Governing cybersecurity data across multiple clouds and regions using Unity Catalog & Delta Sharing
by Samir Patel, David Wells, Lipyeow Lim, Ricardo Portilla and Anna Cuisia

According to a 2023 report from Enterprise Search Group, 85% of organizations indicated they deploy applications on two or more IaaS providers, attesting that the age of multi-cloud is officially here. A common reason for this decentralized model is that data residency requirements often require data to remain local to a specific region. For example, National Data Residency Laws in Germany and France mandate specific sensitive data (e.g., health, financial) remain within the country. Data residency requirements create additional complexities as organizations are faced with managing systems both on-prem and in the cloud.
For cybersecurity operations, teams need to monitor logs and telemetry produced by the applications and infrastructure in multiple clouds and regions. With the data egress costs levied by cloud providers, consolidating the data into a single physical location is clearly not feasible for data-intensive organizations.
Our previous blog on Cybersecurity in the Era of Multiple Clouds & Regions highlighted the query federation approach to address the problem of querying cybersecurity logs across multiple clouds and regions, while respecting data sovereignty laws and minimizing egress costs (see figure below). However, there were still three additional data governance opportunity areas to address:
- Ease of federating tables from multiple Databricks workspaces
- Ease of managing access control to the federated tables
- Ease of deploying federation as code
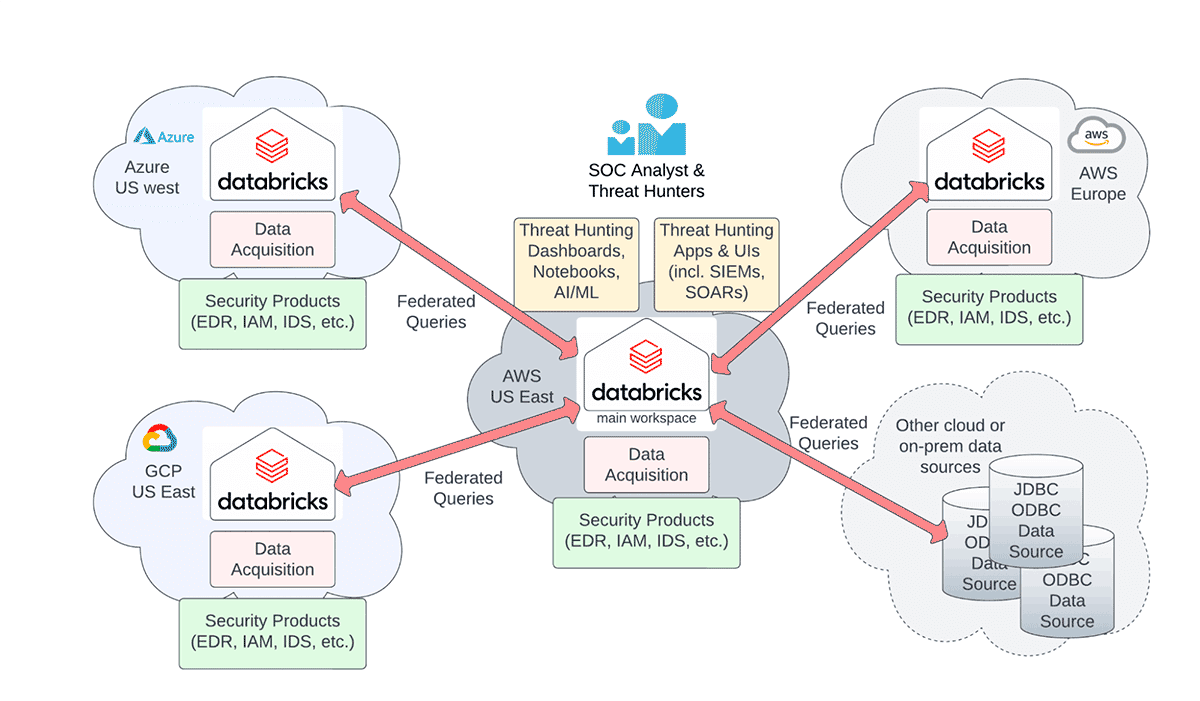
In this blog, we show how Unity Catalog, Delta Sharing & Lakehouse Federation elevates the multi-cloud, multi-region cybersecurity capabilities to a first-class citizen in the Databricks Lakehouse platform with easy governance of all your cybersecurity data no matter which cloud and which region they are located.
