How the Lakehouse can optimize provider networks and improve member care
by Aaron Zavora
Check out our Nearest Neighborhood Search Solution Accelerator to get started quickly.
The Member Experience
An insured member typically experiences their healthcare in two settings. The first, and most relatable, is that with their healthcare providers, both primary care physicians (PCPs) and specialists across a range of various inpatient and ambulatory settings. The other experience encompasses all of the interactions with their health plan, which consists of annual benefit enrollment, claim payments, care discovery portals, and, on occasion, care management teams that are designed to support member care.
These separate interactions by themselves are fairly complex – some examples include scheduling services, provider treatment across all types of chronic and acute conditions, medical reimbursement, and adjudication through a complex and lengthy billing cycle. Fairly invisible to the member (except for an in- or out-of-network provider status) is a third interaction between the insurer and provider that plays a critical role in how healthcare is delivered, and that is the provider network offering.
Health plans routinely negotiate rates and credential providers to participate in their plan offerings. These network offerings vary across Medicare, Medicaid, and Commercial members, and can vary across employer plan sponsors. Different types of networks can be attached to different insurance products, offering different incentives to all parties involved. For example, narrow networks are intended to offer lower premiums and out-of-pocket costs in exchange for having a smaller, local group of providers in the network.
Health plans have incentives to optimize the provider network offering to plan sponsors because an optimal provider network delivers better quality care for patients, at a lower cost. Such networks can better synthesize care treatment plans, reduce fraud and waste, and offer equitable access to care to name a few benefits.
Building an optimal network is easier said than done, however.
Optimizations Behind the Scenes
Optimization is not straightforward. The Healthcare Effectiveness Data and Information Set (HEDIS) is a tool used by more than 90 percent of U.S. health plans to measure performance on important dimensions of care and service. A network excelling at a HEDIS measure of quality such as Breast Cancer Screening is not useful for a population that doesn't consist of women over the age of 50. Analysis is fluid as the needs of a member population and strengths of a physician group continuously evolve.
Compounding the analysis of aligning membership needs to provider capabilities is understanding who has access to care from a geospatial point of view. In other words, are members able to physically access appropriate provider care because that provider is reachable in terms of distance between locations. This is where Databricks, built on the highly scalable compute engine Apache Spark™, differentiates itself from historical approaches to the geospatial neighbor problem.
Solution Accelerator for Scalable Network Analysis
Healthcare geospatial comparisons are generally phrased as "Who are the closest 'X' providers located within 'Y' distance of members?" This is the foundational question to understand who can provide the highest quality of care or provide speciality services to a given member population. Answering this question historically falls into either geohashing, an approach that essentially subdivides space on a map and buckets points in a grid together - allowing for scalability but leading to results that lack precision, or direct comparison of points and distance which is accurate but not scalable.
Databricks solves for both scalability and accuracy with a solution accelerator by leveraging various strengths within the Spark ecosystem. Input framing matches the general question of, given a "Y" radius, return the nearest "X" locations, and data input requires latitude/longitude values and optionally accepts an identifier field that can be used to more easily relate data.
Configuration parameters in the accelerator include setting the degree of parallelism to distribute compute for faster runtimes,, a serverless connection string (serverless is a key component to the scalability and further described below), and a temporary working table that is used as a fast data cache operation and optimized using Spark Indexes (ZOrder) as a placeholder for your data.
Output from this solution accelerator provides the origin location as well as an array of all surrounding neighbors, their distances from the origin, and the search time for each record (to allow further optimizations and tuning).
So how & why does this scalability work?
It is important to note that Spark is a horizontally scalable platform. Meaning, it can scale similar tasks across an infinite number of machines. Using this pattern, if we are able to compute a highly efficient calculation for one member and its nearest neighboring provider locations, we can infinitely scale this solution using Spark.
