How Edmunds builds a blueprint for generative AI
by Bryan Smith, Sam Steiny and Greg Rokita

This blog post is in collaboration with Greg Rokita, AVP of Technology at Edmunds.
Long envisioned as a key milestone in computing, we've finally arrived at the moment where machines can seemingly understand us and respond in our own natural language. While no one should be confused that large language models (LLMs) only give the appearance of intelligence, their ability to engage us on a wide range of topics in an informed, authoritative, and at times creative manner is poised to drive a revolution in the way we work.
Estimates from McKinsey and others are that by 2030, tasks currently consuming 60 to 70% of employees' time could be automated using these and other generative AI technologies. This is driving many organizations, including Edmunds, to explore ways to integrate these capabilities into internal processes as well as customer facing products, to reap the benefits of early adoption.
In pursuit of this, we recently sat down with the folks at Databricks, leaders in the data & AI space, to explore lessons learned from early attempts at LLM adoption, past cycles surrounding emerging technologies and experiences with companies with demonstrated track records of sustained innovation.
Edmunds is a trusted car shopping resource and leading provider of used vehicle listings in the United States. Edmunds' site offers real-time pricing and deal ratings on new and used vehicles to provide car shoppers with the most accurate and transparent information possible. We are constantly innovating, and we have multiple forums and conferences focused on emerging technologies, such as Edmunds' recent LLMotive conference.
From this conversation, we've identified four mandates that inform our go-forward efforts in this space.
Embrace Experimentation
It's easy at this moment to forget just how new Large Language Models (LLMs) are. The transformer architecture, on which these models are based, was introduced in 2017 and remained largely off the mainstream radar until November 2022 when OpenAI stunned the world with Chat GPT. Since then, we've seen a steady stream of innovation from both tech companies and the open source community. But it's still early days in the LLM space.
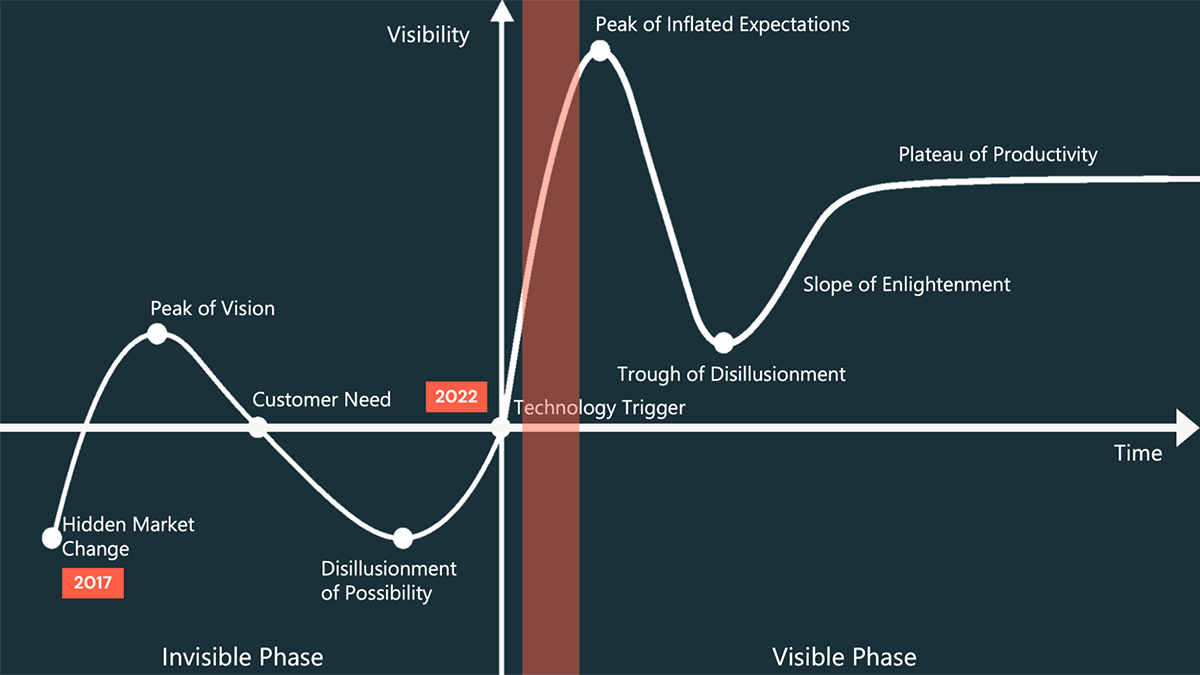
As with every new technology, there is a period following mainstream awareness where excitement over the potential of the technology outpaces its reality. Captured neatly in classic hype cycle (Figure 1), we know we are headed towards the Peak of Inflated Expectations followed by a crash into the Trough of Disillusionment within which frustrations over organizations' abilities to meet those expectations force many to pause their efforts with the technology. It's hard to say exactly where we are in the hype cycle, but given we are not even 1 year out from the release of Chat GPT, it feels safe to say we have not yet hit the peak in the hype cycle.