While we use cybersecurity threat hunting as a concrete use case, the approach outlined in this blog is broadly applicable to all types of enterprise data siloed in different clouds, different regions, and different data stores. Multi-cloud and multi-region data governance is the key to unlocking the value of siloed enterprise data without sacrificing risk-based controls. In fact, according to the AWS MIT CDO Agenda 2023 Report, 45% of CDOs stated "establishing clear and effective data governance" as the top priority on the journey to unlock value from enterprise data.
To address the governance challenges outlined above, we demonstrate how
- Delta Sharing can be used to seamlessly federate tables from multiple Databricks workspaces,
- Unity Catalog can be used to easily manage access control to the federated tables, and
- A Terraform-based deployment framework can be used to deploy the federation as code.
Governance is only a means to an end. We demonstrate how all these capabilities come together to facilitate the deployment of distributed logging capabilities across clouds and regions while enabling security analysts to centrally manage and query the data for threat detection and hunting. The demonstration is grounded in the distributed Indicators of Compromise (IOC) matching use case, a fundamental building block for threat detection rules or AI models. Databricks has already released a solution accelerator that implements the IOC use case - what we have done is take advantage of Lakehouse Federation services to simplify integrating cross-cloud querying.
Building Your Multi-Cloud Architecture
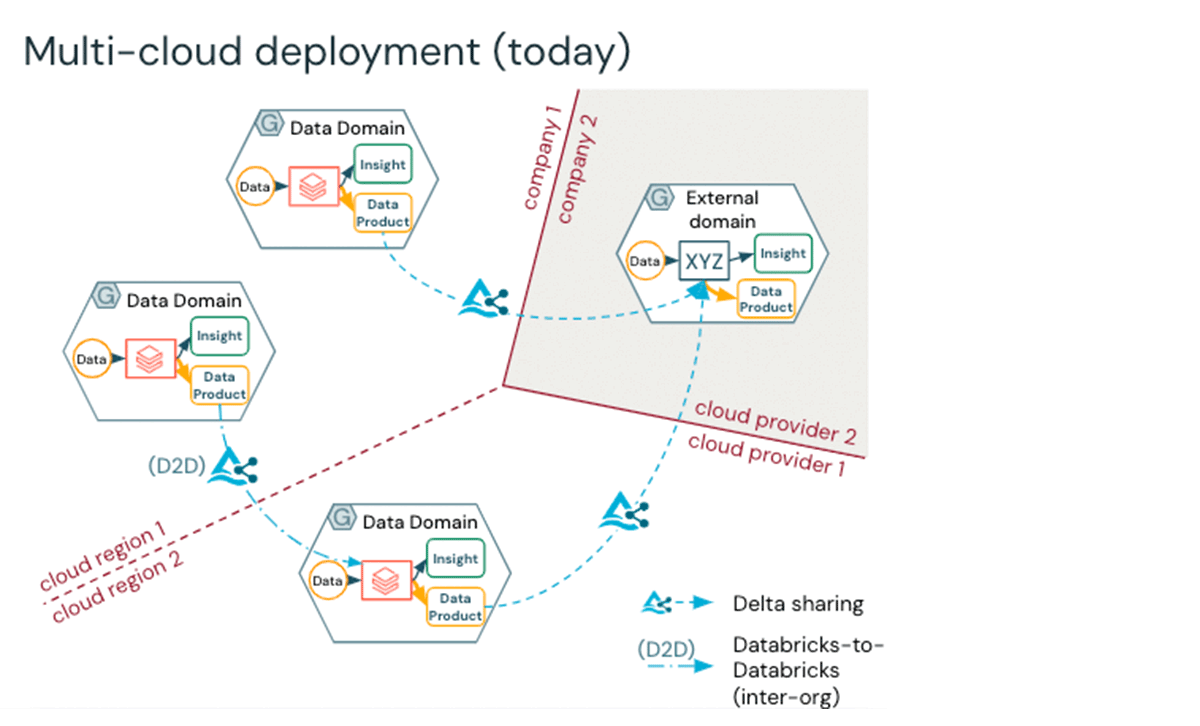
The remainder of this blog will show you how to quickly set up a multi-cloud, multi-region Databricks environment within minutes by leveraging our Industry Lakehouse Blueprints and Terraform. Delta Sharing is the foundation for multi-cloud data access patterns, and we represent this in a mesh-like representation below. Core benefits of using Unity Catalog to manage data include the ability to:
- Apply fine-grained access controls on data
- Understand end-to-end data lineage
- Enable data distribution in a simple, seamless way.
