Driving Data Usability for Health Plans through Simplified Data Quality Enforcement with Databricks
by Navdeep Alam and Mohit Sauhta
This is collaborative work from Abacus Insights and Beesbridge, the delivery partner for Databricks.
Faced with clinician shortages, an aging population, and stagnant health outcomes, the healthcare industry has the potential to greatly benefit from disruptive technologies such as artificial intelligence. However, high quality and usable data are the lifeblood of any advanced analytics or machine learning system, and in the highly complex healthcare industry, data quality (DQ) has historically been poor, with limited standards and inconsistent implementations. With the potential to impact a patient's care and health outcomes, making sure healthcare data is of high quality and usable couldn't have higher stakes. As a result, healthcare companies need to ensure their foundational data is truly usable – defined as accurate, complete, timely, relevant, versatile and use case and application agnostic – before using it to train advanced machine learning models and unlock the promise of artificial intelligence.
Abacus Insights, as a healthcare technology leader with the only data transformation platform and solutions built specifically for health plans, has a core competency and value proposition of integrating data silos and delivering usable data. To solve the data quality challenge, we introduced the concept of Data Grading where the data is augmented with a data quality score, ensuring that downstream consumers of the data understand its degree of usability. The natural corollary of that score is to have Process Transparency that allows our customers to interpret the results. This blog post will walk you through the high-level details of how we have implemented these concepts using Spark, and Delta Lake on the Databricks platform.
Process Transparency
Data grading is the outcome of data quality rules that can be applied on the raw data from the source system in Bronze layer, as well as the data that is transformed and enriched in Silver layer. We'll first explore the construction of a data quality rule engine that enables the end-user in the business to interpret the DQ rule and thereby promotes process transparency. Then we can go into detail on how this engine is implemented using Spark and Delta Lake on the Databricks platform.
We'll also show how the data quality is continuously improved in Databricks' medallion architecture as the data is curated with the help of the data quality rule engine, and then published as a trusted asset to drive downstream analytics and machine learning use cases. The following diagram shows the high-level flow of data quality in the medallion architecture.
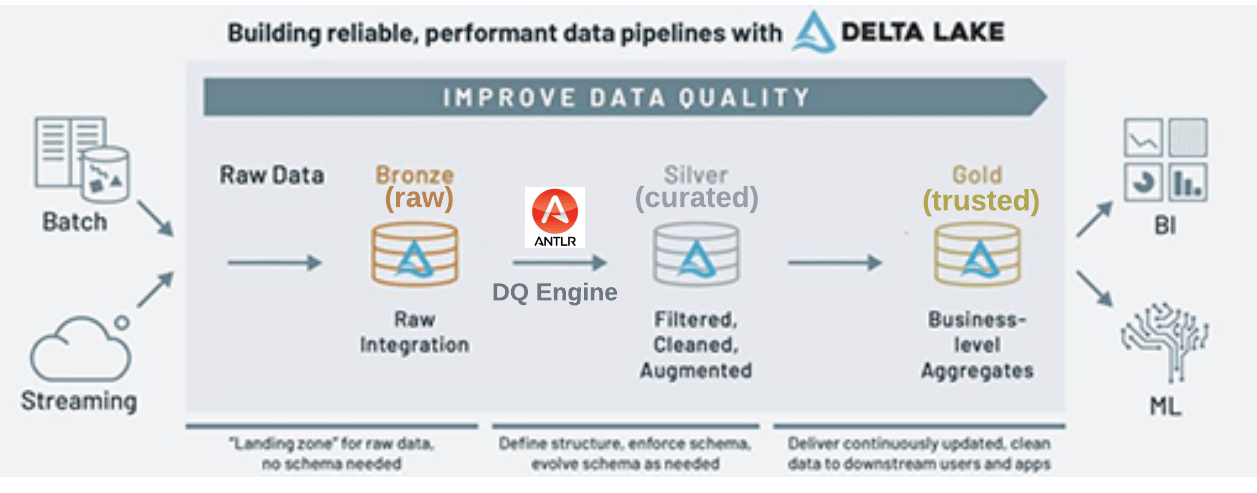
Data Quality Rule Engine
One thing to know is that Grammar is a key component to build appropriate data quality rules. One can also build such rules in most of the popular data quality tools/libraries - after all, these tools provide a rich visual interface and useful report outputs. The Databricks platform provides the necessary flexibility to build these custom-built data quality solutions that support both Batch and Streaming workloads. The grammar enables the DataOps engineer to express the data quality rules in a simple and intuitive manner that can be interpreted by a non-technical user. It also allows the generation of efficient Spark code that can be run natively using Dataframe API along with the data engineering pipelines.
