Distributed ML for IoT
by Josh Melton
Introduction
Today, manufacturers’ field maintenance is often more reactive than proactive, which can lead to costly downtime and repairs. Historically, data warehouses have provided a performant, highly structured lens into historical reporting but have left users wanting for effective predictive solutions. However, the Databricks Data Intelligence Platform allows businesses to implement both historical and predictive analysis on the same copy of their data. Manufacturers can leverage predictive maintenance solutions to identify and address potential issues before they become business critical customer facing problems. Databricks provides end-to-end machine learning solutions including tools for data preparation, model training, and root cause analysis reporting. This blog aims to shed light on how to implement predictive solutions for IoT anomaly detection with a unified and scalable approach.
Problem Statement
Scaling existing codebases and skill sets is a key theme in developing IoT predictive maintenance solutions given the massive data volumes involved. We often see businesses experience an increase in defect rates without a clear explanation. While there may already be a team of data scientists who are skilled in using Pandas for data manipulation and analysis on small subsets of their data - for example, analyzing particularly notable trips one at a time - these teams can easily apply their existing code to their entire large-scale IoT dataset by using Databricks. In the examples below, we’ll highlight how to deploy Pandas code in an easily distributable way, without data scientists having to learn a completely new set of tools and technologies to develop and maintain the solution. Additionally, ML experimentation often runs in silos, with data scientists working locally and manually on their own machines on different copies of data. This can lead to a lack of reproducibility and collaboration, making it difficult to run ML efforts across an organization. Databricks addresses this challenge by enabling MLflow, an open-source tool for unified machine learning model experimentation, registry, and deployment. With MLflow, data scientists can easily track and reproduce their experiments, as well as deploy their models into production.
Example 1: Running Existing Anomaly Detection Code on Databricks
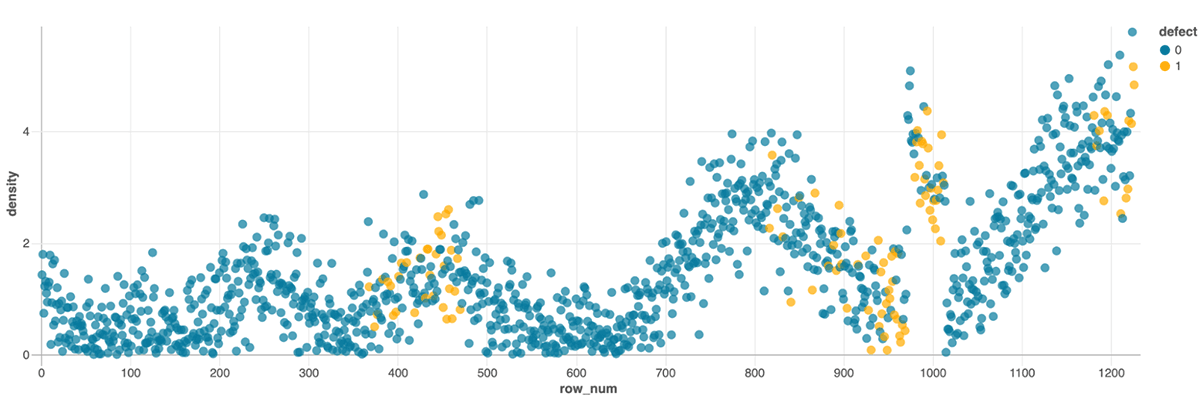
To illustrate how to use Databricks for IoT anomaly detection, let's consider a dataset of sensor data from a fleet of engines. The dataset includes sensor readings such as temperature, pressure, and oil density, as well as a label indicating whether or not each data point signaled a defect. For this example, we’ll take the existing code that runs on a subset of our data. Our aim is to migrate some existing, single node code which we’ll eventually run in parallel across a Spark cluster. Even before we scale our code, we get the benefits of a collaborative interface that enables tooling such as in-notebook dashboarding for exploratory analysis, and Databricks Assistant for code writing and troubleshooting.
