Unifying Your Data Ecosystem with Delta Lake Integration
Reading and Writing from and to Delta Lake from non-Databricks platforms
by Itai Yaffe and Liran Bareket
As organizations are maturing their data infrastructure and accumulating more data than ever before in their data lakes, Open and Reliable table formats such as Delta Lake become a critical necessity.
Thousands of companies are already using Delta Lake in production, and open-sourcing all of Delta Lake (as announced in June 2022) has further increased its adoption across various domains and verticals.
Since many of those companies are using both Databricks and other data and AI frameworks (e.g., Power BI, Trino, Flink, Spark on Kubernetes) as part of their tech stack, it’s crucial for them to be able to read and write from/to Delta Lake using all those frameworks.
The goal of this blog post is to help these users do so, as seamlessly as possible.
Integration Options
Databricks provides multiple options to read data from and write data to the lakehouse. These options vary from each other on various parameters. Each of these options match different use cases.
The parameters we use to evaluate these options are:
- Read Only/Read Write - Does this option provide read/write access or read only.
- Upfront investment - Does this integration option require any custom development or setting up another component.
- Execution Overhead - Does this option require a compute engine (cluster or SQL warehouse) between the data and the client application.
- Cost - Does this option entail any additional cost (beyond the operational cost of the storage and the client).
- Catalog - Does this option provide a catalog (such as Hive Metastore) the client can use to browse for data assets and retrieve metadata from.
- Access to Storage - Does the client need direct network access to the cloud storage.
- Scalability - Does this option rely on scalable compute at the client or provides compute for the client.
