Generative AI In Advertising: Custom Ad Images from Segmentation
by Jack Sandom, Sara Hovakeemian and Mandy Baker
- Personalize ad creative: Learn how Databricks combines seed images, multimodal RAG, and GenAI to generate custom ad images.
- Ground in brand assets: Use seed images with custom embedding and vector search to keep generated creatives consistent, realistic, and aligned with real examples.
- A practical demo: See the end-to-end solution in a Databricks App powered by model serving and an AI agent.
Today’s advertising demands more than just eye-catching images. It needs a creative that actually fits the tastes, segments, and expectations of a target audience. This is the natural next step after understanding your audience; using what you know about a segment’s preferences to create imagery that truly resonates (customized to your audience).
Multimodal Retrieval-Augmented Generation (RAG) provides a practical way to do this at scale. It works by combining a text-based understanding of a target segment (e.g., “outdoor-loving dog owner”) with fast search and retrieval of semantically relevant real images. These retrieved images then serve as context for generating a new creative. This bridges the gap between customer data and high-quality content, making sure the output connects with the target audience.
This blog post will demonstrate how modern AI, through image retrieval and multimodal RAG, can make ad creative more grounded and relevant, all powered end-to-end with Databricks. We’ll show how this works in practice for a hypothetical pet food brand called “Bricks” running pet-themed campaigns, but the same technique can be applied to any industry where personalization and visual quality matter.
Solution Overview
This solution turns audience understanding into relevant, on-brand visuals by leveraging Unity Catalog, Agent Framework, Model Serving, Batch Inference, AI Search, and Apps. The below diagram provides a high-level overview of the architecture.
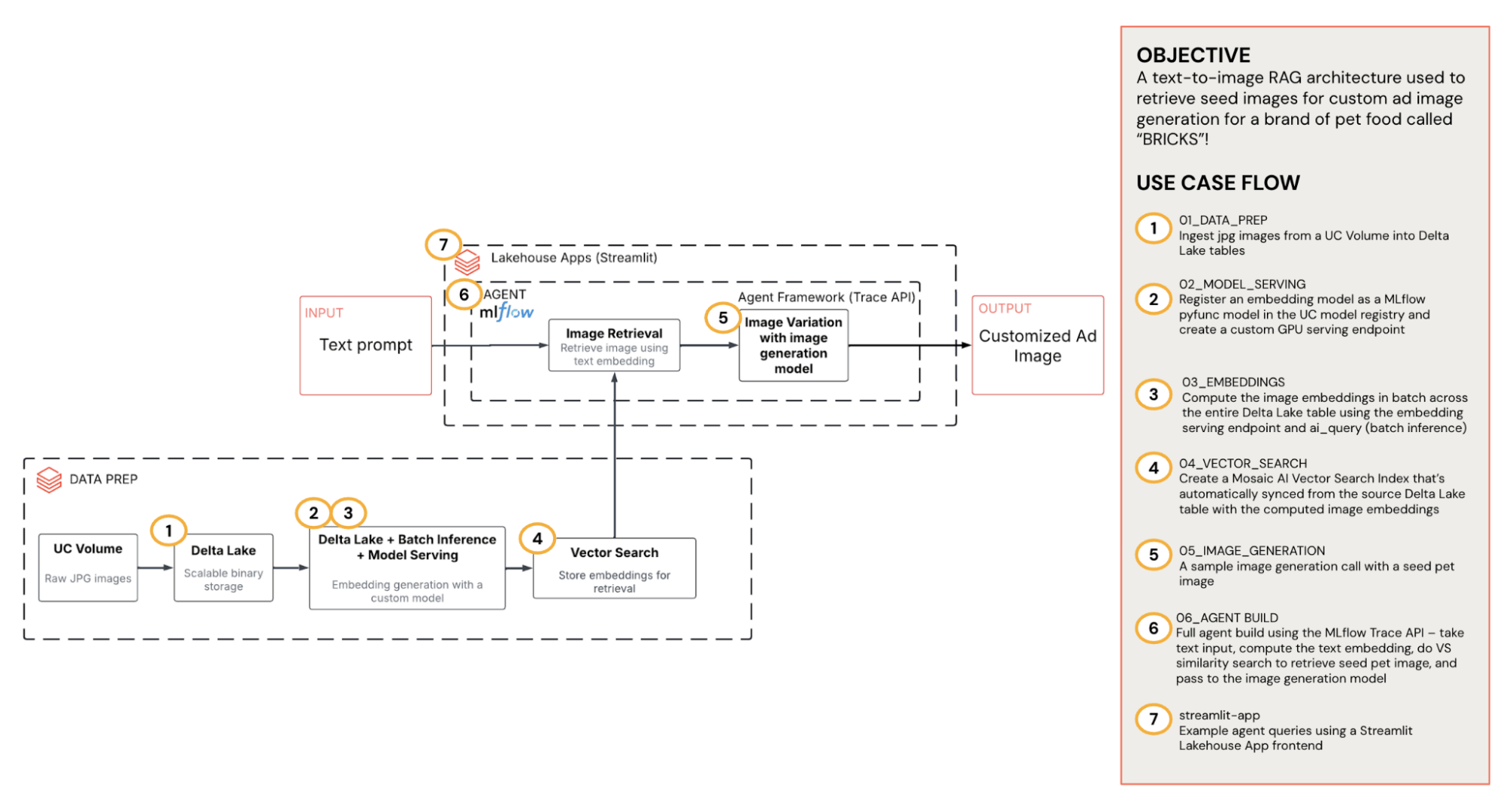
- Storage & Governance (Unity Catalog): All source images and generated ads live in a Unity Catalog (UC) Volume. We also ingest the source images into a Delta table for batch processing.
- Bring-your-own embeddings: A lightweight CLIP image encoder serving endpoint converts images to vectors. We run batch inference over the Delta table to produce embeddings at scale and then store them back alongside the UC Volume paths.
