Delivering the Right Care at the Right Time
How FHIR-Powered Advanced Analytics Helps Health Plans Drive Member Impact Across the Care Journey
by Vincent Tumminello and Matthew Giglia
- How FHIR-powered analytics and AI enable health plans to deliver the right care at the right time.
- Opportunities to streamline prior authorizations, reduce administrative burden, and improve member outcomes.
- Modernizing payer data foundations to achieve CMS interoperability compliance and unlock strategic business value.
Understanding the “right care at the right time” philosophy
Health plans and providers have always been aligned on the shared goal of providing the right care for their members or patients, at the right time. For health plans, that’s often meant approving services that will bring down medium and long term costs in the future, while providers often seek to do what's best for their patients’ today. What does “the right care at the right time” mean in the age of maturing interoperability?
Today, that means leveraging the power of advanced, predictive and prescriptive analytics to make care decisions faster, including for prior authorization, quality of care, coordination of care, or influencing the actions taken at the site of care. Using traditional machine learning (ML), a data science team may use real-time hospital transactions to predict the probability that a current patient may be at greater risk of readmission upon discharge or contracting sepsis with every transfer in the hospital. Generative AI agents can help assist in clinical decision support so that a clinician can better prescribe care plans for a member in care management based on a holistic representation of the member’s medical history, real-time interactions of every touch point, and leveraging evidence-based outcomes from data that augment care manager assessments and decision-making.
To achieve the “right care at the right time”, interoperability mandates such as Payer-to-Payer (CMS-9115-F, CMS-0057-F) promote continuity of care for the member as they switch health plans. By using HL7 FHIR, the plans can exchange not only claims and demographic information, but also historical clinical data and active care plans. The new plan, on day one, is equipped to make an informed decision about whether to continue the member on the existing care plan or enroll him/her in a new one. Additionally, the new plan will be able to learn how this new member population will impact risk adjustment through calculated hierarchical condition categories, HEDIS and other quality scores, currently attributed primary care physicians for value-based payment initiatives, network adequacy and every other analytic that the health plan creates today for their members. Historically, this would have required significant claims runout to perform accurately.
Better care, reduced burden: The payoff from electronic prior authorization
The CMS-0057 electronic prior authorization mandate offers a significant opportunity to improve collaboration between healthcare providers and payers. By leveraging widely adopted EHR systems and FHIR data exchange standards, providers can seamlessly submit service or medication approval requests directly from the EHR that not only contains the details of the request, but all of the supporting evidence to meet health plan authorization requirements.
For example, a GLP-1 medication request may require that several other medications have been prescribed previously without a significant reduction in HbA1c for Type 2 Diabetes. Today that may require a survey-like criteria form to be completed first, asking if the patient was prescribed metformin and the patient’s quarterly HbA1c values before and after the initial prescription. This may be followed by requests of scanned or faxed diagnostic reports showing little-to-no change or even a request for a direct interaction between the provider and a health plan medical director to discuss the case in lieu of reviewing the provider’s clinical notes.
This back and forth between the payers’ utilization management team and the provider is inefficient and creates a costly and time-consuming administrative burden. With FHIR, the prescription fills (pharmacy claims), clinical notes, and the diagnostic reports may be packaged up as additional resources in the original GLP-1 medication request, allowing the payer to have all of the relevant data needed to make a decision immediately. Providing the evidence directly from the EHR, along with the request in the FHIR bundle, enables payers to analyze and approve requests using the patient's source of truth data in a more deterministic way, turning the traditional survey-like criteria into business rules.
This paradigm shift will conserve administrative time for providers, minimize errors, and facilitate transparency, potentially leading to auto-approvals or significantly reduced approval times for payers. For complex cases, payers can utilize ML and generative AI to enrich information for utilization management nurses and medical directors, turning the authorization process into an opportunity for personalized patient care. Ultimately, fewer manual reviews, coupled with superior data and insights, translate to expedited approvals, diminished costs, reduced administrative burdens, and increased satisfaction for patients, members, and providers.