Once data is placed into a container, known as a Delta share, enterprise governance teams can manage access to the shared data. Moreover, once the data is centralized, for example, in a hub-and-spoke architecture, the main hub, which unions the data, applies access controls to protect the data across the enterprise.
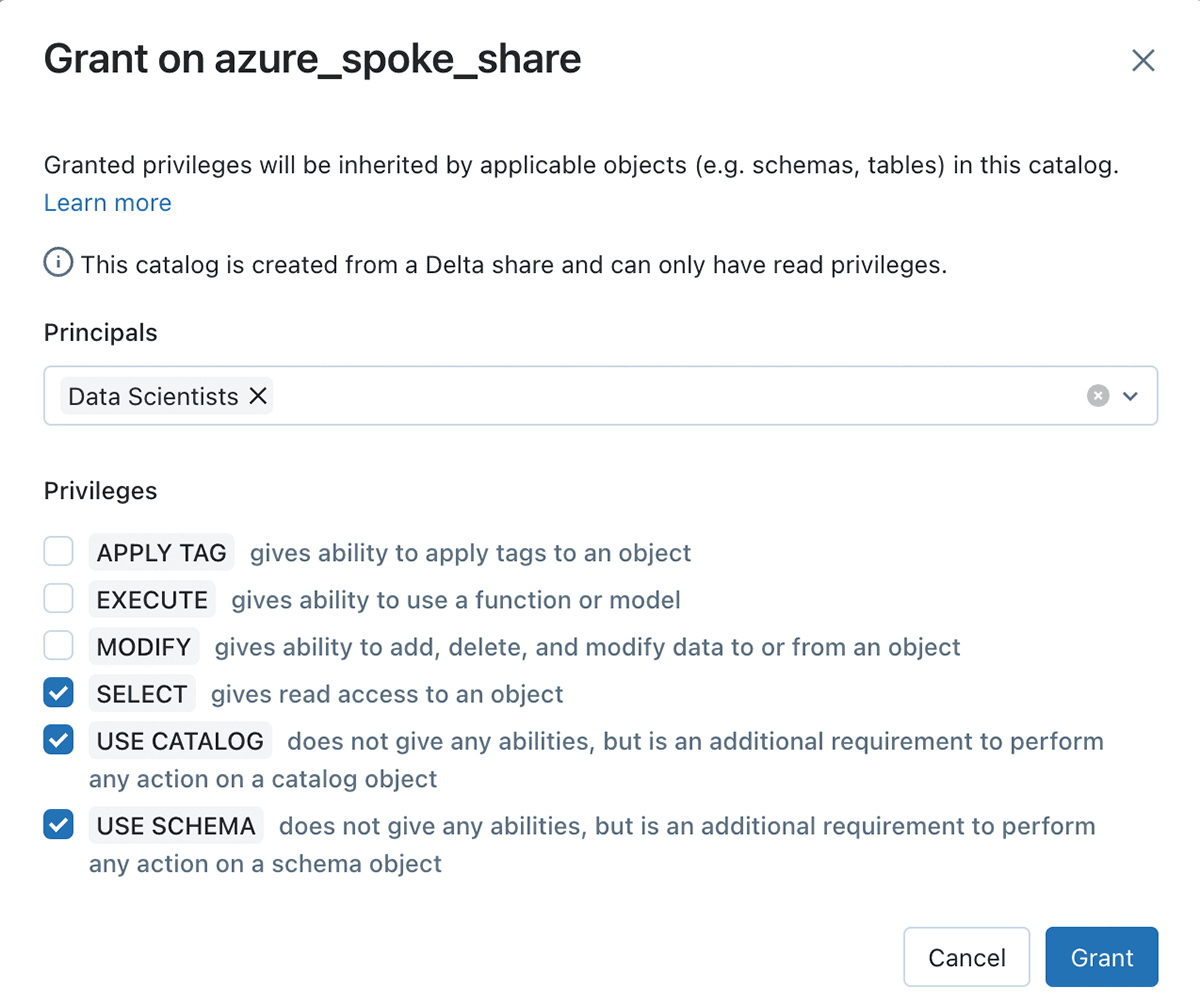
Step 1 - Retrieve Tables from Existing Cyber Catalog
Assuming you have an existing catalog for your cyber source tables for IOC matching (e.g. DNS, HTTP log data from the IOC matching solution), use a data source variable to load these so you can create a Delta Share object later.
