How to Build and Scale Multimodal AI Systems on Databricks
by Max Fisher and Colton Peltier
- Why multimodal matters – See how combining text, images, audio, and more unlocks deeper insights and better decision-making for enterprise AI.
- Step-by-step on Databricks – Learn to build an end-to-end multimodal pipeline using PySpark, ai_query(), Databricks AI Search, and Databricks Model Serving.
- Real-world example – Follow a car insurance claim estimator case study that classifies damage from photos and delivers instant cost predictions.
Why Multimodal Matters for Enterprise AI
The real world is multimodal—and your AI should be too. Enterprises can no longer rely on systems that process only text, images, or audio in isolation. This blog post will guide you through the process of implementing and leveraging multimodal AI effectively on the Databricks platform.
Building these systems requires more than just powerful models, it demands a unified platform that can handle diverse data types, scale seamlessly, and embed governance from day one. That’s where Databricks excels, bringing data, AI, and orchestration together for real-world multimodal applications.
With Databricks, enterprises can move from multimodal experimentation to production faster, thanks to integrated capabilities like Databricks Model Serving, AI Search, and Unity Catalog.
Use Cases for Multimodal AI
The applications of multimodal AI across various industries are vast and transformative. Here are a few use cases where combining different data modalities yields significant value:
- Customer Service and Support: A multimodal Customer Service AI system could not only understand a customer's textual query but also analyze their tone of voice (audio) and interpret screenshots or videos (images) of their issue.
- Healthcare and Diagnostics: Multimodal AI can integrate patient records (text), medical images (X-rays, MRIs), and sensor data (heart rate, glucose levels) to provide more precise diagnoses, predict disease progression, and personalize treatment plans.
- Retail and E-commerce: Multimodal AI can process customer reviews (text), product images, and even videos of products in use. This enables businesses to better understand customer preferences, optimize product recommendations, and detect fraudulent activities.
Together, these examples show how multimodal AI can transform industries—but success requires more than just strong models. You need scalable data processing, inference, governance, and storage. Databricks provides the scalable infrastructure and advanced capabilities needed to transform raw data into actionable intelligence, driving innovation and competitive advantage. This blog post will guide you through the process of implementing and leveraging multimodal AI effectively on the Databricks platform.
To highlight the capabilities of a multimodal AI compound system we’ll build a multimodal AI pipeline for a fictional car insurance company, AutomatedAutoInsurance Corp. It will use Batch Inference on historical claims to classify damage and create embeddings for AI Search. These will then be used by a Real-Time Inference application to estimate quotes from customer-submitted images by matching them to similar cases classified by the batch pipeline, allowing us to estimate insurance coverage.
Multimodal AI in Action: Instant Car Insurance Quotes
Imagine a car insurance company who has been in the car insurance business for years. In their historical claims database, they have pictures of damaged cars as well as the total cost associated with the claim. When customers get in a car accident they’re already having a stressful day, and we want to help create the smoothest possible claim experience. We want to create a compound AI system to give customers a real time estimate of their claim cost, just from a picture submitted by the customer at the scene of the accident. To do this we’ll need to create a good understanding of historical claims using batch inference, as well as a real-time multimodal pipeline to enable our clients to get the information they need fast.
Multimodal Batch Inference
Using Model Serving’s Batch Inference, we can take a look at our historical claims dataset and the image data associated with these claims and build classifications of the damage type on the cars. This will help us build consistent classifications of car damage alongside the actual claims data so that we can build proper embeddings to be used in our AI Search index later on.
Databricks ai_query allows the extraction of structured output by specifying the desired JSON schema. This is incredibly powerful as it enforces the desired schema which means you don’t have to write custom parsing code for your LLM outputs! In our case, we want our model to identify some predefined damage types in photographs of cars. We’ll specify the types of damage we want to detect in the JSON schema:
An easy and well known object-oriented way to define classes in python is using Pydantic, if you prefer to define your output schema with Pydantic, check out the code repo for this blog which includes a helper function to convert your Pydantic class to the JSON format for ai_query.
