Fastest way to federate real-time SAP HANA data into Databricks using Spark JDBC
SAP's recent announcement of a strategic partnership with Databricks has generated significant excitement among SAP customers. Databricks, the data and AI experts, presents a compelling opportunity for leveraging analytics and ML/AI capabilities by integrating SAP HANA with Databricks. Given this collaboration's immense interest, we are thrilled to embark on a deep dive blog series.
In many customer scenarios, a SAP HANA system serves as the primary entity for data foundation from various source systems, including SAP CRM, SAP ERP/ECC, SAP BW. Now, the exciting possibility arises to seamlessly integrate this robust SAP HANA analytical sidecar system with Databricks, further enhancing the organization's data capabilities. By connecting SAP HANA (with HANA Enterprise Edition license) with Databricks, businesses can leverage the advanced analytics and machine learning capabilities (like MLflow, AutoML, MLOps) of Databricks while harnessing the rich and consolidated data stored within SAP HANA. This integration opens up a world of possibilities for organizations to unlock valuable insights and drive data-driven decision-making across their SAP systems.
Multiple approaches are available to federate SAP HANA tables, SQL views, and calculation views in Databricks. However, the quickest way is to use SparkJDBC. The most significant advantage is SparkJDBC supports parallel JDBC connections from Spark worker nodes to the remote HANA endpoint.
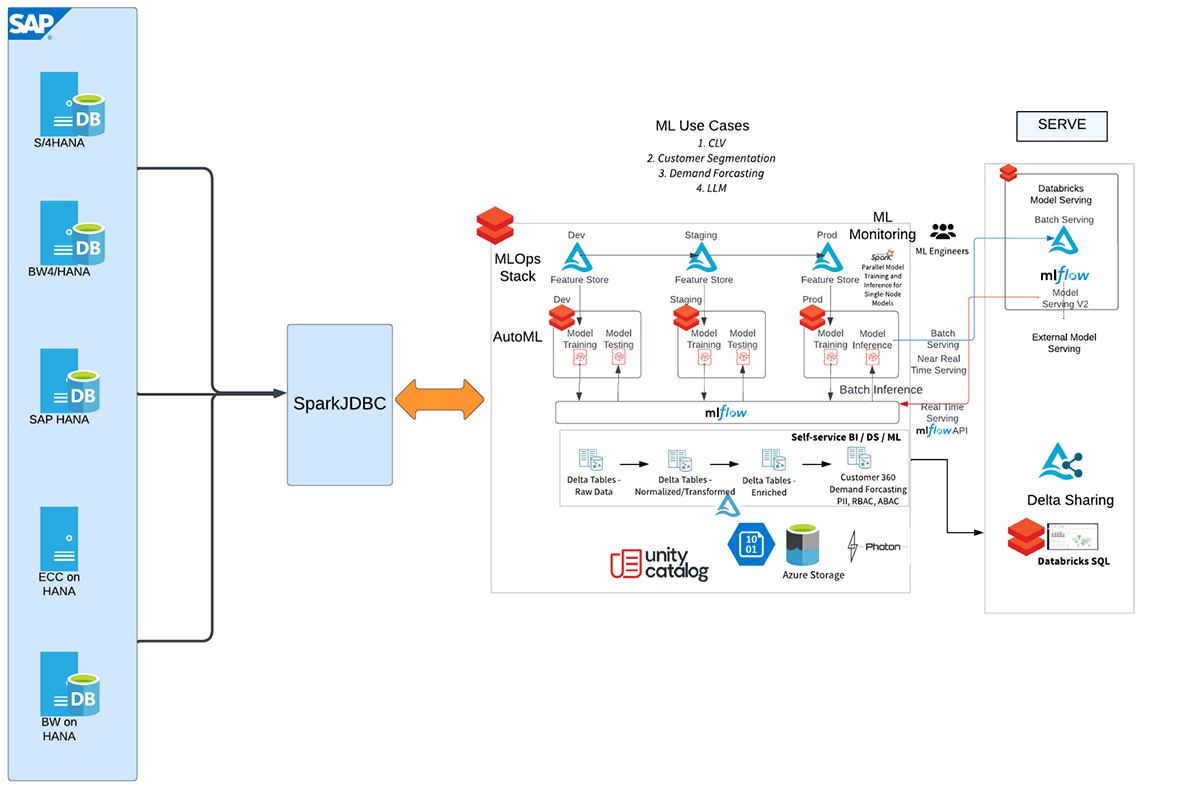
Let us start with SAP HANA and Databricks integration
First, SAP HANA 2.0 is installed in the Azure cloud and we tested the integration with Databricks.