- AI Search retrieval: The embeddings are indexed in Databricks AI Search that is automatically synced from the source Delta table for low-latency semantic lookup. Given a short text prompt, the index returns the top-K UC paths.
- RAG agent: A tool-using chat agent coordinates the workflow: taking text input → propose a pet description → compute text embedding → calling vector search to retrieve the seed image → and then passing the seed to the image generation model.
- Databricks app: A user-friendly app exposes the agent to users and guides them in generating a personalized ad image for their segment.
Because everything flows through UC, the system is secure by default, observable (MLflow tracing on retrieval and generation), and easy to evolve (swap models, tune prompts). Let’s dive deeper.
Storage & Governance (Unity Catalog)
All of the pet image assets (seed pet images, brand image, and final ads) live in a UC Volume, e.g:
UC Volumes provide an efficient storage solution for our image data with a FUSE-mount point and are useful as they allow for one governance plane. The same ACLs apply whether you access the files from notebooks, serving endpoints, or the Databricks app. It also means there are no blob keys in our code. We pass paths (not bytes) across services.
For fast indexing and governance, we then mirror the Volume into a Delta table that loads the raw images bytes (as a BINARY column) alongside metadata. We then convert this into a base64 encoded string (required for model serving endpoint). This makes downstream batch jobs (like embedding) simple and efficient.
Now there is one queryable table and we have also preserved the original Volume paths for human readability and app use.
Bring-your-own Embeddings
CLIP is a light-weight image encoder with a transformer text-encoder model that is trained via contrastive learning to produce aligned image-text embeddings for zero-shot classification and retrieval. To keep retrieval fast and reproducible, we expose CLIP encoders behind a Databricks Model Serving endpoint which we can use for both online lookups and offline batch inference. We simply package the encoder as an MLflow pyfunc function, register and log as a UC model and serve it with a custom model serving, and then call it from SQL with ai_query to fill the embeddings column in the Delta table.
Step 1: Package CLIP as an MLflow pyfunc
We wrap CLIP ViT-L/14 as a small pyfunc that accepts a base64 image string and returns a normalized vector. After logging, we register the model for serving.