As with all models, our multimodal models will have some best practices or data assumptions. We’ll be using Claude 3.7 Sonnet for this batch use case and it performs best when images have a maximum size of 1568 pixels. We’ll need to make sure we’re resizing our images appropriately.
Now, we can combine this all together to format the ai_query() call.
Which results in this formatted ai_query()
The full batch inference process end to end from reading the images, to re-sizing them, and then applying the batch inference function is encapsulated here where we read the images from a UC Volume.
Resulting in our damage classifications:

Now we need to devise a way to retrieve similar damage claims from historical data when a customer submits a new photo. One possibility is to perform a simple database lookup for other claims with the same damage as the new customer claim. One problem with this idea is figuring out how to handle the case where we see instances of new combinations of damage for which we have no historical data. How will we retrieve the right historical claims to make a good estimate for a new unseen combination of damages?
The retrieval solution we’ll use in this blog is to leverage embeddings. Most embedding retrieval based systems utilize a cosine similarity metric to find the closest other data for lookup. This works well for many use-cases but in our use case we may have damages to multiple parts with the same name. For example, imagine a claim with two damaged Door Panels. If we took the embeddings for “Door Panel” twice and simply averaged it, we’d have the same embeddings as a single Door Panel and our retrieval system would likely be using single Door Panel claims to estimate the new customer claim of two door panels, this would be very inaccurate! Instead we can sum our embeddings for each damaged component together and leverage a euclidean distance metric to retrieve similar claims. This would ensure that claims with multiple damaged components of the same type were still well represented, but also logically close to just one instance of that damaged component.
Databricks vector search implements euclidean (or “L2”) distance by default, so we only need to modify our embedding computation logic to get the desired results.
Then we can create our AI Search index:
Now we can do a simple test, with a damage claim combination not seen in any of our historical data:
Which prints off the top 5 closest historical damage claims:
Which finds some interestingly close historical claims, even though no exact match was found! Each of the returned claims has at least one of the parts from the new claim, and each is a multi-component damage claim.
Multimodal Real-Time Inference
Now with our AI Search Index created, we can combine that with our helper functions for processing the images, calculating embeddings, and establishing a output schema via a Pydantic Model into a pyfunc definition for an agent that can:
- Take an image of car damage as input
- Process the image
- Calculate the processed image’s embedding
- Use that to do a similarity search with our AI Search Index
- Use the similar claims to get an average claim cost
- Return the estimate and assessment to the user
Here is our predict() portion of the pyfunc definition for the agent (since some of the functions are referenced above we removed some of the code for brevity, but you can see the full example here on GitHub):
We basically run through the same process that we do in our batch example, but we take that last step of taking the damage analysis that we get from doing the image-to-text generation, and do a similarity search on past accidents to get cost data for us to calculate an estimate.
When we test our pyfunc agent, we can do each of the steps we talked about above. With MLflow 3.0 we can see the whole process end-to-end in the visual trace.
