Lakehouse as a Common Language Across The Enterprise!
by Digan Parikh
What is the Lakehouse?
Recently, there has been a lot of buzz around the term lakehouse. Is it a database? A data warehouse? A data lake? In short, a data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the performance and reliability of data warehouses, enabling business intelligence (BI) and machine learning (ML) using a unified governance and security model. One primary goal of the lakehouse platform is to empower enterprises to make better decisions.
One of the main challenges enterprises face is finding a common language for decision making. In the past, enterprises created their own 'stack' to make decisions. These stacks were often siloed, architecturally complex and disconnected from data teams – Data Analysts, Data Engineers and Data Scientists. On top of that, each language has limited insights it can derive out of that stack – whether that's predictive, historical, or current in nature.
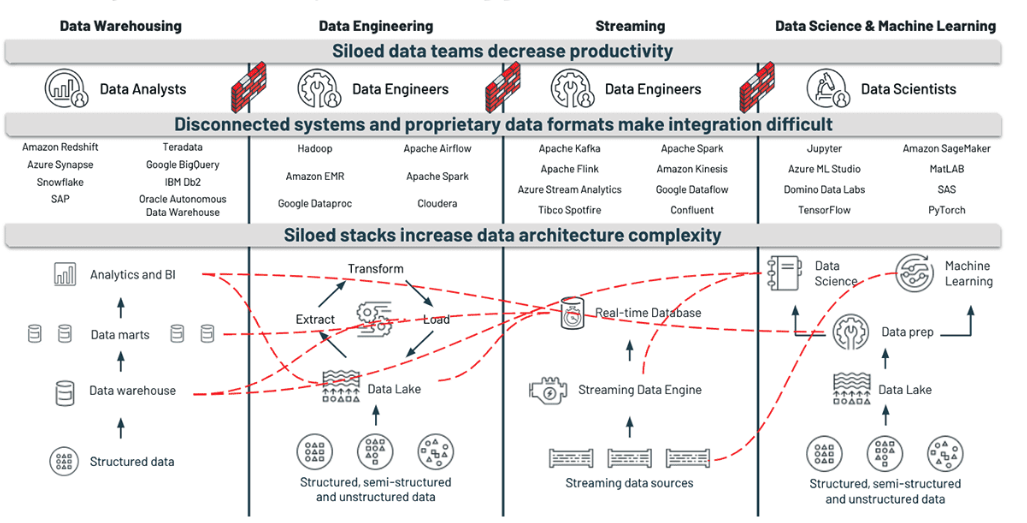
As a consequence of this limitation, users have a lack of trust in their data assets: tables, views, reports, dashboards, KPIs. They do not know what a particular field or term represents because there's little metadata or lineage associated with it. For example, the column "date" can have a different meaning depending on the dataset or the user. This breaks down the ability to derive insights and make sound decisions. After all, a data asset's value is derived from its ability to be understood and trusted across the enterprise.
The following chart breaks down traditional teams and their languages of choice, showcasing how convoluted a disparate approach can quickly become, especially at scale.
| Team | Language (s) | Use Case | Question Answered |
|---|---|---|---|
| Data Analytics | SQL | Data Analytics and BI | What has happened? |
| Data Engineering | SQL, Python, Scala | ETL, Scalable data transformations | What has happened? |
| Streaming | Python, Java, Scala | Real time | What is happening in the near real-time? |
| Data Science | Python, SQL, R | Predictive Analytics and AI/ML | What will happen? How do we respond? Automatically make the best decision? |
Adding to the complexity, end users are limited in their languages, as different data platforms are limited to specific languages. For example, data warehouses are bounded to SQL, and data science platforms are bounded to Python and R.
A common language across the enterprise
Finding a common language in an enterprise setting is often difficult because you need to allow many users with different data backgrounds and skills to collaborate on one single platform. So what does a common language look like?
Here are some critical characteristics:
- Freedom of choice: Each data team member, regardless of background, should have the freedom and ability to select the best language to solve for their use case. Whether it is a predictive use case with unstructured data or a BI use case on structured data, the user should have the flexibility to decide which language to use on the same platform that helps them answer important business questions.
- Simple: Each data team member should be able to focus on the use case and make an impact without having to worry about any operational overhead. The access to the data, permissions and requests should be quick and frictionless for the users. Permissions and security should just be defined once and applied across the data assets.
- Collaborative: Each data team member should be able to collaborate with other data personas on use cases without worrying about access to data, code, or infrastructure. All analyses should be reproducible and easily understood across the user base with the autonomy to control their own destiny.
- Data Quality: Each data team member should always have access to the freshest and most reliable data. This makes sure that the insights derived from the end products are always accurate and trusted.
How does Databrick's Lakehouse Platform enable enterprises to achieve a common language?