- Concurrent Write Support - Does this option handle concurrent writes, allowing write from multiple clients or from the client and Databricks at the same time. (Docs)
Direct Cloud Storage Access
Access the files directly on the cloud storage. External tables (AWS/Azure/GCP) in Databricks Unity Catalog (UC) can be accessed directly using the path of the table. That requires the client to store the path, have a networking path to the storage, and have permission to access the storage directly.
a. Pros
- No upfront investment (no scripting or tooling is required)
- No execution overhead
- No additional cost
b. Cons
- No catalog - requires the developer to register and manage the location
- No discovery capabilities
- Limited Metadata (no Metadata for non delta tables)
- Requires access to storage
- No governance capabilities
- No table ACLs: Permission managed at the file/folder level
- No audit
- Limited concurrent write support
- No built in scalability - the reading application has to handle scalability in case of large data sets
c. Flow:
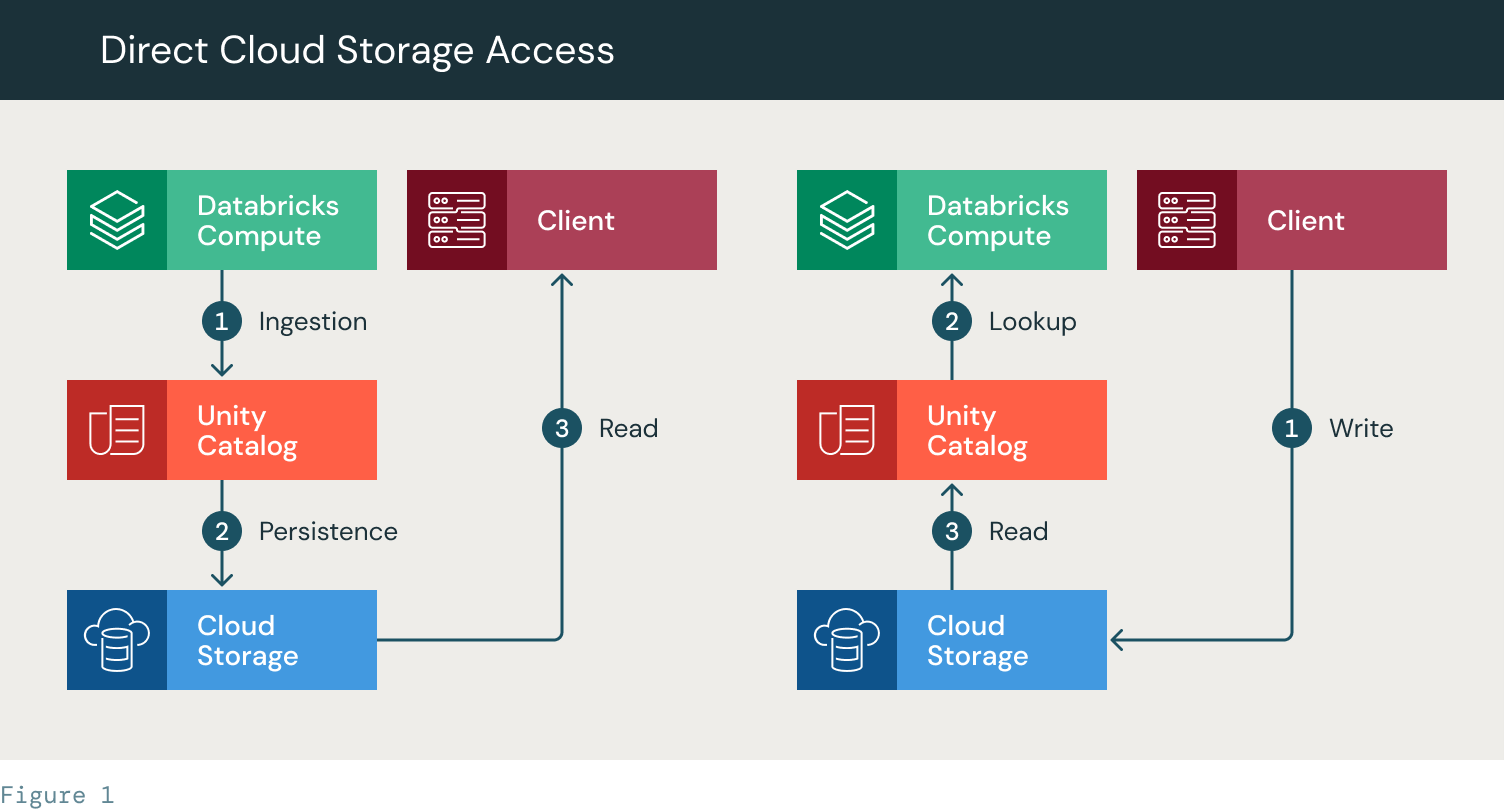
- Read:
- Databricks perform ingestion (1)
- It persists the file to a table defined in Unity Catalog. The data is persisted to the cloud storage (2)
- The client is provided with the path to the table. It uses its own storage credentials (SPN/Instance Profile) to access the cloud storage directly to read the table/files.
- Write:
- The client writes directly to the cloud storage using a path. The path is then used to create a table in UC. The table is available for read operations in Databricks.
External Hive Metastore (Bidirectional Sync)
In this scenario, we sync the metadata in Unity Catalog with an external Hive Metastore (HMS), such as Glue, on a regular basis. We keep one or more databases in sync with the external directory. This will allow a client using a Hive-supported reader to access the table. Similarly to the previous solution it requires the client to have direct access to the storage.
a. Pros