Harnessing the power of ANTLR on Databricks Platform
Databricks' platform is built on open standards like Spark and Delta that can be extended easily to support specialized use cases by using other custom libraries, framework, or methodologies. One of the more popular examples is how the Databricks platform was able to fine-tune an open-source Large Language Model, Dolly 2.0, for only $30. Similarly, we have integrated a powerful parser generator ANTLR, a tool that takes grammar as input and automatically generates source code that can parse streams of characters using the grammar. As a result, we were able to use the power of Spark and Delta Lake to build and deploy an English-like grammar for a data quality rule engine. In particular, the distributed compute and open framework of Spark enables the execution of the following end-to-end flow in a scalable manner.
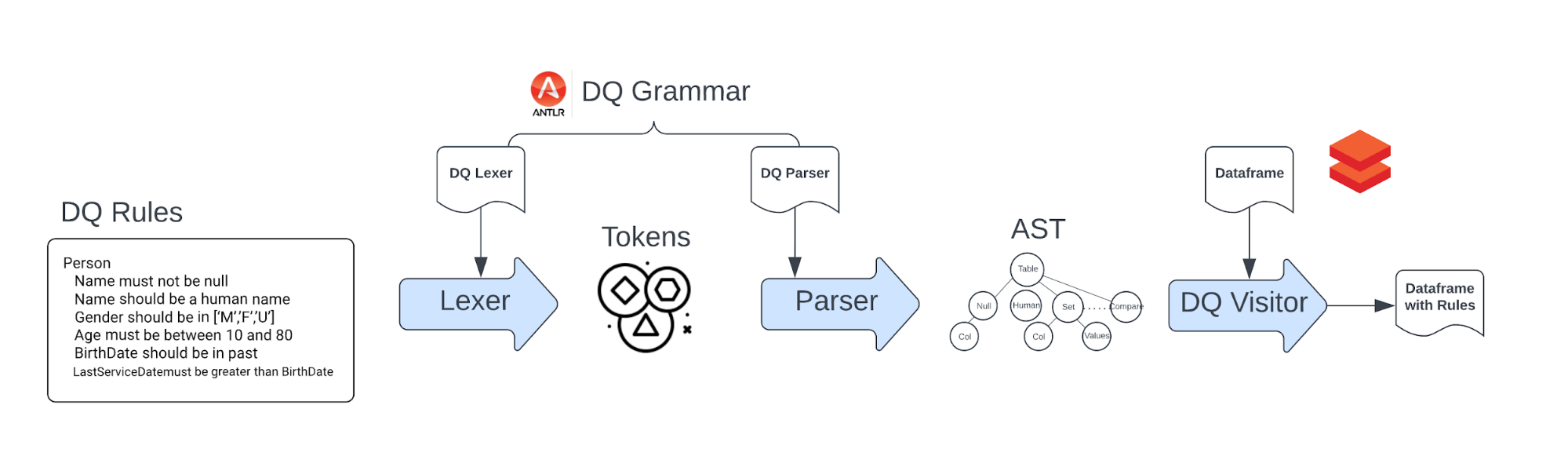
Implementation Details
The implementation of Data Quality Rule engine is constructed using the following components:
- DQ Grammar : Builds the domain specific language for data quality rules.
- DQ Rules : Defines the data quality validation checks.
- DQ Parser : Parse the data quality rules to generate Rule Abstract Syntax Tree (AST), and calls ParserVisitor for each node in the AST.
- DQ Visitor : Constructs the Spark code incrementally for each node in the AST.
DQ Grammar
Data Quality grammar is expressed using ANTLR grammar. ANTLR is a powerful parser generator for reading, processing, executing, or translating structured text or binary files. It is widely used to build languages, tools, and frameworks. The grammar itself is made up of two parts: Lexer and Parser rules.
Lexer Grammar: Used to define the tokens that are used to build the grammar. Here is the snippet of the tokens and literals used in the grammar.
DataQualityLexer.g4
Parser Grammar: Used to define the grammar rules. Here is the snippet of the rules used in the grammar.
DataQualityParser.g4
DQ Rules
Data Quality rules are defined based on the grammar defined above. The rules are grouped together for each entity, and each rule validates an attribute of that entity
To make the rules as succinct as possible, and yet intuitive for the business user to understand the intent of the rule, we use the following keywords in the rules:
- must and should indicate the mandatory and recommended quality requirements.
- be, not, less than, greater than and have specify the nature of comparison in the action
- human_name, white space indicate the special quality checks that are not supported by the standard comparison operators.
In this example, the rules are defined for the Person entity and validates attributes Name, BirthDate, and Designation.
Person.dq
DQ Parser
Parser is the component that parses the data quality rules and generates the Rule Abstract Syntax Tree (AST). As an example, the AST for two DQ rules will be represented as shown below.

