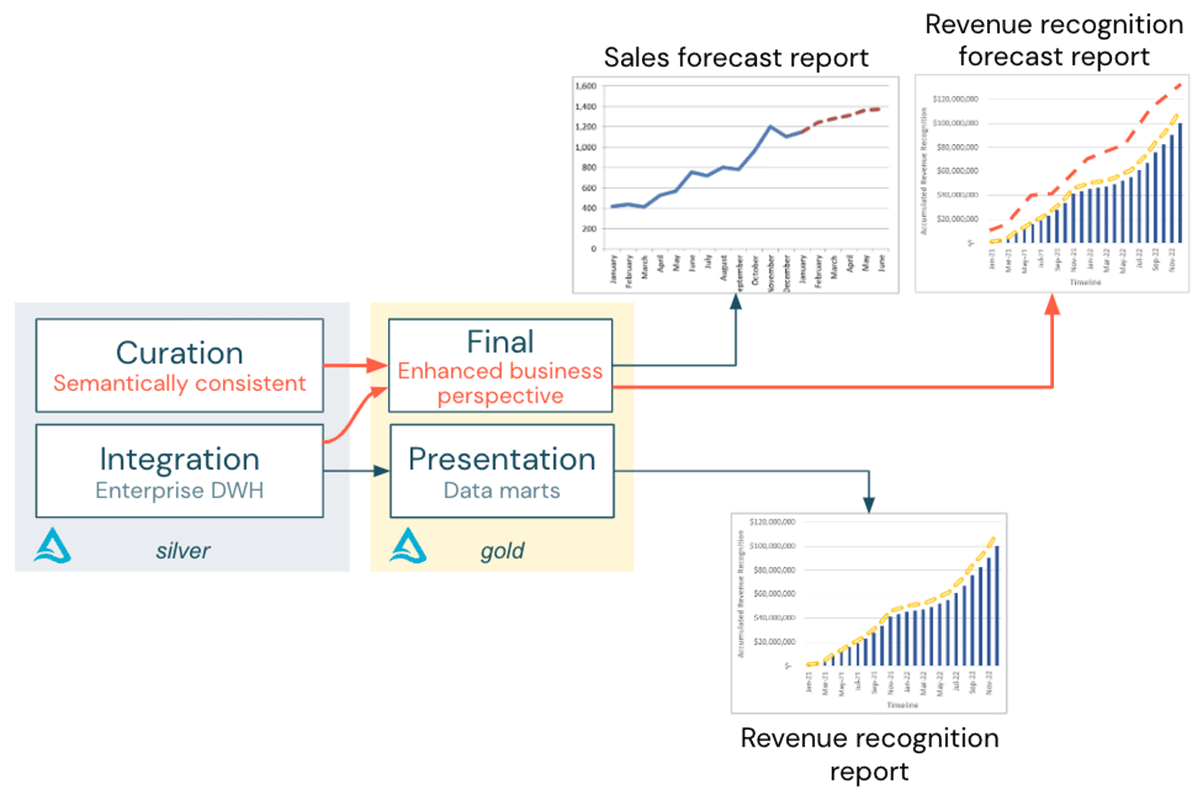
How to achieve semantic consistency?
Let's look again at the SAP and Salesforce example above. The first step we need to take is aligning terms and granularity of the tables that need joining:
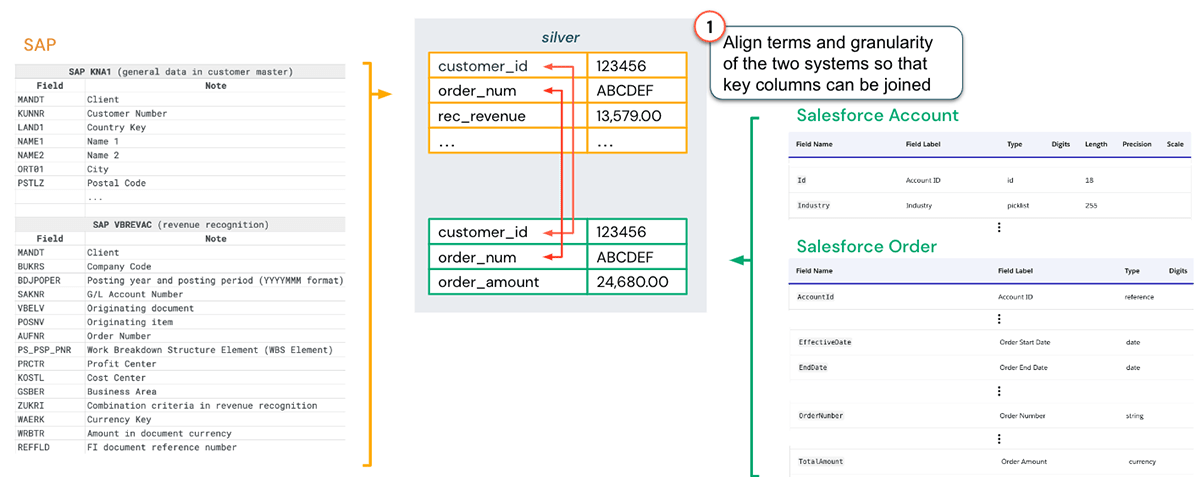
The next step is to build revenue recognition models. A key benefit of the Lakehouse is that data scientists can easily access the revenue recognition data from SAP stored in the data marts since the data is available in the same system (assuming the appropriate access rights are granted). Given this data, some standard revenue recognition profiles can be created, as shown in the figure below.