Given this, organizations attempting to use the technology should expect rapid evolution and more than a few rough edges and outright feature gaps. In order to deliver operational solutions, these innovators and early adopters must be committed to overcome these challenges on their own and with the support of technical partners and the open source community. Companies are best positioned to do this when they embrace such technology as either central to their business model or central to the accomplishment of a compelling business vision.
But sheer talent and will do not guarantee success. In addition, organizations embracing early stage technologies such as these recognize that it's not just the path to their destination that's unknown but the destination itself may not exist exactly in the manner it's initially envisioned. Rapid, interactive experimentation is required to better understand this technology in its current state and the feasibility of applying it to particular needs. Failure, an ugly word in many organizations, is embraced if that failure was arrived at quickly and efficiently and generated knowledge and insights that inform the next iteration and the many other experimentation cycles underway within the enterprise. With the right mindset, innovators and early adopters can develop a deep knowledge of these technologies and deliver robust solutions ahead of their competition, giving them an early advantage over others who might prefer to wait for it to mature.
Edmunds has created an LLM incubator to test and develop large language models (LLMs) from third-party and internal sources. The incubator's goal is to explore capabilities, and develop innovative business models—not specifically to launch a product. In addition to developing and demonstrating capabilities, the incubator also focuses on acquiring knowledge. Our engineers are able to learn more about the inner workings of LLMs and how they can be used to solve real-world problems.
Preserve Optionality
Continuing with the theme of technology maturity, it's worth noting an interesting pattern that occurs as a technology passes through the Trough of Disillusionment. Explained in-depth in Geoffrey A. Moore's classic book, Crossing the Chasm, many of the organizations that bring a particular technology to market in the early stages of its development struggle to transition into long-term mainstream adoption. It's at the trough that many of these companies are acquired, merge or simply fade away because of this difficulty that we see over and over again.
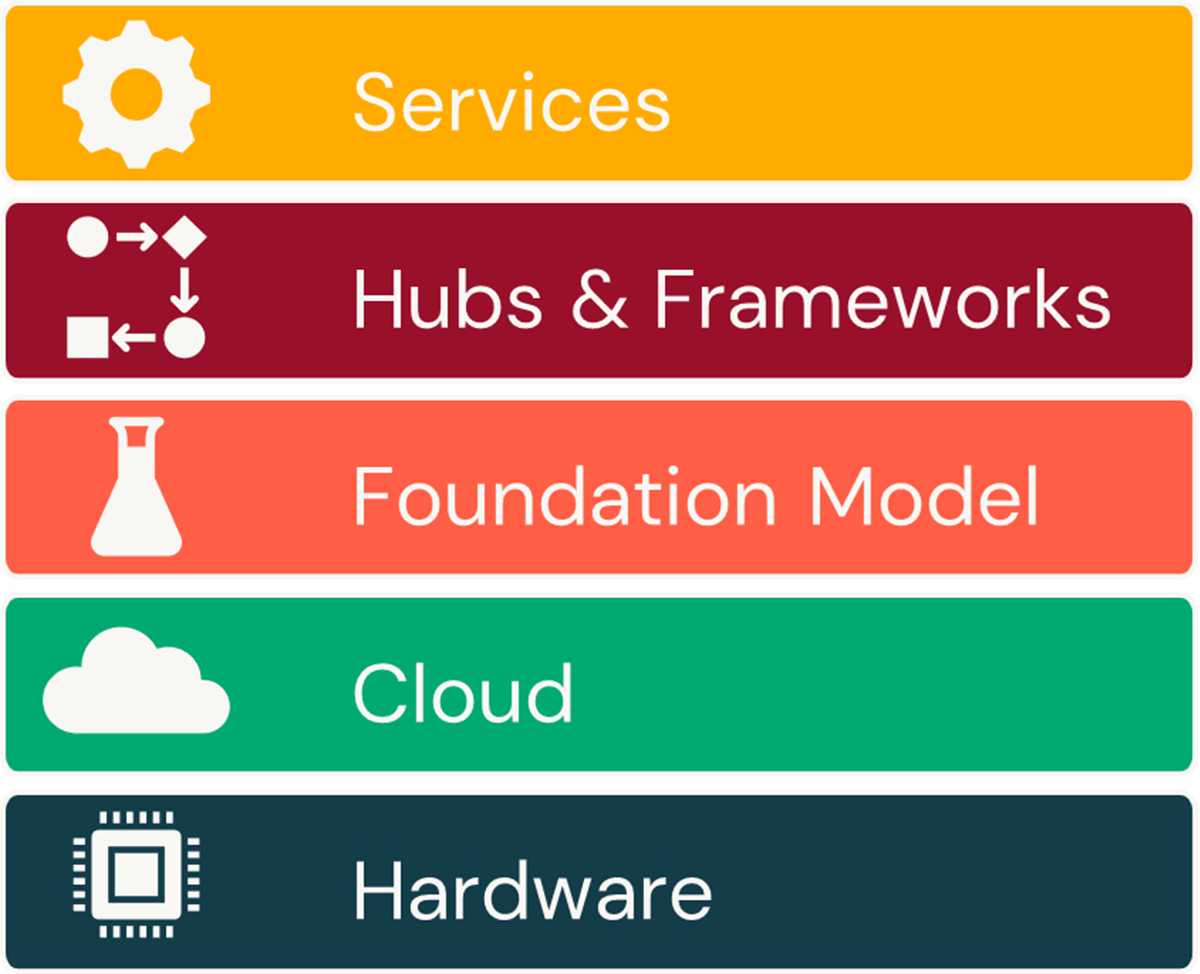
If we apply this thinking to the LLM space in its entirety (Figure 2), we can see the seeds for much of this turmoil already being sown. While NVidia has a strong grip on the GPU market - GPUs being a critical hardware resource for most LLM training efforts - organizations such as MosaicML are already showing ways in which these models can be trained on much lower cost AMD devices. In the cloud, the big three, i.e. AWS, Azure and GCP, have embraced LLM technologies as a vehicle for growth, but seemingly out of nowhere, the Oracle Cloud has entered into the conversation. And while OpenAI was first out the gate with ChatGPT closely followed by various Google offerings, there has been an explosion in foundation models from the open source community that challenge their long-term position in the market. This last point deserves a bit more examination.