Bi-directional data exchange: Care coordination across the ecosystem
Together, both mandates open the lines of communication between payers and providers to collaborate and align on patient outcomes through clinical data exchange. For example, using machine learning, a payer may recommend or even schedule a health screening or laboratory visit for a member to confirm a likely new diagnosis or to prevent a likely near-term adverse event. Using generative AI and AI agent frames, the observation may be packaged as a FHIR transaction bundled with any supporting information from the ML model’s features. The FHIR bundle may then be sent to the provider’s EHR for scheduling or to provide insights at the site of care in support of value-based payment agreements or initiatives. In the case of Admit, Discharge & Transfer (ADT) transactions, this bi-directional opportunity for improving patient outcomes may be conducted in near real time.
Can your data platform keep up?
The data required to enable payer-provider partnership comes from many disparate sources and systems, and in different formats. Not only is this a challenge inside a single organization, but this complexity compounds exponentially when exchanging disparate data, in different formats, and from multiple sources, between many organizations.
Truly, the ability for all healthcare organizations to exchange data quickly opens the doors for better patient outcomes, preventive care, and therefore cost savings. However, generating, ingesting, parsing, and joining FHIR-transmitted data to other potentially required data can still be a challenge. A major barrier to participating in robust payer-provider partnerships is antiquated and often siloed data infrastructures at the core of payer IT organizations. Many core administrative systems are still on-prem, are not able to scale or readily centralize data in more nimble cloud-based data and analytics environments. These systems also leverage proprietary data structures that are not necessarily intraoperable to other data types or supportive of interoperable standards and exchange protocols.
The FHIR format’s extensibility means that it may serve as a superset for all clinical data exchange, allowing each of these organizations to convert and standardize on one data format. To successfully generate all of the possible resource types to include in FHIR bundles, an organization needs a well-governed and centralized lakehouse architecture to integrate all of the elements together. This may require updates in near real-time such that clinical decision makers have the most up-to-date clinical data exchanged at their fingertips. Ingesting and parsing of FHIR needs to be efficient, not only for use in applications, but also to be readily available for analytics and machine learning. While excellent for transacting between organizations, the FHIR format presents significant challenges for analysts and data scientists to use in its native form.
Examples of this interoperability in action
While FHIR standardizes many concepts for clinical data exchange in the form of resource types, it leaves open for interpretation exactly which elements of the resource types must be consistently populated and how. For example, to achieve extensibility and flexibility, many of the resource types contain an “extension” element allowing any additional data to be included that’s deemed relevant but isn’t formally modeled in the resource type itself. The "extension" element may also include an extension itself, allowing for deeply nested data points without a consistent schema. Often these extensions may contain critical information such as birth sex, gender, race or ethnicity that's required for NCQA reporting. Additionally, the order and number of resource types in the bundle may vary between bundle types, and the organization generating it. Together this means that the standard “schema on read” methods don’t work on more than one FHIR JSON file as each presents its own unique schema. The disparate origins of clinical data, spanning multiple organizations, present challenges in integrating it with existing enterprise data. These challenges stem from variations in unique person identifiers between organizations and the potential for duplicate data entries that appear distinct due to incompleteness or differing representations of identical information across various systems such as one using SNOMED and another using ICD-10 for a diagnosis. Due to these issues, many organizations have struggled to harness the power of their clinical data for use in the analytics use cases mentioned above.