Building the lexer/parser code ground up can be cumbersome, but ANTLR makes short work of that by generating the Lexer, Parser as well as the base Visitor (or Listener) classes in multiple target languages.
Command to generate the lexer, parser, and visitor base code in Python
DQ Visitor
After the DQ Rule is parsed into the AST, DQ Visitor traverses the tree and incrementally adds custom behavior for each node in the tree.
The following snippet shows how the user input dq_rules are converted to an AST tree which is then used by DataQualityCustomVisitor to perform data quality validation against the input df: DataFrame using the same spark: SparkSession that is used to create the dataframe.
The line visitor.visit(tree) in above code starts a tree traversal that will invoke the visit implementation of each node of the tree.
Each row of DQ rule corresponds to the following visit function call.
The ctx.dq_check() will invoke a visit to the appropriate DQ check node. For instance the check BirthDate should be less than now will be handled by the following piece of code will construct a new DQ column on the spark dataframe with the condition col < F.current_timestamp().
Another DQ Rule from above: Name should be human_name will invoke the following DQ check visit method, that adds a new DF column with a regular expression check.
Final thoughts on Data Quality Grammar
Process Transparency - The Data Quality grammar is a declarative language that is easy to understand and can be shared with business users. The grammar is also easy to extend and can be used to define other quality checks. Optimized Execution - The DQ rules are converted into optimized Spark code that is lazily evaluated on the same Dataframe that is generated from preceding data transformation steps. Traditional approach of data quality validation is to persist the ETL output and then perform data quality checks. Performing data quality checks inline can save this additional round trip to the persistent storage layer
Data Grading
What is Data Grading? Data grading is the process of assigning a grade to each row of the dataframe based on the data quality check results. In practice, the true data grade is dependent on the final analytical use case. For instance, the data grade for a customer record can be based on the data quality of the customer name, address, and phone number. On other hand, the data grade for a product record can be based on the data quality of the product name, description, and price. Since the data grading subjective to the analytic use case, it is important to retain the data quality results at the row level without filtering out any failed validations.
Methodology to store the data quality results
In the first pass, each data quality check is performed for each row of the input dataframe. The result of the data quality check is a new boolean column that is added to the dataframe. The value of the new column is a boolean that indicates whether the data quality check passed or failed. The data quality check can be either a MUST or SHOULD check. The MUST check is a severe check and the SHOULD check is a warning check. The column name is constructed using the tested severity type, column name, and data quality check type. For instance, the data quality check Name should be human_name will add a new column dqw_Name_human_name to the dataframe. The value of the new column will be True if the data quality check passed and False if the data quality check failed. In a similar fashion, the data quality check BirthDate must be less than now will add a new column dqs_BirthDate_lt_now to the dataframe. The value of the new column will be True if the data quality check passed and False if the data quality check failed.
|
Name |
BirthDate |
dqs_Name_human_name |
dqw_BirthDate_lt_now |
|
John |
1982-12-01 |
True |
True |
|
Mark |
2042-01-01 |
True |
False |
|
Gle9 |
2012-01-01 |
False |
True |
The above format of storing data is not optimal for the following reasons:
- The number of columns in the dataframe will increase linearly with the number of data quality checks.
- The column names are not easy to read and understand.
- Most of the checks will pass and the information ratio (about the failed tests) is very low.
Furthermore, the Audit-Balance-Control framework in most Data Quality Management (DQM) tools may require the total number of severe and warning failure counts.
The following code snippet converts the above dataframe into a more compact format that is easy to read and understand.
Once the data quality results are flattened as shown below, the data grade is showcased by the count of severe and warning occurrences, indicating the degree of the issue, while also showcasing the specific data quality issue discovered. Abacus Data Platform uses these metrics and grades to further apply a business context grade on the data, while enriching the data from the Silver to Gold layer.
Final table with grade and data quality results
|
Name |
BirthDate |
DataQualityResult |
|
John |
1982-12-01 |
{ "SevereCount": 0, "WarningCount":0, SevereErrors: [], WarningErrors:[]} |
|
Mark |
2042-01-01 |
{ "SevereCount": 0, "WarningCount":1, SevereErrors: [], WarningErrors:["BirthDate_lt_now"]} |
|
Gle9 |
2012-01-01 |
{ "SevereCount": 1, "WarningCount":0, SevereErrors: ["Name_human_name"], WarningErrors:[]} |
Now as part of an automated pipeline, Data Quality rules can be applied to our data as it moves from Bronze->Silver->Gold, as a natural extension of our data pipelines. Moreover we are tracking with the data all the Data Quality tests, the results and their severity that feeds into also defining the grade or degree of usability of the data. This tied to our overall data governance and telemetry, enables Abacus Insights to deliver on usable data that our customers can depend on to run their business and improve patient outcome.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.