Installed SAP HANA info in Azure:
| version | 2.00.061.00.1644229038 |
| branch | fa/hana2sp06 |
| Operating System | SUSE Linux Enterprise Server 15 SP1 |
Here is the high-level workflow depicting the different steps of this integration.
Please see the attached notebook for more detailed instructions for extracting data from SAP HANA's calculation views and tables into Databricks using SparkJDBC.

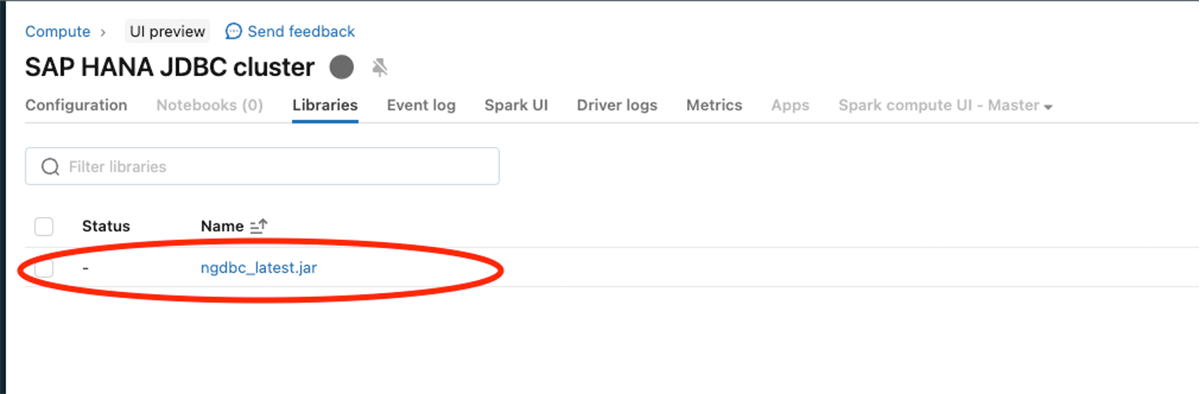
Configure the SAP HANA JDBC jar (ngdbc.jar) as shown in the image below
Once the above steps are performed, perform a spark read using the SAP HANA server and JDBC port.
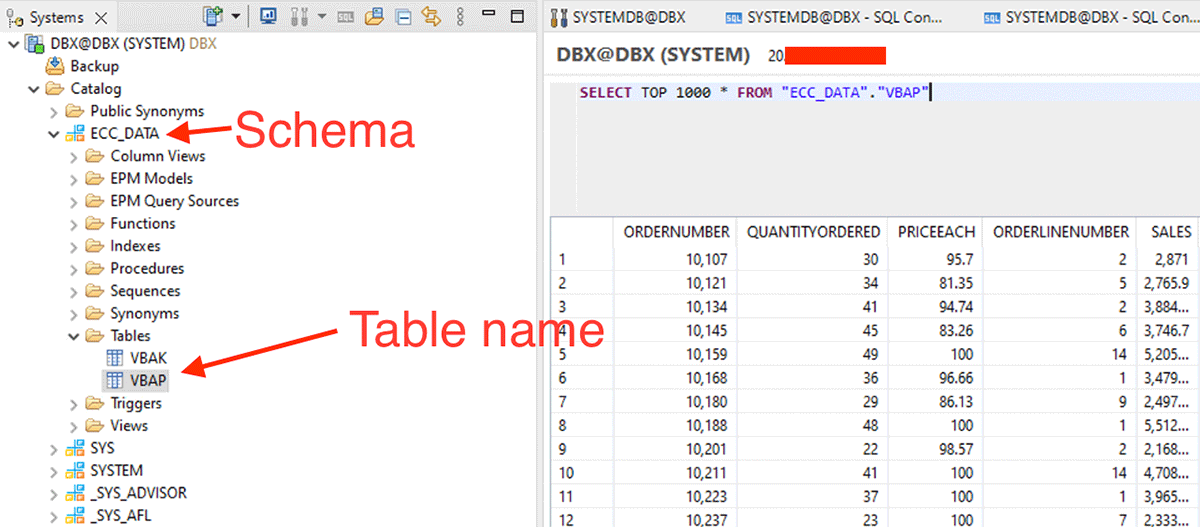
Start creating the dataframes using the in shown below with schema, table name.
Also, we can do a filter pushdown by passing SQL statements in the dbtable option.
To get data from the Calculation View, we have to do the following:
For example, this XS-classic calculation view is created in the internal schema "_SYS_BIC".