In this example, we copy Pandas code into a Databricks notebook with one simple addition for reading the table from our organization’s unified data lake, and immediately get a point and click interface for exploring our data:
Example 2: MLops for Production
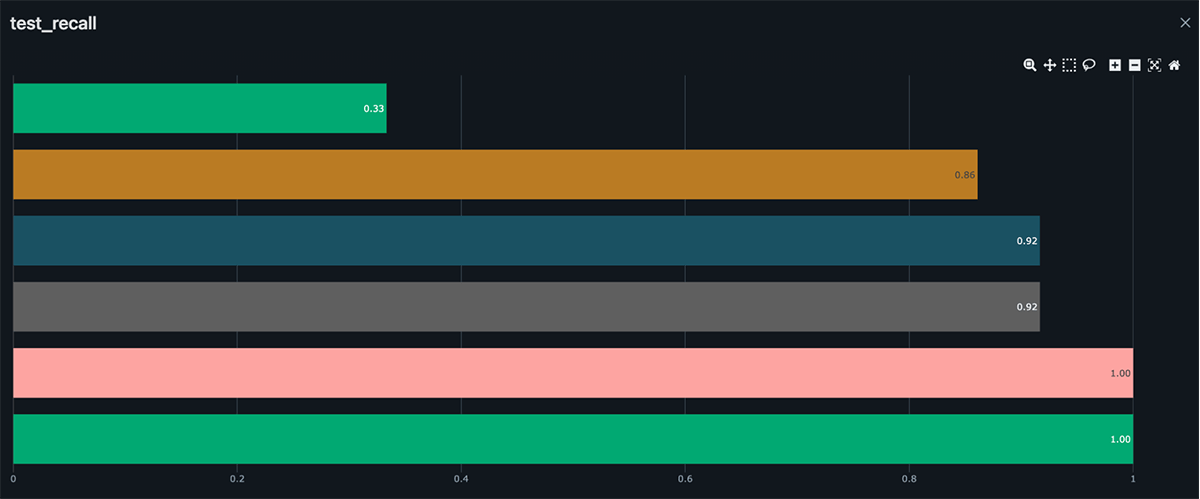
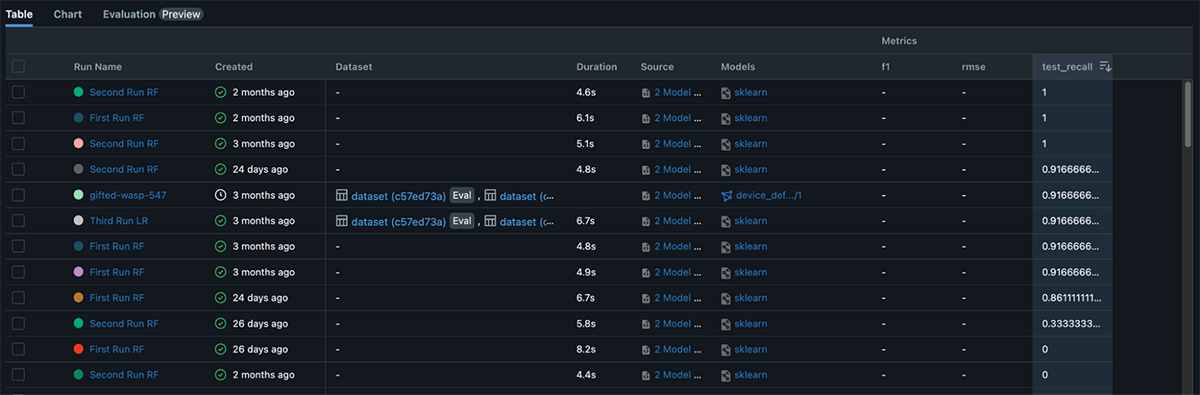
Next, we’ll use Databricks and MLflow to easily track and reproduce your experiments, allowing you to iterate and improve on your model over time. Our goal is to build a machine learning model that can accurately predict whether a given data point is a defect based on the sensor readings, without having to replicate data and models across different teams, roles, or systems. By adding a simple autolog() function, you can automatically track information about each attempt to solve an ML problem such as model artifacts, library dependencies, model parameters, and performance metrics. We can use these models to help identify and address engine defects before they become a major issue, in batch or real time pipelines.
Example 3: Distributing Pandas on Spark
Now that we’ve ported our existing code to Databricks and enhanced the tracking, reproducibility, and operationalization of our ML models, we want to scale them across our entire dataset. You can’t beat the performance of Apache Spark for distributed computing, but data scientists often don’t want to learn another framework or alter the code they’ve already developed. Fortunately, Spark offers various approaches to horizontally scaling Pandas workloads to run across your entire dataset. We’ll explore three different options below:
a. PySpark Pandas
In this example, we’ll use PySpark Pandas to use the same code for building features from Example 1, but this time it will run in parallel across many nodes on a Spark cluster. Your code can use this parallelization to efficiently scale with massive datasets, without rewriting the logic. Note that the code is identical to Example 1 apart from the pandas import statement and using pandas_api() instead of toPandas() to define the DataFrame.
b. Pandas UDFs
PySpark Pandas doesn’t cover every use case for Pandas - at times, you’ll need more granular control over your operations or use a library that doesn’t have a PySpark implementation. We can use Pandas UDFs for these cases. A Pandas UDF allows us to create a function that accepts a familiar object, in this case a Pandas Series, and operate on it as we would locally. At execution time, however, this code will run in parallel across the Spark cluster. The only code change we need to make is to decorate our function with @pandas_udf. In this example, we’ll use an ARIMA model to make temperature forecasts in parallel to add a feature with higher predictive value to our dataset.
c. applyInPandas
Rounding off our approaches to parallelizing Pandas code is applyInPandas. Similar to the Pandas UDFs approach in Example 3b, applyInPandas allows you to write a function that accepts a familiar object (an entire Pandas DataFrame) and takes care of distributing the execution of the code across the Spark cluster. In this approach, however, we start by grouping by some key (in the example below, device_id). The grouping key will determine which data is processed together, for example all the data where device_id is equal to 1 gets grouped into one Pandas DataFrame, device_id equal to 2 is grouped into another Pandas DataFrame, etc. This allows us to take code that previously ran on one device at a time and scale that out across an entire cluster, which significantly accelerates the processing of data at scale. We also provide the expected output schema of our applyInPandas function so that Spark can leverage PyArrow to serialize the results in an efficient way. In this simple example, we’ll take an exponentially weighted moving average for each device’s fuel density and forward fill any null values:
Conclusion
In conclusion, using Databricks for IoT predictive maintenance offers a number of benefits, including the ability to easily scale ML workloads, collaborate across teams, and deploy models into production. By using Databricks, data scientists can apply their existing Pandas skills and code to work with large-scale IoT data, without having to learn a completely new set of technologies. This allows them to quickly build and deploy IoT anomaly detection models, helping to identify and address engine defects before they become a major issue. In short, Databricks provides a powerful and flexible platform for data scientists to apply their existing Pandas skills to large-scale IoT data. If you're a data scientist or data science leader looking to scale your data and AI workloads, try our Distributed ML for IoT solution accelerator and improve the effectiveness of your predictive maintenance initiatives.
Here is the link to this solution accelerator.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.