In May 2023, a leaked memo from Google titled We Have No Moat, And Neither Does OpenAI, highlighted the rapid and stunning advancements being made by the open source community in catching up with OpenAI, Google and other big tech firms who made early entrances into this space. Since the release of the original academic paper that launched the transformer movement, there has always been a small open source community actively working to build LLMs. But these efforts were turbo-charged in February when Meta (formerly-Facebook) opened up their LLaMA model to this community. Within one month, researchers at Stanford showed they could create a model capable of closely imitating the capabilities of ChatGPT. Within a month of that, Databricks released Dolly 1.0, showing they could create an even smaller, simpler model capable of running on more commodity infrastructure and achieving similar results. Since then, the open source community has only snowballed in terms of the speed and breadth of this innovation in this space.
All of this is to say that the LLM models and the entire ecosystem surrounding them is in flux. For many organizations, there is a desire to pick the winning technology in a given space and build their solutions on these. But given the state of the market, it's impossible to say at this time exactly who the winners and losers will be. Smart organizations will recognize the fluidity of the market and keep their options open until we pass through the eventual shakeout that comes with passing through the trough and that time select those components and services that best align their objectives around return on investment and total cost of ownership. But at this moment, time to market is the guide.
But what about the debt that comes with choosing the wrong technology? In advocating for choosing the best technology at the moment, we are seeking to avoid analysis paralysis but fully recognize that organizations will make some technology choices they will later regret. As members of organizations with long histories of early innovation, the best guidance at this stage is to adhere to design patterns such as the use of abstractions and decoupled architectures and embrace agile CI/CD processes that allow organizations to rapidly iterate solutions with minimal disruption. As new technologies emerge that offer compelling advantages, these can be used to displace previously selected components with less effort and impact on the organization. It's not a perfect solution but getting a solution out the door requires decisions to be made in the face of an immense amount of uncertainty that will not be resolved for quite some time.
At Edmunds, we understand that the field of AI is constantly evolving, so we don't rely on a single approach to success. We offer access to a variety of third-party LLMs, while also investing in making open-source models operational and tailored to the automotive vertical. This approach gives us flexibility in terms of cost-efficiency, security, privacy, ownership, and control of LLMs.
Innovate at the Core
If we are comfortable with the technology and we have the right mindset and technology approach to building LLM applications, which applications should we build? Instead of using risk avoidance as the governing strategy for deciding when and where to employ these technologies, we focus on the potential for value generation in both the short and the long-term.