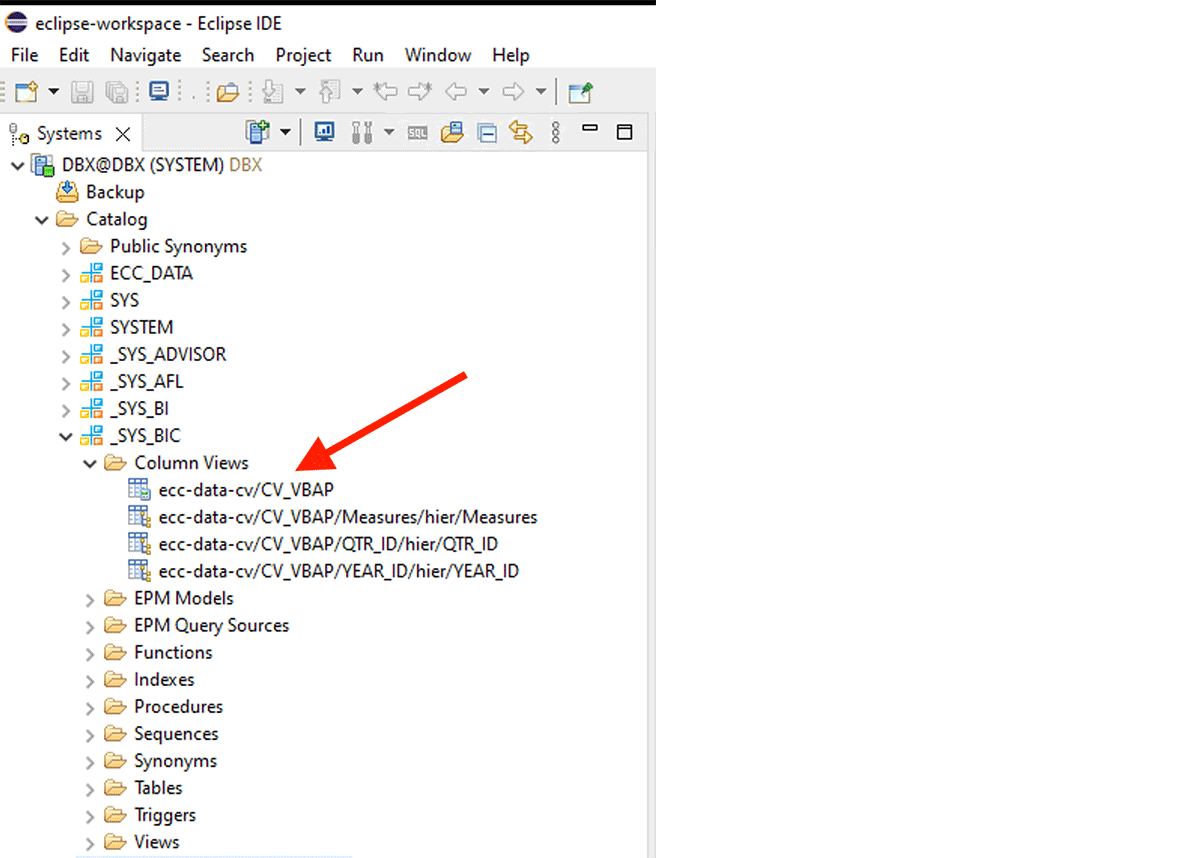
This code snippet creates a PySpark dataframe named "df_sap_ecc_hana_cv_vbap" and populates it from a Calculation View from the SAP HANA system (in this case, CV_VBAP).
After generating the PySpark data frame, leverage Databricks' endless capabilities for exploratory data analysis (EDA) and machine learning/artificial intelligence (ML/AI).