Step 2: Register the model and log into UC
We log the model using MLflow and register it to a UC model registry.
Step 3: Serve the encoder
We create a GPU serving endpoint for the registered model. This gives a low-latency, versioned API we can call.
Step 4: Batch inference with ai_query
With images landed in a Delta table, we compute embeddings in place using SQL. The result is a new table with an image_embeddings column, ready for AI Search.
AI Search Retrieval
After we’ve materialized the image embeddings in Delta, we make them searchable with Databricks AI Search. The pattern is to create a Delta Sync index with self-managed embeddings, then at runtime embed the text prompt using CLIP and run a top-K similarity search. The service returns small, structured results (paths + optional metadata), and we pass UC Volume paths forward (not raw bytes) so the rest of the pipeline stays light and governed.
Step 1: Indexing the embeddings table
Create a vector index once. It continuously syncs from our embeddings table and serves low-latency queries.
Because the index is Delta synced, any new table rows of embeddings (or updated rows of embeddings) will automatically be indexed. Access to both the table and the index inherits Unity Catalog ACLs, so you don’t need separate permissions.
Step 2: Querying top-K candidates at runtime
At inference we embed the text prompt and query the top three results with similarity search.
When we pass the results to the agent later, we will keep the response minimal and actionable. We return just the ranked UC paths which the agent will cycle through (if a user rejects the initial seed image) without re-querying the index.
RAG Agent
Step 1: Image generation serving endpoint (retrieval + generation)
Here we create an endpoint which accepts a short text prompt and orchestrates two steps:
- Retrieval: embed the text, query AI Search Index, and return top-3 UC Volume paths to the seed images (rank-ordered)
- Generation: loads the chosen seed, calls the image generation API, uploads the final image to UC volume, and returns its path.
This second part is optional and controlled by a toggle depending on whether we want to run the image generation or just the retrieval.
For the generation step, we are calling out to Replicate using the Kontext multi-image max model. This choice is pragmatic:
- Multi-image conditioning: Kontext can take a seed pet photo and a brand image and compose a realistic ad
- Photorealism + background retention: Kontext tends to keep the pet’s original pose/environment while placing the product naturally
- Quality vs Latency: Kontext provides a good balance between quality and latency. It produces a relatively high-quality image in about 7-10 seconds. Other high-quality image generation models that we tested such as gpt-4o, via the gpt-image-1 API, generate higher quality images in about 50 seconds to one minute.
Generation call:
Write-back to UC Volume - decode base64 from the generator and write via the Files API:
If desired, it is easy to replace Kontext/Replicate with any external image API (e.g. OpenAI) or an internal model served on Databricks without changing the rest of the pipeline. Simply replace the internals of the _replicate_image_generation method and keep the input contract (pet seed bytes + brand bytes) and output (PNG bytes → UC upload) identical. The chat agent, retrieval, and app stay the same because they operate on UC paths, not image payloads.
Step 2: Chat agent
The chat agent is a final serving endpoint that holds the conversation policy and calls the image-gen endpoint as a tool. It proposes a pet type, retrieves the image seed candidates, and only generates the final ad image on the user’s confirmation.
The tool schema is kept minimal:
We then create the tool execution function where the agent can call the image-gen endpoint which returns a structured JSON response.
The replicate_toogle param controls the image generation.
Why split endpoints?
We separate out the image-gen and chat agent endpoints for a couple of reasons:
- Separation of concerns: The image-gen endpoint is a deterministic service (retrieve top-K → optionally generate one → return UC paths). The chat agent endpoint owns policy and user experience. Both stay small, testable, and replaceable
- Modular extensibility: The agent can grow by adding tools later behind the same interface e.g., copy or CTA suggestions, structured data retrieval, without changing the image-gen service
The above is all built on the Databricks Agent Framework, which gives us the tools to turn retrieval + generation into a reliable, governed agent. First, the framework lets us register the image-gen service (including AI Search) as tools and invoke them deterministically from the policy/prompt. It also provides us with production scaffolding out of the box. We use the ResponsesAgent interface for the chat loop, with MLflow tracing on every step. This gives full observability for debugging and operating a multi-step workflow in production. The MLflow tracing UI lets us explore this visually.