Abacus Platform Architecture
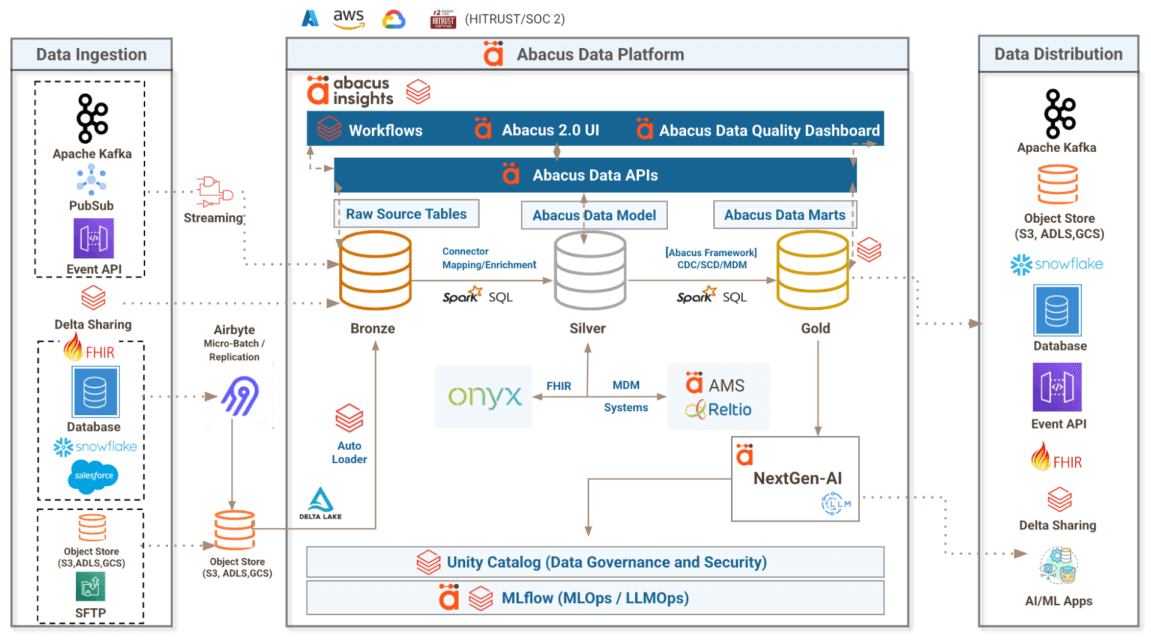
Modernizing your payer data foundation ahead of CMS-0057-F deadlines
To address unique payer data challenges, Abacus Insights partners with Databricks to deliver a modern, cloud-based payer data management platform that supports interoperability at scale. The usable data foundation of the Abacus payer data supports payers in complying fully with the CMS Interoperability and Prior Authorization mandate while unlocking strategic business value beyond compliance. With the Abacus platform, key clinical and administrative data required to operationalize CMS-0057 APIs, can be enriched, transformed, and purposed to enable business use cases beyond compliance - quality management, risk adjustment performance, financial reporting and reconciliation, population health/value-based care analytics, etc.
Abacus’s mission is to liberate data silos and enable real-time collaboration between payer and provider organizations - an aim that builds upon the requirements of the CMS-0057-F Mandate. Our cloud-based data platform is capable of migrating data from those core administrative systems to the cloud and unifying disparate data structures in a use-case-agnostic manner, enabling payers to use a single data feed for any use case. The core competency is integrations between many disparate systems, both within a payer’s core infrastructure as well as to their external systems of insights and provider partners. Together, these capabilities create a future-proof data foundation that supports compliance today and competitive innovation tomorrow. —Vinny Tumminello, AVP, Solution Strategy - CMS Interoperability, Abacus Insights
At Databricks I'm often asked not only about the best way to ingest and integrate all of the disparate data sources required for advanced analytics and AI applications, but also what's the best way to model that data. When I think about Abacus and their unique Built on Databricks offering, it's about going from zero-to-sixty on a well-architected and maintained lakehouse that integrates 85% or more of what analysts and data scientists at a payer will need to get started on clinical data use cases. It's about time-to-value, and when you deploy Abacus in your Databricks account you get the same centralized governance and security with Unity Catalog for all your data and AI assets without any of your clinical data leaving your tenant. —Matthew Giglia, Solutions Architect, Databricks
Turn CMS interoperability compliance into a strategic business advantage
As we look to January 2027 as the effective date of the CMS-0057-F Interoperability and Prior Authorization mandate, the question is not purely one of compliance. It is, will payers seize the call-to-action moment facilitated by CMS compliance to modernize their infrastructure, enabling more real-time operational and analytical use cases that bridge the coordination gap between payers and providers? Or will this be another Patient Access (CMS-9115-F) experience - long implementation timelines, minimal adoption, and limited business value beyond CMS compliance?
Our mission is to enable payers to not only check the compliance box, but to also to facilitate modernization of their data foundation to extract greater value from their data. Together, we help enable business use cases that focus strategically on driving outcomes and experience while addressing the rapidly rising cost of care.
Get in touch with us to see how Abacus on Databricks can accelerate your interoperability use cases.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.