Summarizing the above data frames:
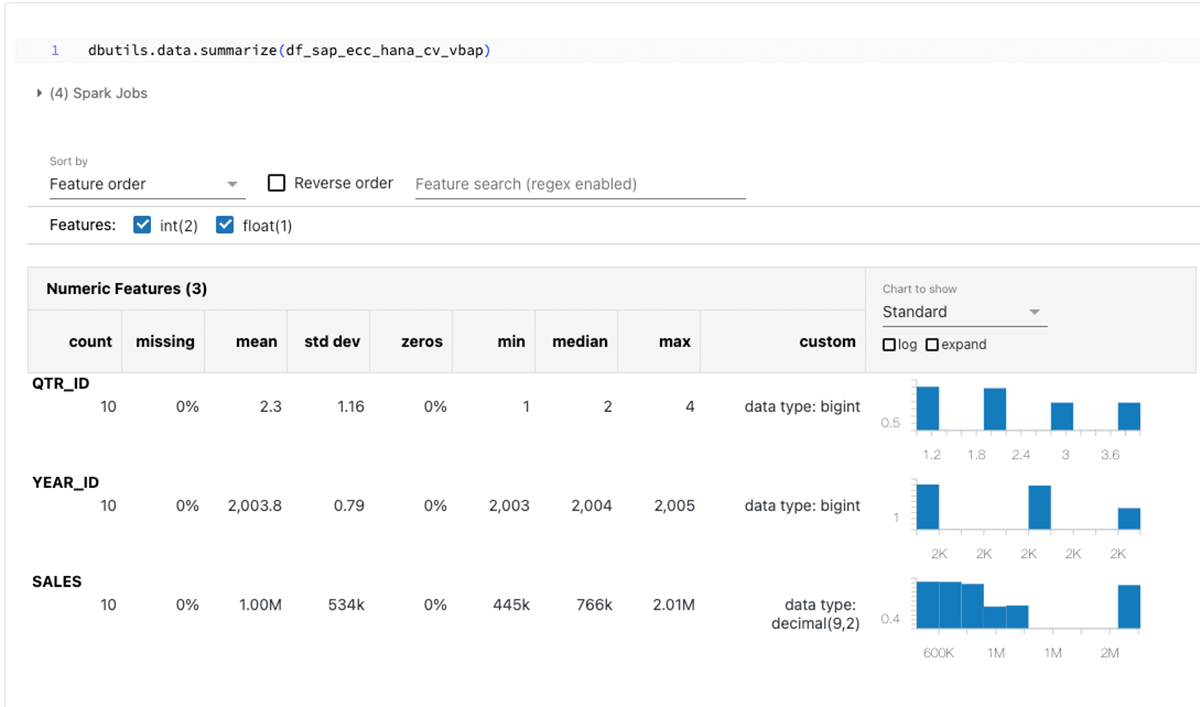
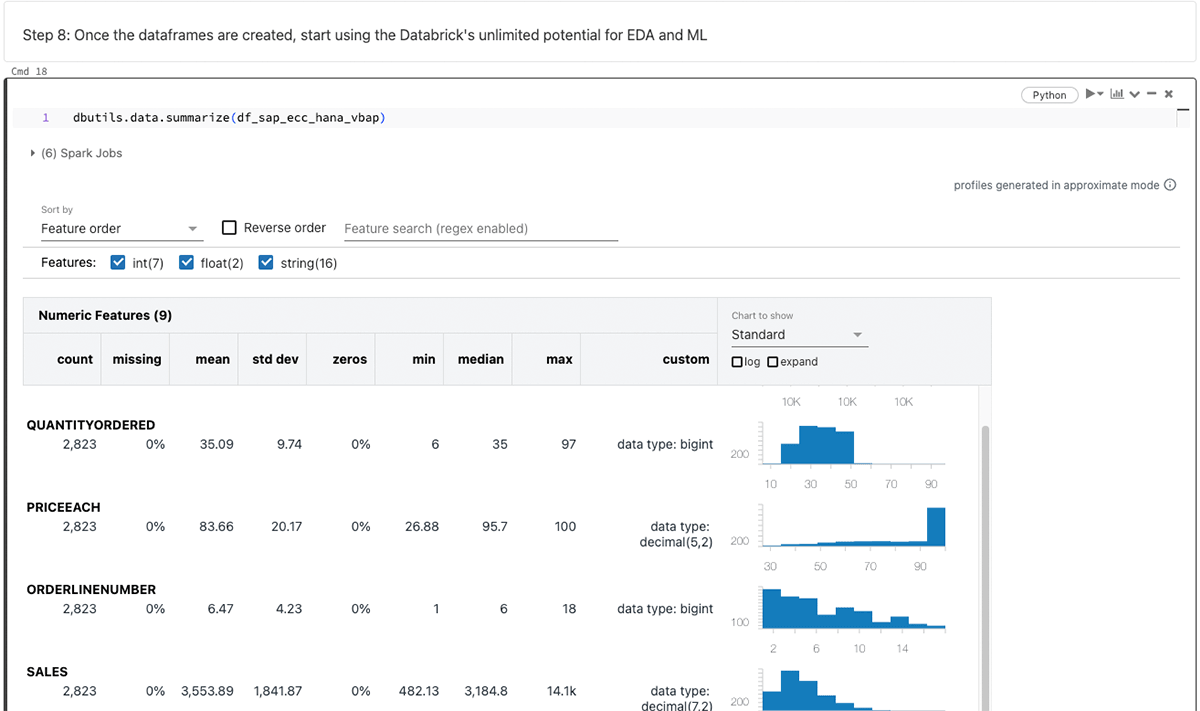
The focus of this blog revolves around SparkJDBC for SAP HANA, but it's worth noting that alternative methods such as FedML, hdbcli, and hana_ml are available for similar purposes.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.