Easy Ingestion to Lakehouse with File Upload and Add Data UI
Fast track to the Lakehouse under 1 minute
by Emma Liu, Vincent Liaw, Yu Guo, Maraki Ketema, Amit Kara and Brecht Moulin
Data ingestion into the Lakehouse can be a bottleneck for many organizations, but with Databricks, you can quickly and easily ingest data of various types. Whether it's small local files or large on-premises storage platforms (like database, data warehouse or mainframes), real-time streaming data or other bulk data assets, Databricks has you covered with a range of ingestion options, including Auto Loader, COPY INTO, Apache Spark™ APIs, and configurable connectors. And if you prefer a no-code or low-code approach, Databricks provides an easy-to-use interface to simplify ingestion.
In this second part of our data ingestion blog series, we'll explore Databricks' File Upload UI and Add Data UI in more detail. These features allow you to drag and drop files for ingestion into Delta tables with Unity Catalog securing access, ingest from a wide range of other data sources via notebook templates, and choose from over 100 connectors available on Fivetran from the embedded Databricks Partner Connect integration. With Databricks' Lakehouse ingestion tools, you can streamline your data ingestion process and focus on extracting insights from your data.
Low-code ingestion features via UI
- File upload UI: drag-and-drop local file to your lakehouse under 1 minute
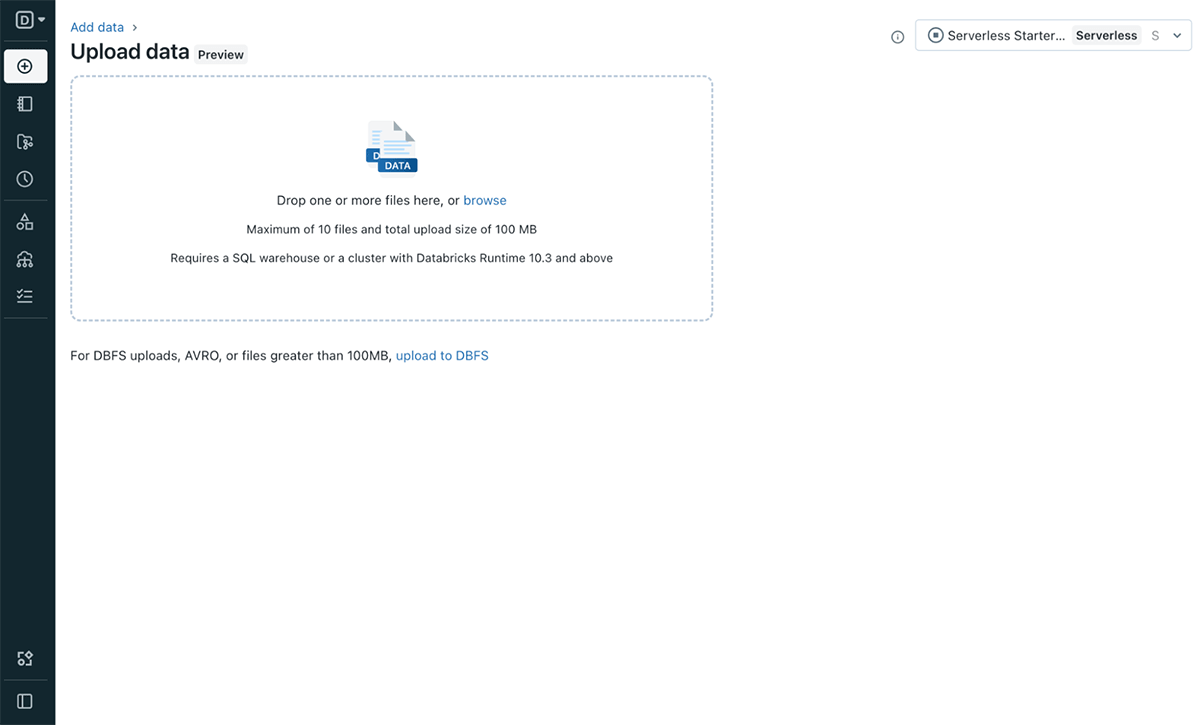
The File upload UI allows seamless, secure uploading of local files to create a Delta table. It is accessible across all personas through the left navigation bar, or from the Data Explorer UI and the Add data UI. You can use the UI to ingest via the following features:
- selecting or drag-and-dropping one or multiple files (CSV or JSON)
- previewing and configuring the resulting table and then creating the Delta table (see Figure 2 below)
- auto-selecting default settings such as automatically detecting column types while allowing updates
- modifying various format options and table options (see Figure 3 and Figure 4 below)
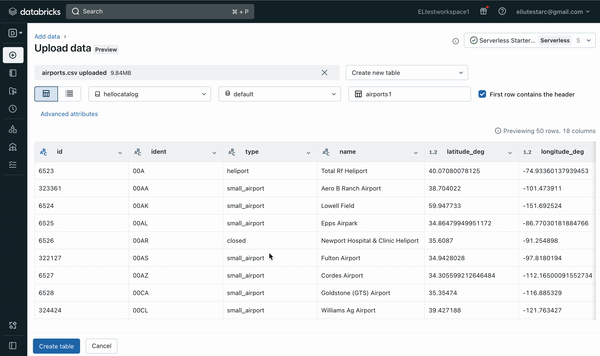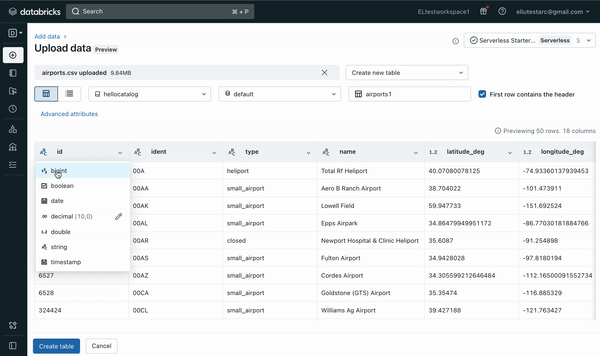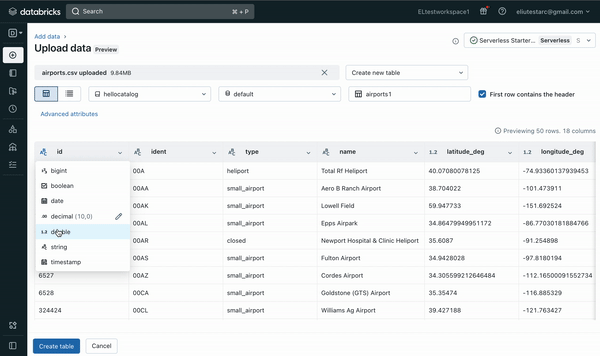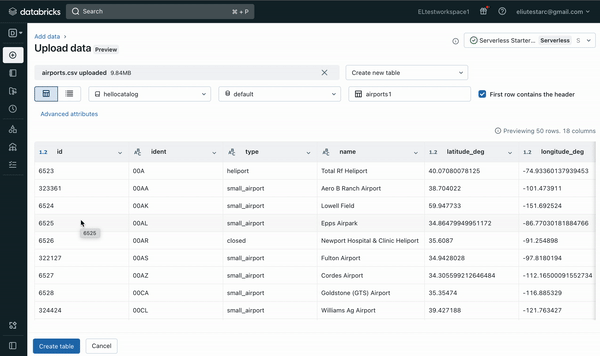
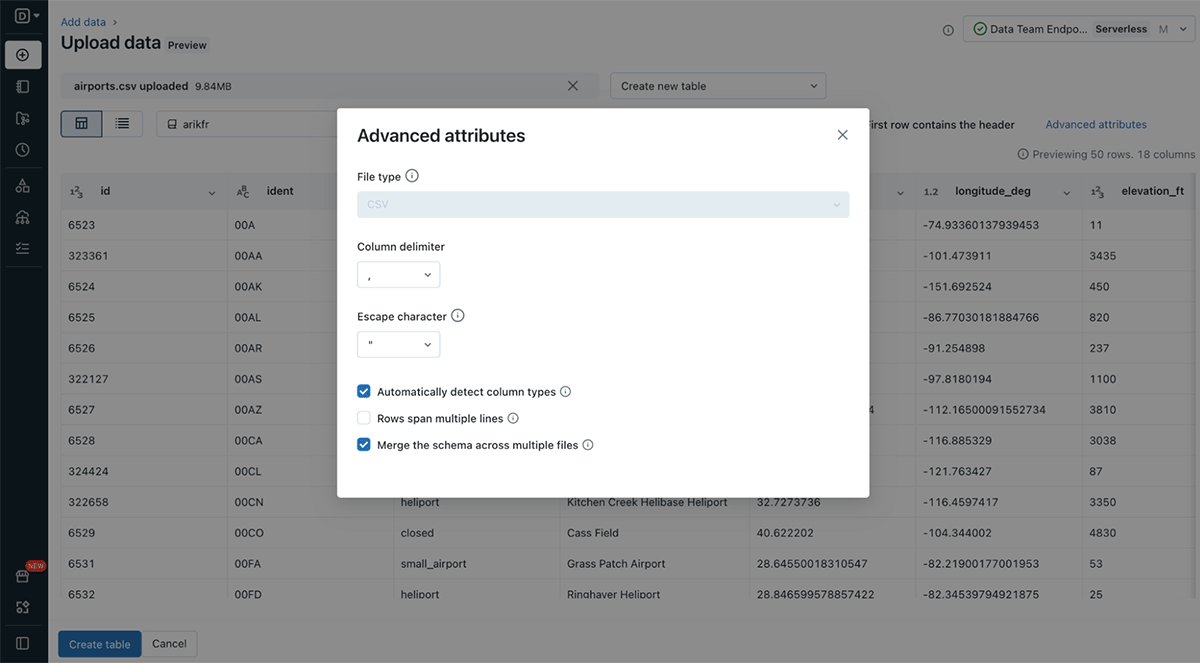
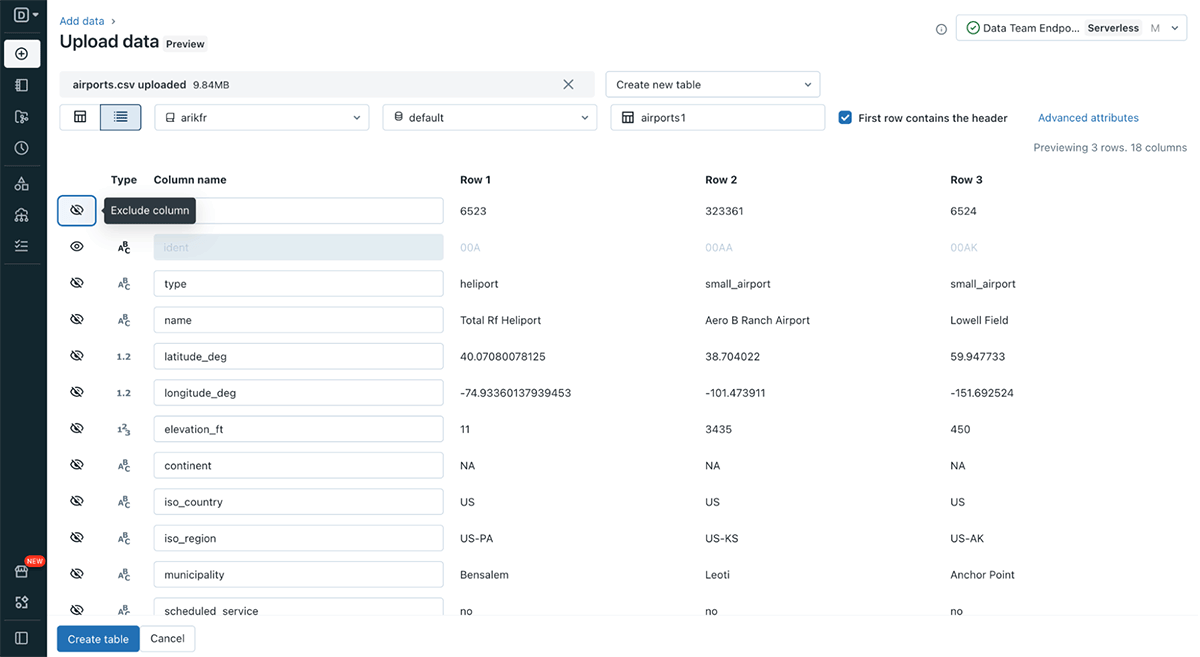
The File upload UI offers the option to create a new table or overwrite an existing table. In the future, more file types, larger file size and more format options will be supported.