Step 2 - Invoke the Cyber blueprint module to automate the creation of shares of IOC, IDS, and other Data Sources
We have created a module which allows you to link all your spoke workspaces based on our data exfiltration prevention hub and spoke model. This module requires the global metastore IDs, retrieved from the hub and spoke workspaces.
Step 3 - Federate queries across multiple clouds using pre-created shares
One of the major challenges to federate queries for cybersecurity use cases is cross-cloud querying. Organizations want to avoid replicating data across clouds, which incurs high costs both from the data movement and the egress cost perspective. For this reason, it is ideal to query the data in place where it lives. We called out some of these challenges from the cyber log data perspective in the IOC matching accelerator.
- Consolidating log data to a single workspace is impossible because of data sovereignty regulations.
- The egress cost to consolidate data from one cloud or region to the central workspace is prohibitive.
In this federation pattern, you will simply reference data where it lives and restrict access to those threat hunters and data scientists who need the ability to query the data. For example, the catalog corresponding to the Delta Share can be controlled with usual ANSI SQL access controls.
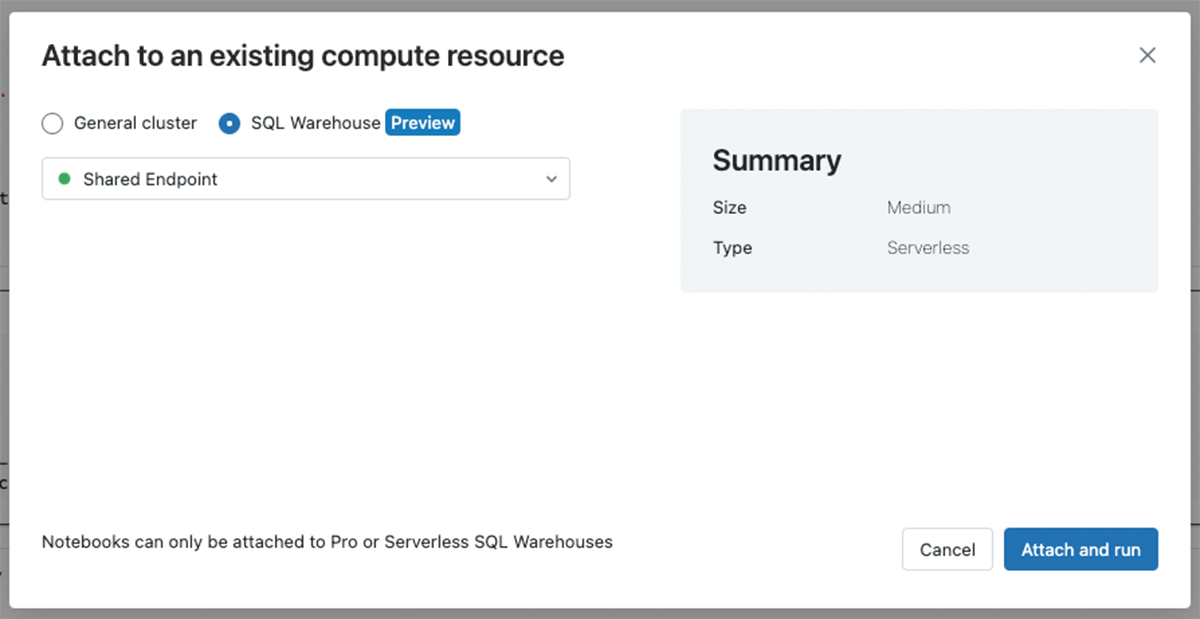
Here are the steps you can now omit from the original Cyber IOC matching accelerator using the Delta Sharing paradigm:
- Configuration of init scripts with a path to your Simba driver jar
- Validate the existing ODBC binary on the cluster
- Manage personal access tokens
- Set up ODBC on your compute cluster to run the federation