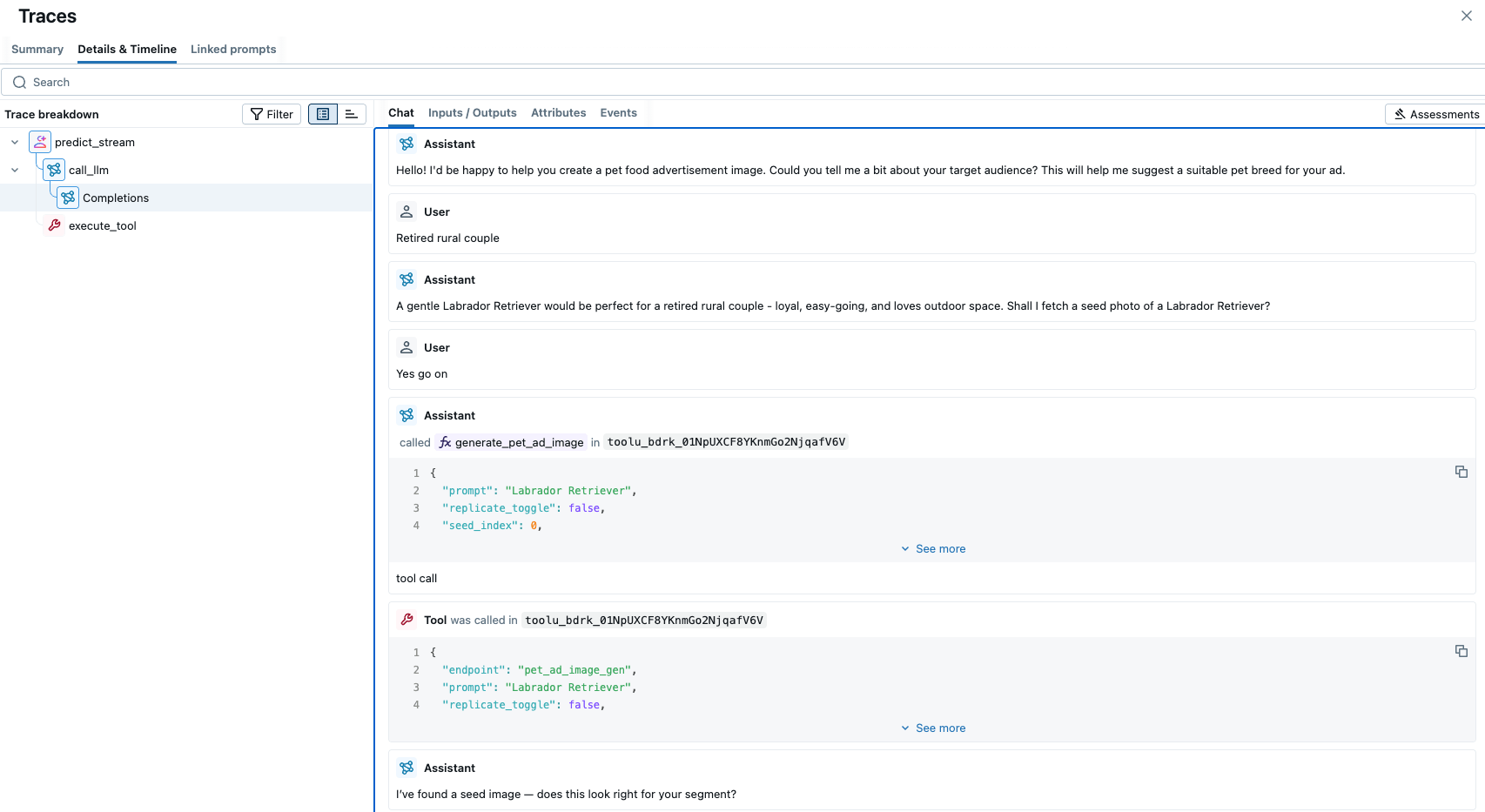
Databricks App
The Streamlit app presents a single conversational experience that lets the user talk to the chat agent and renders the images. It combines all the pieces we have built into a single, governed product experience.