- Add data UI: central location for all your top ingestion needs
The Add data UI, which is available in SQL, Data Science & Engineering and Machine Learning, acts as the one stop shop for all of your ingestion needs (see Figure 5). Users can click on the data source they want to ingest from, and follow the UI flow or notebook instructions to finish data ingestion step by step.

Today Databricks supports a number of native integrations including Azure Data Lake Storage, Amazon S3, Kafka and Kinesis, just to name a few. But you aren't limited to these native integrations; you can also leverage one of the 179 connectors supported by Fivetran! A search bar on the top right corner is provided for easy discovery. Just simply select one of the connectors to the Partner Connect experience for Fivetran.
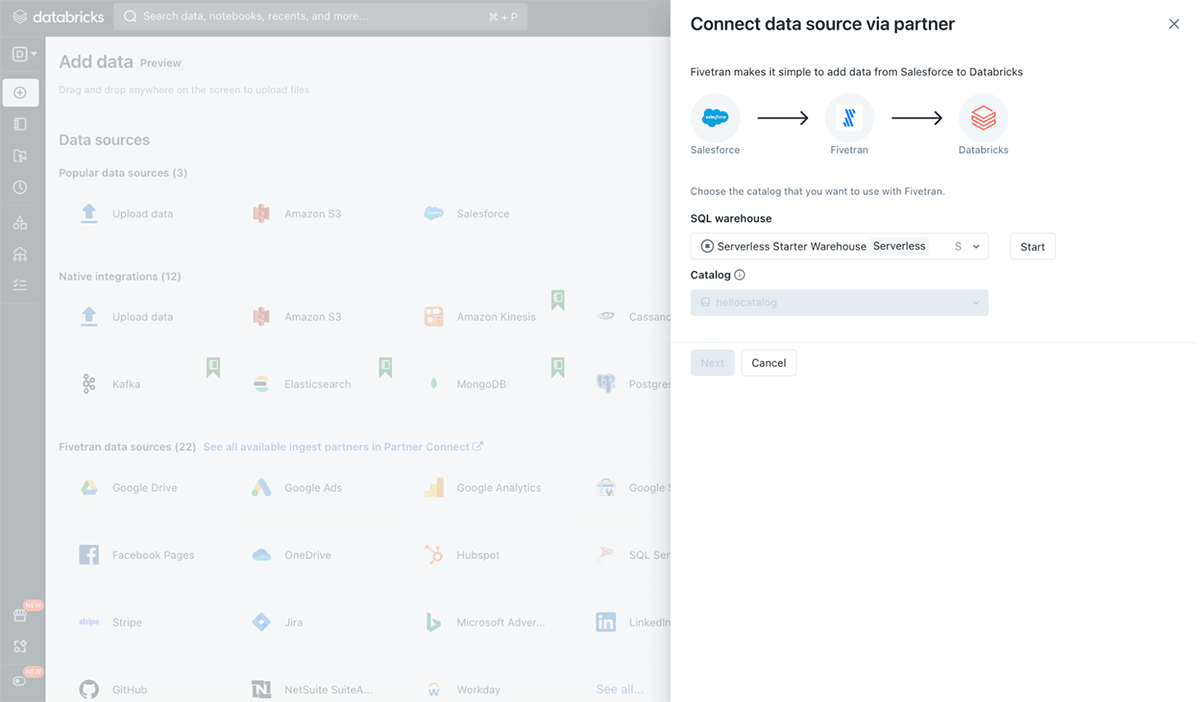
Users will be able to select the Catalog if they have Unity Catalog or hive_metastore which is autoselected for workspaces without Unity Catalog. A compute resource and an access token will be provisioned for a user before they are directed to Fivetran. Once a user signs into Fivetran or creates an account to initiate a trial, they'll be able to start bringing data into Databricks using one of Fivetran's connectors. No manual work necessary, the connection between Databricks and Fivetran is auto configured!
How to get started?
Simply go to your Databricks workspace interface, and click "+New". You can choose "File Upload" or "Data" to start exploring.
What's next?
We will continue to expand upon the existing low-code/no-code ingestion functionalities within the File upload and Add data UI. In an upcoming blog, we will delve deep into the UI for native integrations, exploring the seamless ingestion from Azure Data Lake Storage (ADLS), AWS S3, and Google Cloud Storage (GCS) with Unity Catalog. Stay tuned for more UI features, making data ingestion to the Lakehouse easier than ever.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.