For the fast neighborhood search of a single member, we need a reasonably efficient pruning technique so that we do not need to search the entire provider dataset every single time and very fast data retrieval (consistently sub-second response). The initial approach to pruning uses a type of geohash for this, but in the future will move to a more efficient methodology with Databricks H3 representations. For very fast retrieval, we initially explored using a cloud NoSQL, but we achieved drastically better results using Databricks Serverless SQL and Spark indexes (the original code for CosmosDB is included and can be implemented on other NoSQLs). The architecture for the Solution Accelerator looks like this:
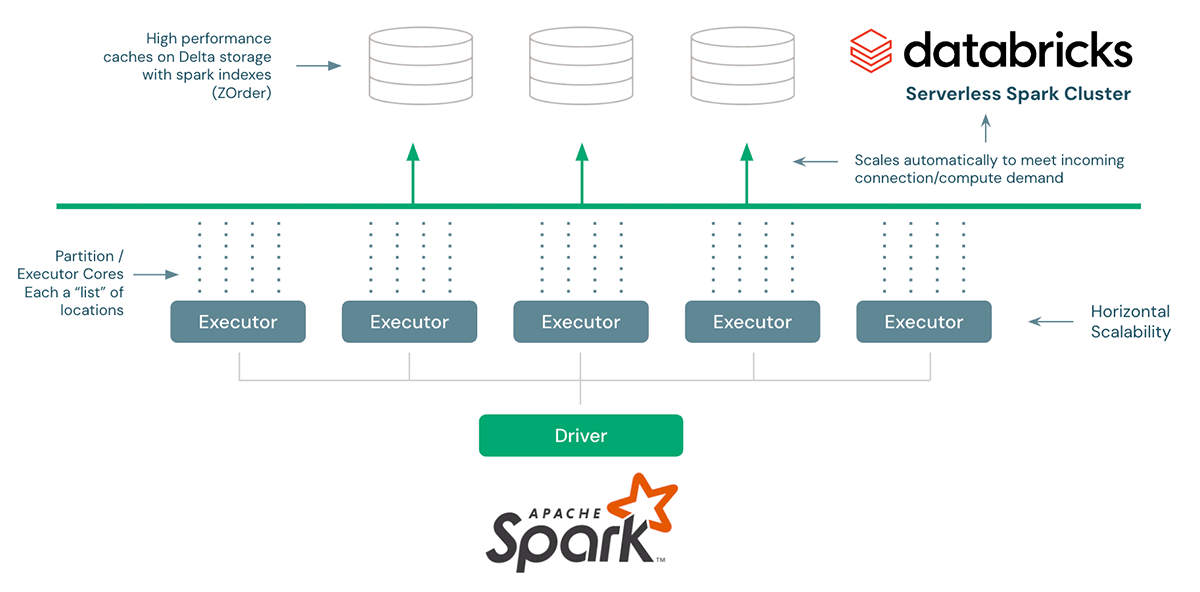
Spark traditionally has neither been efficient on small queries nor provides scalable JDBC connection management to run diverse, massively parallel workloads. This is no longer the case when using the Databricks Lakehouse, which includes Serverless SQL and Delta Lake along with techniques like ZOrder indexes. In addition, Databricks' recent announcement of liquid clustering will offer an even more performant alternative to ZOrdering.
And finally, a quick note on scaling this accelerator. Because runtimes are dependent on a combination of non-trivial factors like the density of the locations, radius of search, and max results returned, we therefore provide enough visibility into performance to be able to tune this workload. The horizontal scale previously mentioned occurs through increasing the number of partitions in the configuration parameters. Some quick math with the total number of records, average lookup time, and number of partitions tells you expected runtime. As a general rule, have 1 CPU aligned to each partition (this number can vary depending on circumstances).
Sample Analysis Use Cases
Analysis at scale can provide valuable information like measuring equitable access to care, providing cost effective recommendations on imaging or diagnostic testing locations, and being able to appropriately refer members to the highest performing providers reachable. Evaluating the right site of care for a member, similar to the competitive dynamics seen in health plan price transparency, is a combination of both price and quality.
These use cases result in tangible savings and better outcomes for patients. In addition, nearest neighbor searches can be applied beyond just for a health plan network. Providers are able to identify patient utilization patterns, supply chains can better manage inventory and re-routing, and pharmaceutical companies can improve detailing programs.
More Ways to Build Smarter Networks with Better Quality Data
We understand not every healthcare organization may be in a position where they are ready to analyze provider data in the context of network optimization. Ribbon Health, an organization specializing in provider directory management and data quality, offers built on Databricks solutions to provide a foundational layer that can help organizations more quickly and effectively manage their provider data.
Ribbon Health is one of the early partners represented in the Databricks Marketplace, an open marketplace for exchanging data products such as datasets, notebooks, dashboards, and machine learning models. You can now find Ribbon Health's Provider Directory & Location Directory on the Databricks Marketplace so health plans and care providers/navigators can start using this data today.
The data includes NPIs, practice locations, contact information with confidence scores, specialties, location types, relative cost and experience, areas of focus, and accepted insurance. The dataset also has broad coverage, including 99.9% of providers, 1.7M unique service locations, and insurance coverage for 90.1% of lives covered across all lines of business and payers. The data is continuously checked and cross-checked to ensure the most up-to-date information is shown.
Provider networks, given their role in cost and quality, are foundational to both the performance of the health plan and member experience. With these data sets, organizations can now more efficiently manage, customize, and maintain their own provider data.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.