- Catalog provides a listing of the tables and manages the location
- Discoverability allows the user to browse and find tables
b. Cons
- Requires upfront setup
- Governance overhead - This solution requires redundant management of access. The UC relies on table ACLs and Hive Metastore relies on storage access permissions
- Requires a custom script to keep the Hive Metastore metadata up to date with the Unity Catalog metadata
- Limited concurrent write support
- No built in scalability - the reading application has to handle scalability in case of large data sets
c. Flow:
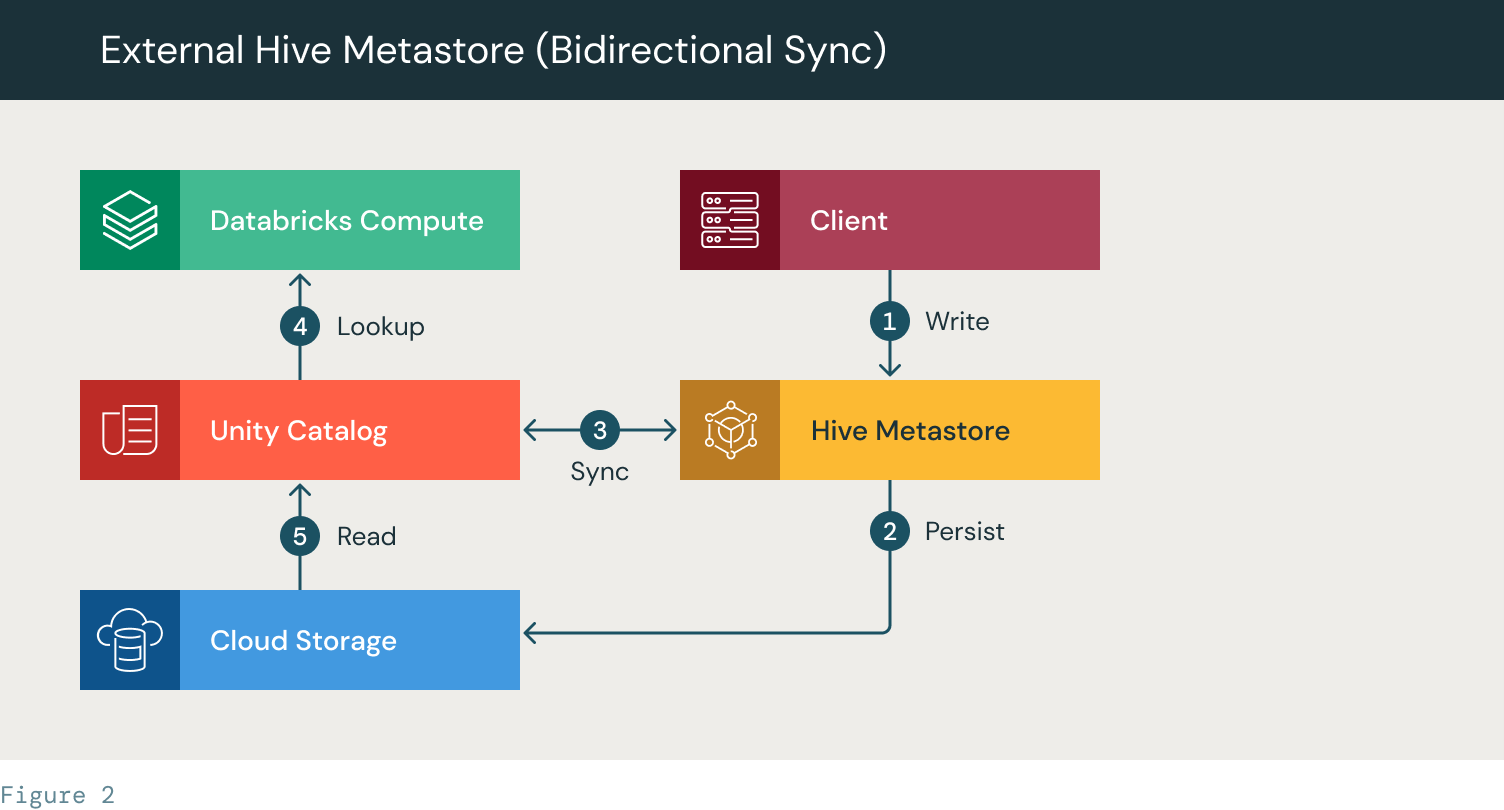
- The client creates a table in HMS
- The table is persisted to the cloud storage
- A Sync script (custom script) syncs the table metadata between HMS and Unity Catalog
- A Databricks cluster/SQL warehouse looks up the table in UC
- The table files are accessed using UC from the cloud storage
Delta Sharing
Access Delta tables via Delta Sharing (read more about Delta Sharing here).
The data provider creates a share for existing Delta tables, and the data recipient can access the data defined within the share configuration. The Shared data is kept up to date and supports real time/near real time use cases including streaming.
Generally speaking, the data recipient connects to a Delta Sharing server, via a Delta Sharing client (that’s supported by a variety of tools). A Delta sharing client is any tool that supports direct read from a Delta Sharing source. A signed URL is then provided to the Delta Sharing client, and the client uses it to access the Delta table storage directly and read only the data they’re allowed to access.
On the data provider end, this approach removes the need to manage permissions on the storage level and provides certain audit capabilities (on the share level).
On the data recipient end, the data is consumed using one of the aforementioned tools, which means the recipient also needs to handle the compute scalability on their own (e.g., using a Spark cluster).