This means we need to start with an understanding of what we do today and where it is we could do those things smarter. This is what we call innovation at the core. Core innovations are not sexy, but they are impactful. They help us improve efficiency, scalability, reliability and consistency of what we do. We have existing business stakeholders, not only invested in those improvements, but also with the ability to assess the impact of what we deliver. We also have the surrounding processes required to put these into production and monitor their impact on an on-going basis.
The core innovations are important because they give us the ability to have an impact while we learn these new technologies. They also help us establish trust with the business and to evolve the processes that allow us to bring ideas into production. The momentum we build with these core innovations give us the capability and credibility to take bigger risks, to move into new areas related to our core capabilities but which extend and enhance what we do today. We refer to these as the adjacent innovations. As we begin to demonstrate success with adjacent innovations, again we build the momentum not only with the technology but with our stakeholders to take on even bigger and even less certain innovations that have the potential to truly transform our business.
There are many out there in the digital transformation community who advocate against this more incremental approach. And while their concerns that efforts that are too small are unlikely to yield the kinds of results that lead to true transformation are legitimate, the flip side that we have witnessed over and over again is that technology efforts that are not grounded in prior successes that have included the support of the business struggle to achieve operationalization. Moving from the core to adjacent to transformative levels of innovation does not need to be a dawdling process, but it does need to move at a pace at which both the technical and business sides of any solution can keep up with one another.
We believe at Edmunds that semi-autonomous AI agents will become critical to every business in the long term. While short-term developments in the generative AI space are uncertain, we are focused on building core capabilities in the automotive vertical. This will allow Edmunds to spin off efforts into more tactical and scope-limited use cases. However, we are taking a holistic and strategic approach to AI, with the goal of being in a pole position if the AI revolution drastically forces changes in the business models of data aggregators and curators. We are not afraid to disrupt ourself in order to maintain leadership in our domain, based on many lessons from history.
Establish a Data Foundation
As we examine what all is required to build an LLM application, the one component often overlooked is the unstructured information assets within the organization around which most solutions are to be based. While pre-trained models provide a foundational understanding of a language, it's through exposure to an organization's information assets that these models are capable of speaking in a manner that's consistent with an organization's needs.
But while we've been advocating for years for the better organization and management of this information, much of that dialog has been focused on the explosive growth of unstructured content and the cost implications of attempting to store it. Lost in this conversation is thought about how we identify new and modified content, move it into an analytics environment and assess it for sensitivity, appropriate use and quality prior to use in an application.
That's because up until this moment, there were very few compelling reasons to consider these assets as high-value analytic resources. As a result, one Deloitte survey found that only 18% of organizations were leveraging unstructured data for any kind of analytic function, and it seems highly unlikely that many of those were considering systemic means of managing these data for broader analytic needs. As a result, we have seen more instances than not of organizations identifying compelling uses for LLM technology and then wrestling to acquire the assets needed to begin development, let alone sustain the effort as those assets expand and evolve over time.
While we don't have an exact solution to this problem, we think it's time that organizations begin identifying where within their organizations the highest value information assets required by LLM applications likely reside and begin exploring the creation of frameworks to move these into an analytics lakehouse architecture. Unlike the ETL frameworks developed in decades past, these frameworks will need to recognize that these assets are created outside of tightly governed and monitored operational solutions and will need to find ways to keep up with new information without interfering with the business processes dependent upon their creation.
These frameworks will also need to recognize the particular security and governance requirements associated with these documents. While high-level policies might define a range of appropriate uses for a set of documents, information within individual documents may need to be redacted in some scenarios but possibly not others before they can be employed. Concerns over the accuracy of information in these assets should also be considered, especially where documents are not frequently reviewed and authorized by gatekeepers in the organization.
The complexity of the challenges in this space not to mention the immense volume of data in play will require new approaches to information management. But for organizations willing to wade into these deep waters, there's the potential to create a foundation likely to accelerate the implementation of a wide variety of LLM applications for years to come.
A data-centric approach is at the heart of Edmunds' AI efforts. By working with Databricks, our teams at Edmunds are able to offload non-business-specific tasks to focus on data repurposing and automotive-specific model creation. Edmunds' close collaboration with Databricks on a variety of products ensures that our initiatives are aligned with new product and feature releases. This is crucial in light of the rapidly evolving landscape of AI models, frameworks, and approaches. We are confident that a data-centric approach will enable us to decrease bias, increase efficiency, reduce costs in our AI efforts and create accurate industry-leading models and AI agents.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.