How it comes together:
- Governance and permissions: The app runs in the Databricks workspace and talks directly to our chat agent endpoint. With on-behalf-of credentials, the app can download seed/final images by UC path via the Files API under the viewer’s permissions. That gives per-user access control and clear audit trail
- Config as code: App settings (e.g., AGENT_ENDPOINT) are passed via environment variables/secrets
- Clear interfaces: The chat surface sends a compact Responses payload to the agent and receives a tiny JSON pointer back with a UC Volume path. The UI then downloads the image and renders to the user
Below shows the two key touchpoints in the app code. First, call the agent endpoint:
And render by UC Volume path:
End-to-end Example
Let’s walk through a single flow that ties the whole system together. Imagine a marketer wants to generate a customized pet ad image for “young urban professionals”.
1. Propose
The chat agent interprets the segment and proposes a type of pet e.g., French Bulldog.
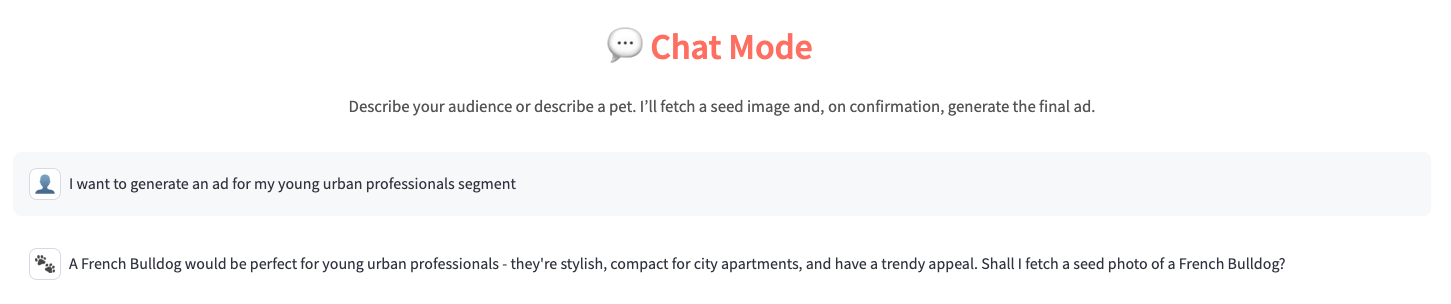
2. Retrieve (tool call, no generation)
On “yes”, the agent calls the image-gen endpoint in retrieval mode and returns the top three images (Volume paths) from AI Search ranked by similarity. The app displays candidate #0 as the seed image.
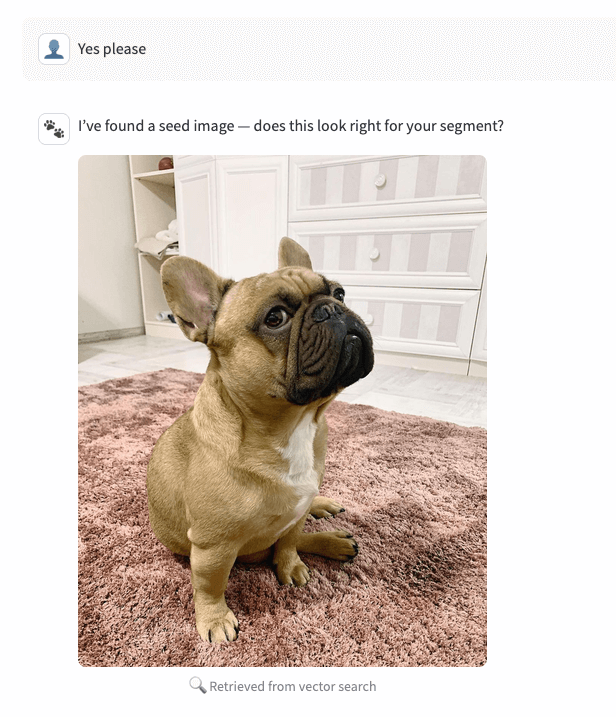
3. Confirm (or iterate)
If the user says something to the effect of “looks right”, we proceed. If they say “not quite”, the agent increments seed_index to 1 (then 2) and re-uses the same top-3 set (no extra vector queries) to show the next option. If after three images, the user is still not happy, the agent will suggest a new pet description and trigger another AI Search call. This keeps the UX snappy and deterministic.