a. Pros
- Catalog + discoverability
- Doesn’t require permission to storage (done on the share level)
- Gives you audit capabilities (albeit limited - it’s on the share level)
b. Cons
- Read-only
- You need to handle scalability on your own (e.g., use Spark)
i. Flow:
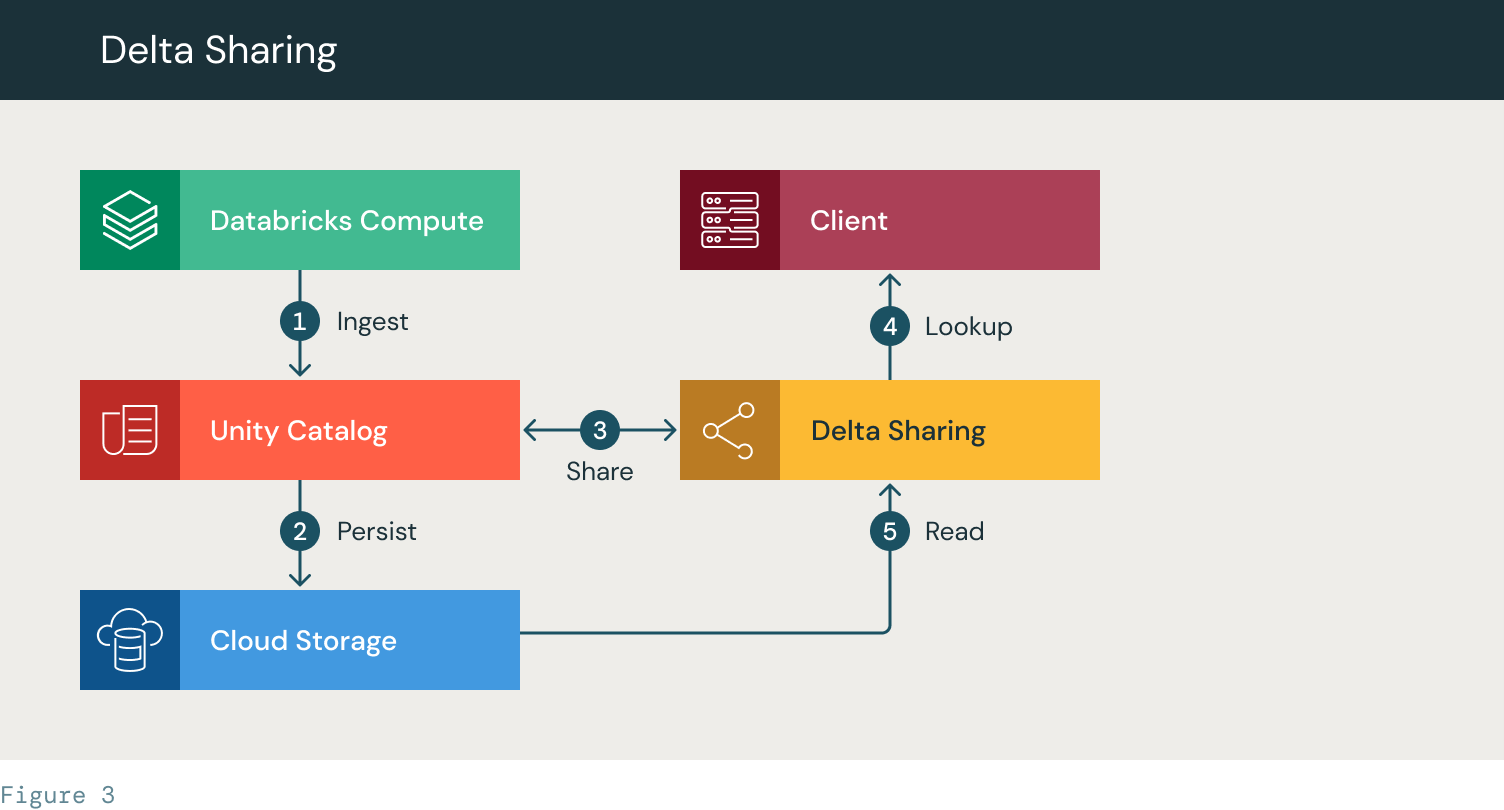
- Databricks ingests data and creates a UC table
- The data is saved to the cloud storage
- A Delta Sharing provider is created and the table/database is shared. The access token is provided to the client
- The client accesses the Delta Sharing server and looks up the table
- The Client is provided access to read the table files from the cloud storage
JDBC/ODBC connector (write/read from anywhere using Databricks SQL)
The JDBC/ODBC connector allows you to connect your backend application, using JDBC/ODBC, to a Databricks SQL warehouse (as described here).
This essentially is no different than what you’d normally do when connecting backend applications to a database.
Databricks and some third party developers provide wrappers for the JDBC/ODBC connector that allow direct access from various environments, including:
This solution is suitable for standalone clients, as the computing power is the Databricks SQL warehouse (hence the compute scalability is handled by Databricks).