- Create an external table with credentials
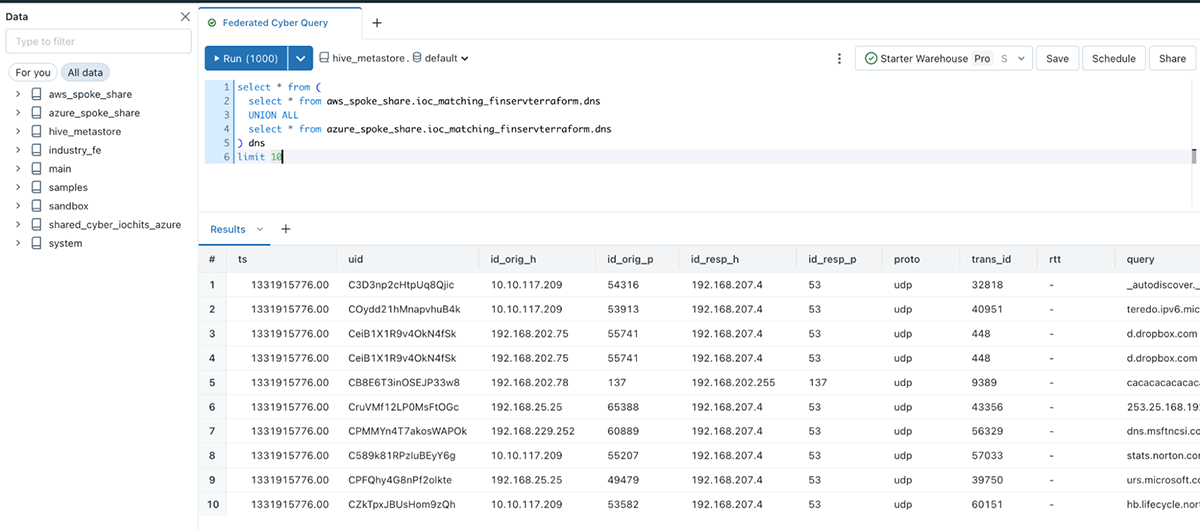
Now, you can just query tables in place from your existing catalog. Below, we are seeing the result of applying our automation - querying all Delta shared log tables from the hub workspace, which runs against Serverless compute for simplified security and data access.
We have drastically simplified data access and avoided expensive data copy steps. Beyond this, we have done this all with an open, extensible format, Delta Lake, which easily supports data sharing.
Conclusion
Multi-cloud efforts are at a major crossroads in today's world. Customers are balancing the cost of replication, cloud data store lock-in, and a data management strategy. For use cases in cybersecurity where data locality is critical, the sharing strategy must be executed thoughtfully. The pillars of TCO, query federation, and governance are critical factors here.
TCO ensures customers keep costs in line, particularly in enhancing security measures. Query federation is vital for real-time threat analysis, all while avoiding the security risks associated with copying data across geographic boundaries. Finally, stringent governance protocols ensure that all data sharing complies with regional and global security regulations. These three tenets are non-negotiable for securing a multi-cloud environment effectively and efficiently and are enabled by Unity Catalog and Delta Sharing, as shown above. Discover the Cybersecurity Lakehouse solutions to understand how to enable more use cases in the cybersecurity ecosystem today.
For further information, check out the blog on "Cybersecurity in the Era of Multiple Clouds and Regions."
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.