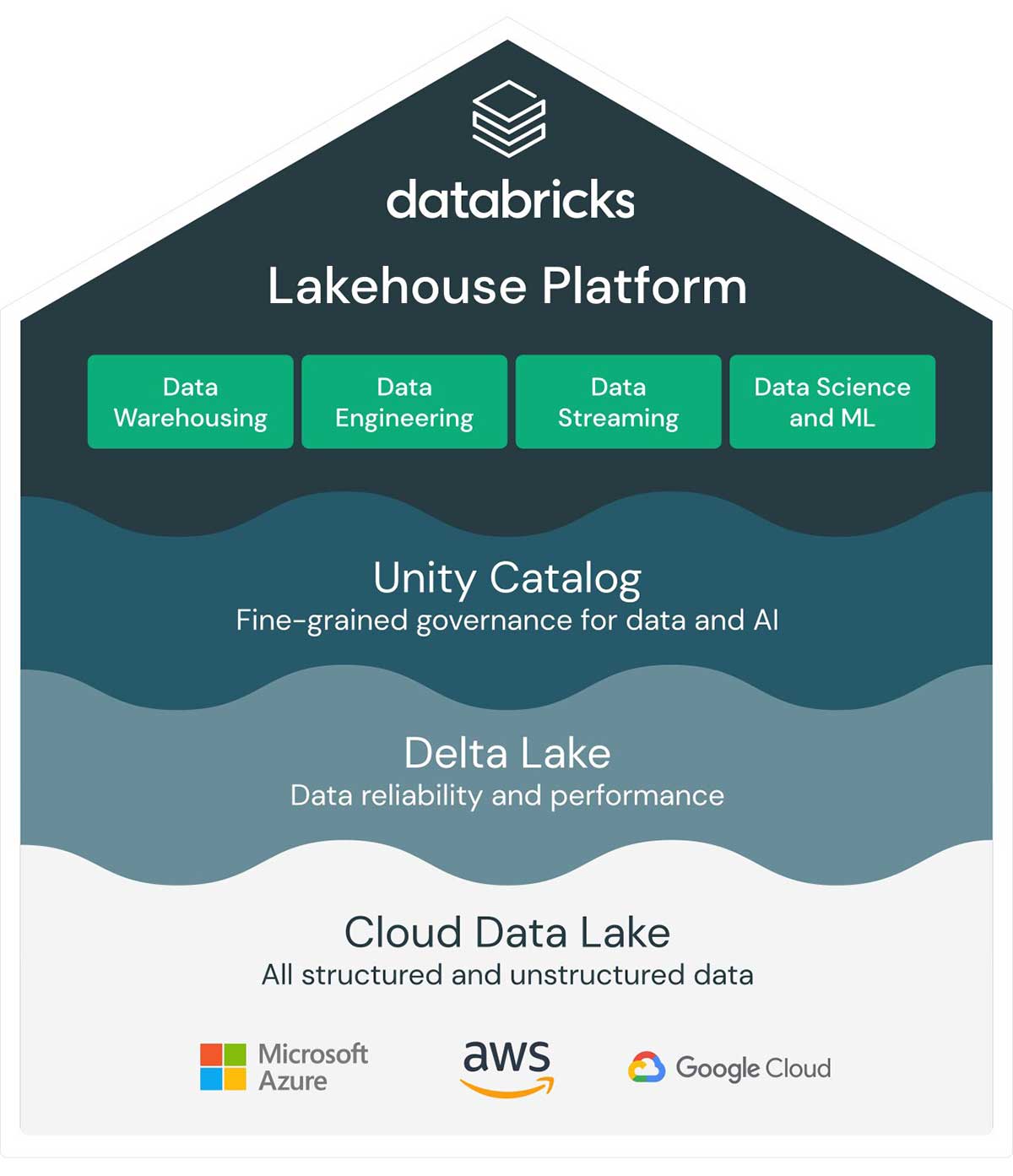
The Databricks Lakehouse Platform is built on open source and open standards, which means you have freedom on how you evolve your data strategy. There are no walled gardens or restrictions to current and future choices allowing diverse personas in data, analytics, and AI/ML to work in a single location. With a consistent experience across all clouds, there is no need to duplicate efforts for security, data management, or operational models.
Establishing a common language with a lakehouse starts with three core components:
- Multi-cloud: With a lakehouse, store all your data (structured, semi-structured, unstructured) in cheap, commodity storage in any of the major cloud platforms: Microsoft Azure, AWS or GCP. This directly addresses the challenge of more traditional data platforms that forced vendor lock-in. The multi-cloud approach of a lakehouse means that data teams have more agility and flexibility due to the freedom of choice of cloud providers. Multi-cloud ensures as your business transforms, your data platform will always adapt to your business without any platform limitations at scale.
- Data reliability: Enterprises need a performance and reliability layer. Databricks provides Delta Lake, which introduces concepts such as ACID transactions, time travel, schema enforcements and batch and streaming unification, and more. Delta Lake allows you to configure your data lake based on your workload patterns. Quality data stored in the lakehouse platform allows users to write reusable pipelines in SQL or Python and create ML models without moving their data or running into inaccuracy issues. This reduces data architecture complexity and increases productivity, as users don't have to worry about disconnected systems or proprietary data formats.
- Eased Governance: You need a single governance layer that enforces rules. With the help of Unity Catalog, Databricks provides a simple, fine grained data access control that manages rules, permissions, data search and lineage on data assets across the environments. Users can finally trust their data sources and follow the datasets upstream to find any discrepancies and make sound decisions in a collaborative manner. Set once and deploy!
With the above paradigm shift, the enterprise now has a solid foundation built. This allows any users to solve their use cases and foster a culture of analytics and collaboration in their line of business. Different departments can continue to solve their toughest problems with a unified framework and ultimately a common language.
Now, this concept may sound novel, but this is exactly what happens when the lakehouse platform is built. It is a paradigm shift that fuels cultural change along with speed and sophistication. We have free trials and solution accelerators across industries to help your enterprise begin the journey on the road to a stronger data culture using a common language across your organization.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.