As opposed to the Delta Sharing approach, the JDBC/ODBC connector approach also allows you to write data to Delta tables (it even supports concurrent writes).
a. Pros
- Scalability is handled by Databricks
- Full governance and audit
- Easy setup
- Concurrent write support (Docs)
b. Cons
- Cost
- Suitable for standalone clients (less for distributed execution engines like Spark)
l. Workflow:
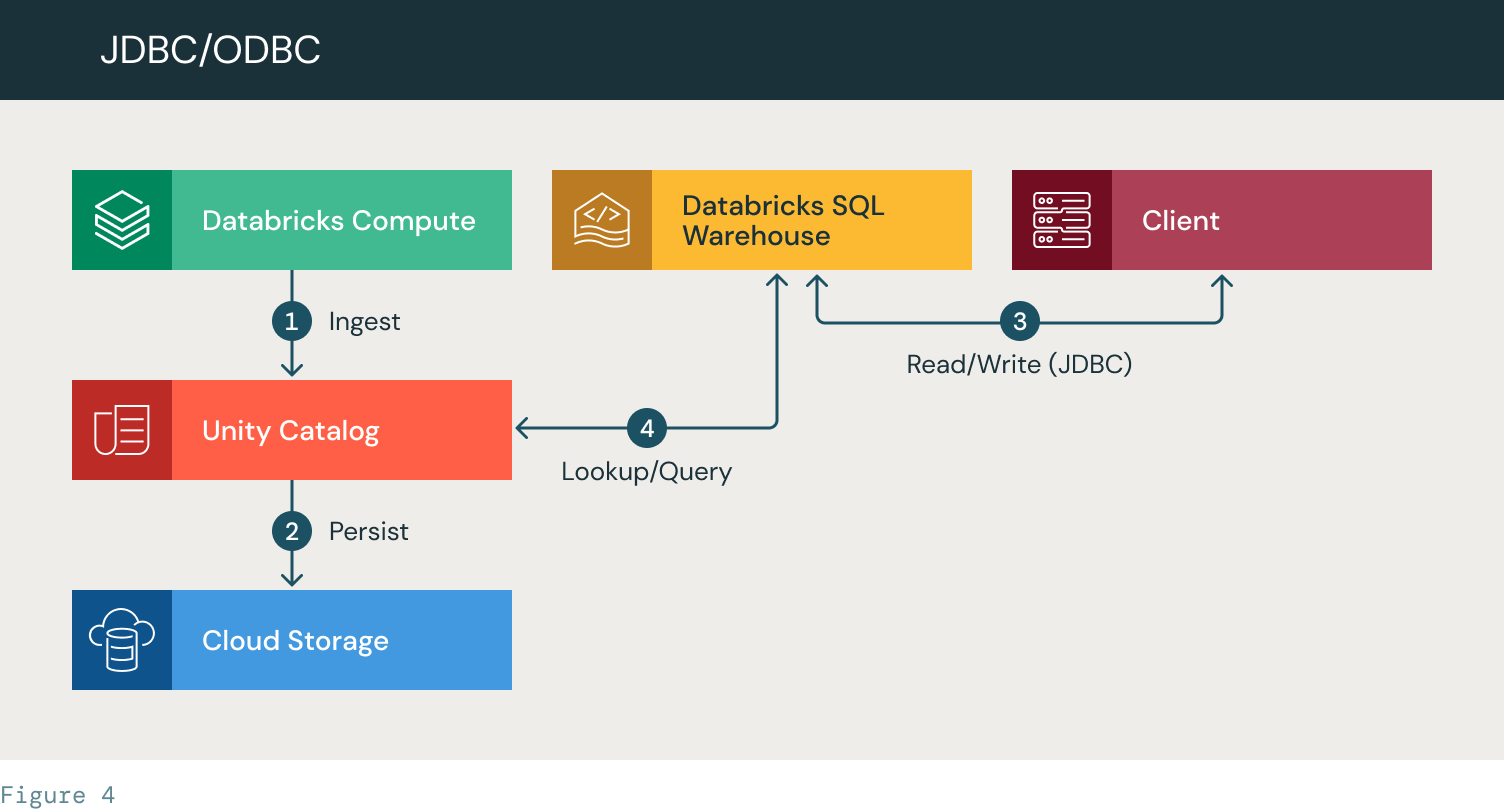
- Databricks ingests data and creates a UC table
- The data is saved to the cloud storage
- The client uses a JDBC connection to authenticate and query a SQL warehouse
- The SQL warehouse looks up the data in Unity Catalog. It applies ACLs, accesses the data, performs the query and returns a result set to the client
c. Note that if you have Unity Catalog enabled on your workspace, you also get full governance and audit of the operations. You can still use the approach described above without Unity Catalog, but governance and auditing will be limited.
d. This is the only option that supports row level filtering and column filtering.