Now that terms, granularity and the revenue recognition profiles are aligned with data and logic in SAP, the data needed for the revenue recognition forecast report is semantically consistent and can be combined:
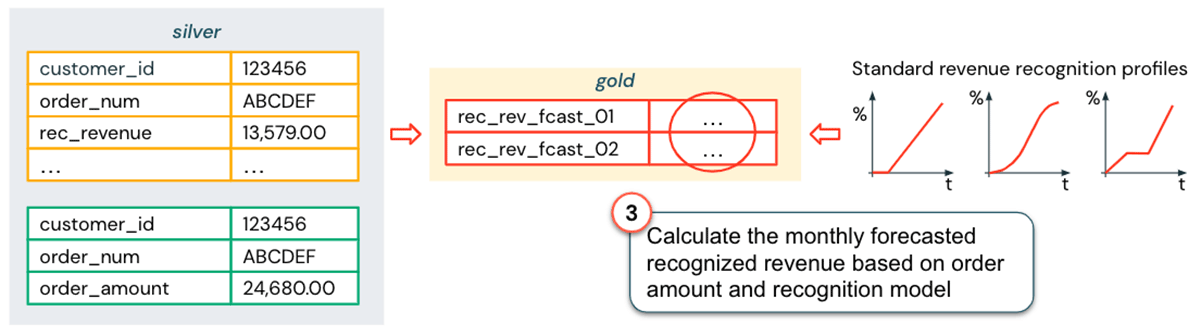
The process described above is simplified, but the general idea should be clear: instead of integrating Salesforce data holistically into the Business Information Model and the EDW, the Lakehouse allows us to implement analytics use cases in a faster and more flexible way: Until we are confident that this report is a standard part of financial reporting, we can use the semantic consistency approach (a much smaller effort than a full DWH integration) and build an "Enhanced Business Perspective" to complement the views within your standard data marts.
In this way, Lakehouse helps to bridge the exploratory and flexible world of the modern advanced analytics use case paradigm with the stable and conforming paradigm of the DWH world - with both worlds benefiting from operating under the same Lakehouse platform:
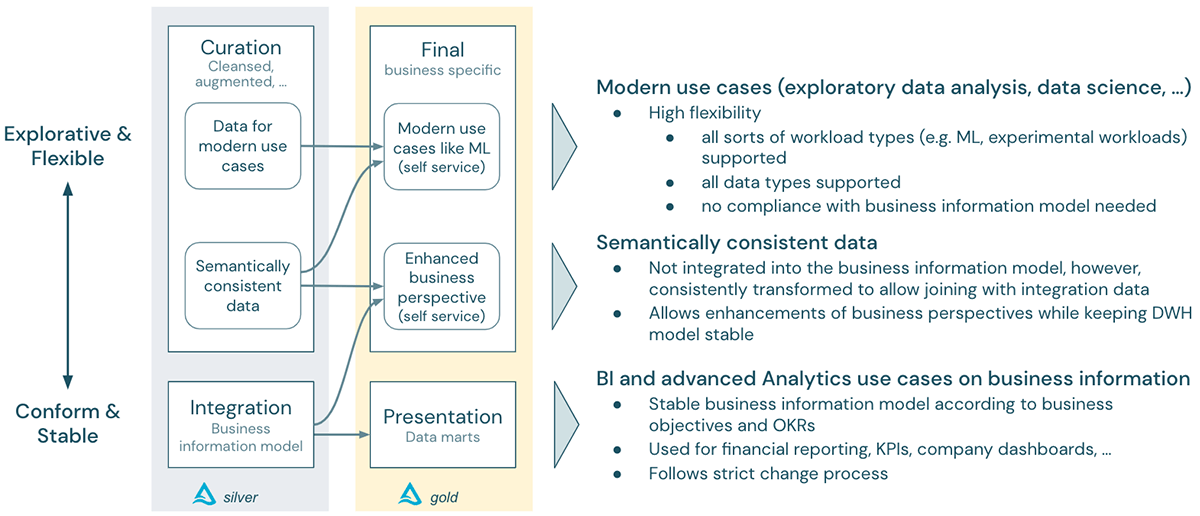
Summary
Many organizations struggle with the challenge of "two silos" when it comes to data warehouse and data lake integration. The lakehouse combines workloads for modern use cases, such as machine learning and AI, and traditional BI on a single platform. In this blog post, we introduced the concept of semantic consistency, which helps bridge the two worlds of the data lake and the DWH, avoiding the creation of "two silos in one platform".
Applying semantic consistency to data sets outside of the DWH layers that are to be combined with data in the DWH layers has several benefits:
- Achieving semantic consistency for data outside the DWH layers is much easier than integrating that data into the DWH.
- As a result, DWH development can be faster and more exploratory while the core DWH remains stable. And if a result has proven to be of lasting value, the data sets can be integrated into the DWH at a later time.
- Data scientists can easily access data derived from the organization's business information model, such as business KPIs, and combine it with semantically consistent data.
- Finally, not all data needs to be semantically consistent, so the fast and exploratory nature of the data lake approach is still available for modern use cases.
Over time we believe that the strictly modeled part of the business will be dramatically outgrown by the sources outside of the core business solutions. But the strictly modeled part of the business still carries lots of value to the organization and is crucial as the anchor point for getting trusted information from a modern data lakehouse.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.