4. Generate and render
On confirmation, the agent calls the endpoint again with replicate_toggle=true and the same seed_index. The endpoint reads the chosen seed image from UC, combines it with the brand image, runs the Kontext multi-image-max generator on Replicate, and then uploads the final PNG back to a UC Volume. Only the UC path is returned. The app then downloads the image and renders it back to the user.
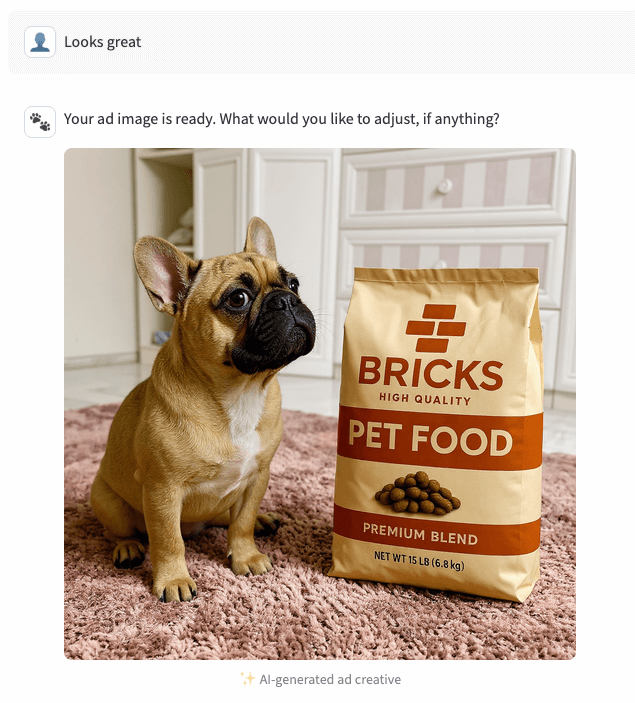
Conclusion
In this blog we have demonstrated how multimodal RAG unlocks advanced ad personalization. Grounding generation with real image retrieval is the difference between generic visuals and creative that resonates with a specific audience. This unlocks:
- Higher visual quality: Photographic seeds preserve finer details that text-only prompts struggle to reproduce.
- Contextual alignment: Retrieval anchors scenes and pets to the audience context improving message-image coherence.
- More predictable generation: Multi-image conditioning (seed + brand image) constrains the model, cutting hallucinations and improving brand safety.
- Fast iteration: Returning the top-3 seeds lets the agency cycle through without re-querying. The marketer stays in the loop and steers the final ad image.
Databricks ensures scalable, governed, high-performance applications. This architecture stays production ready with every step running end-to-end inside the platform:
- Unity Catalog governs everything - source and generated images, tables, Agent. Access, audit, and lineage are consistent.
- Delta tables + AI Search keep embeddings transactional and queries low-latency. You can re-embed, re-index or filter by metadata without changing anything downstream.
- Model Serving + Agent Bricks Custom Agents separate concerns: the image-gen endpoint is a deterministic service, and the chat agent orchestrates policy and tools. Each scales, versions, and rolls back independently.
- Databricks Apps puts the UI next to data and services and MLflow tracing provides turn-by-turn observability.
The result is a modular, governed RAG agent that turns audience insights into high-quality, on-brand creative at scale.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.