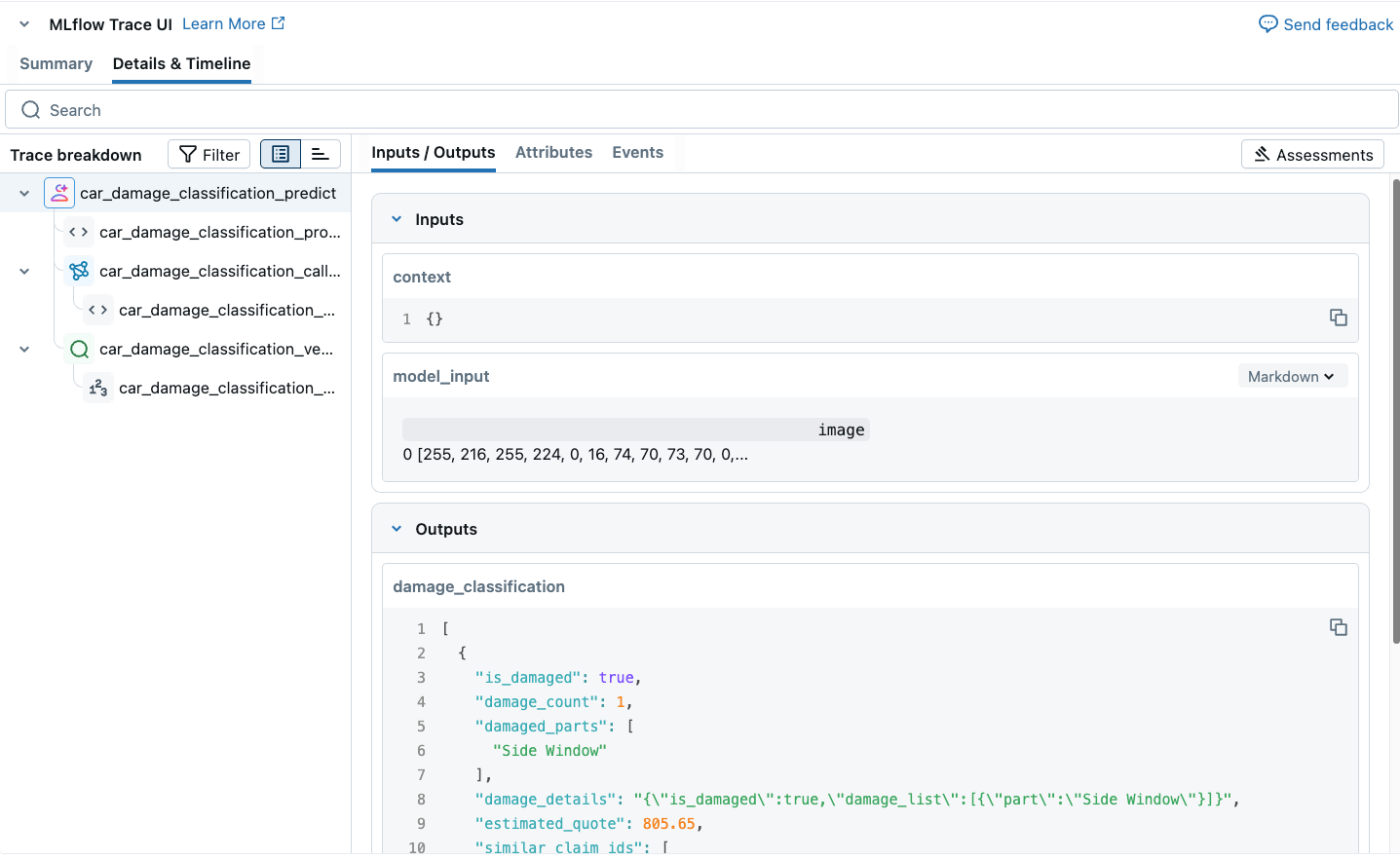
After logging, registering and then deploying the model to Databricks Model Serving it is now available for our Quote Estimator Application, and users can upload their car damage photos and get an estimate for the cost of the damages to their vehicle.

Get Started
Building powerful multimodal compound AI systems doesn’t have to be complex. Databricks has powerful features like PySpark, ai_query(), Databricks AI Search, and Databricks Model Serving which work together to simplify your end-to-end AI system workflow.
For batch inference GenAI work, use Pyspark with ai_query() to automatically scale your multimodal inference. Databricks AI Search allows powerful indexing and querying of embeddings to quickly build a production grade retrieval system. Databricks Databricks Model Serving allows you to deploy production grade endpoints which can put all of your application logic together. Built in multimodal foundation models, like Claude and Llama4, allow you to begin prototyping and launching multimodal systems right away.
As always, make sure you follow best practices for whichever model you choose to use. If you’re performing image analysis, like we did in this blog’s example, reference the below table to find the optimal max image dimensions to use for a variety of popular multimodal models.
| Model Family | Optimal Max Image Dimensions (pixels) |
|---|---|
| Llama 4 | 336 |
| Claude | 1568 |
| Gemma | 896 |
By leveraging Databricks’ advanced GenAI capabilities you can get started building multimodal AI today.
Get started with the below resources:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.