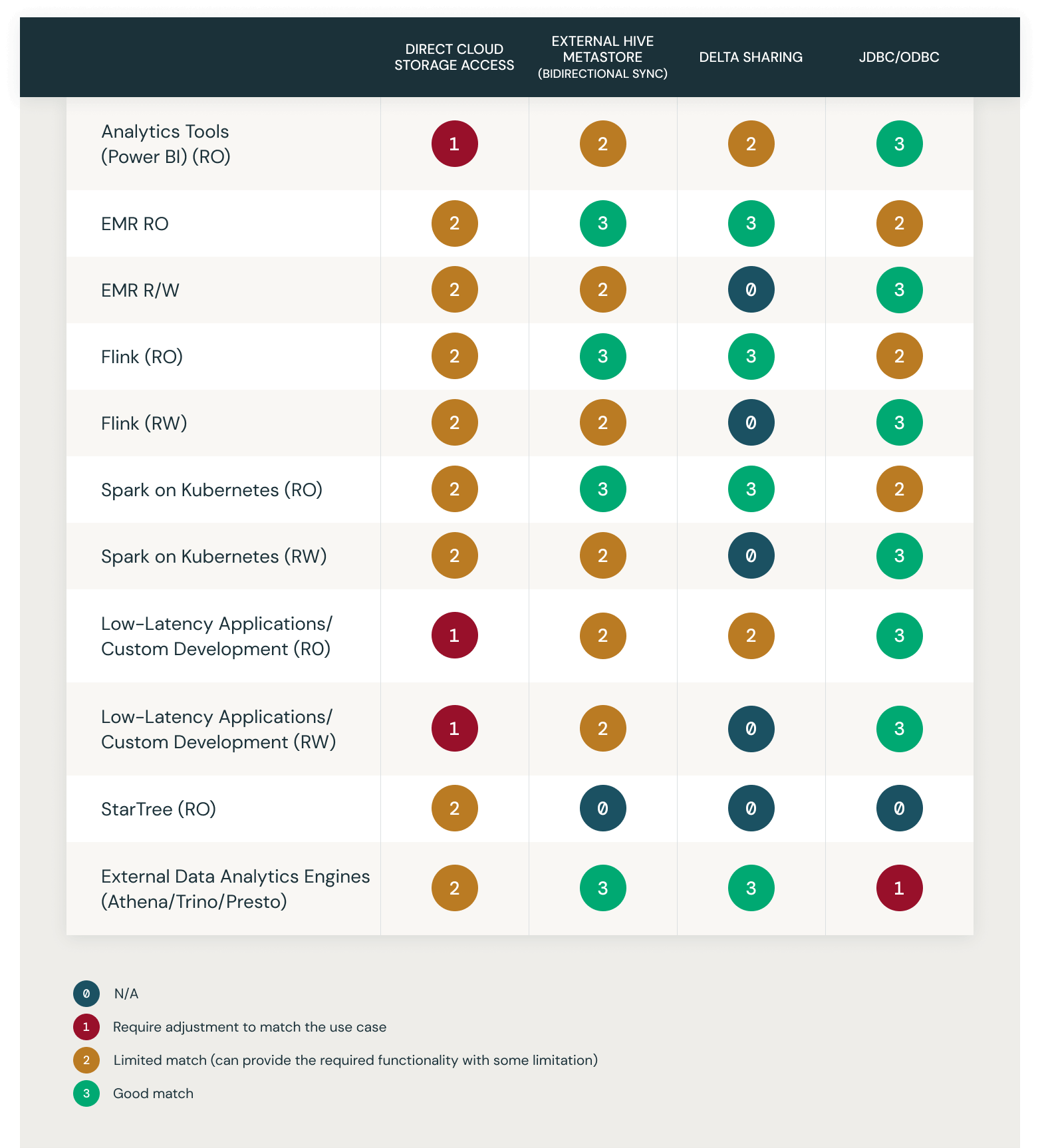
Integration options and use-cases matrix
This chart demonstrates the match of the above described solution alternatives with a select list of common use cases. They are rated 0-4:
- 0 - N/A
- 1 - Require Adjustment to Match the use case
- 2 - Limited Match (can provide the required functionality with some limitation)
- 3 - Good Match
Review Documentation
https://docs.databricks.com/integrations/jdbc-odbc-bi.html
https://www.databricks.com/product/delta-sharing
https://docs.databricks.com/sql/language-manual/sql-ref-syntax-aux-sync.html
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.