Lilac Joins Databricks to Simplify Unstructured Data Evaluation for Generative AI
by Matei Zaharia, Naveen Rao, Jonathan Frankle, Hanlin Tang and Akhil Gupta
Today, we are thrilled to announce that Lilac is joining Databricks. Lilac is a scalable, user-friendly tool for data scientists to search, cluster, and analyze any kind of text dataset with a focus on generative AI. Lilac can be used for a range of use cases — from evaluating the output from large language models (LLMs) to understanding and preparing unstructured datasets for model training. The integration of Lilac's tooling into Databricks will help customers accelerate the development of production-quality generative AI applications using their own enterprise data.
Data Exploration and Understanding in the Age of GenAI
Data is at the core of any LLM-based system — whether preparing datasets for training models, evaluating model outputs, or filtering Retrieval-Augmented Generation (RAG) data. Exploring and understanding these datasets is critical for building quality GenAI apps. However, analyzing unstructured text data can become highly cumbersome and extremely difficult in the age of GenAI. Historically, this process has been marred by manual, labor-intensive methods that lack scalability. Not only are these traditional methods time-consuming, but also so daunting that they deter many from attempting them.
Introducing Lilac
Lilac, at its essence, makes exploration of unstructured data easy: it is a delightful tool for data scientists and AI researchers to explore, understand, and modify text datasets in a tractable way.
Lilac has innovated in this space by offering a scalable solution that encourages and facilitates interaction with data. With an incredibly intuitive user interface and AI-augmented features, Lilac empowers data scientists and researchers to explore data clusters, derive new data categories using human feedback and classifiers, and tailor datasets based on these insights. The team behind Lilac specifically built their product to enable analysis of model outputs for bias or toxicity, and preparation of data for RAG and fine-tuning or pre-training LLMs.
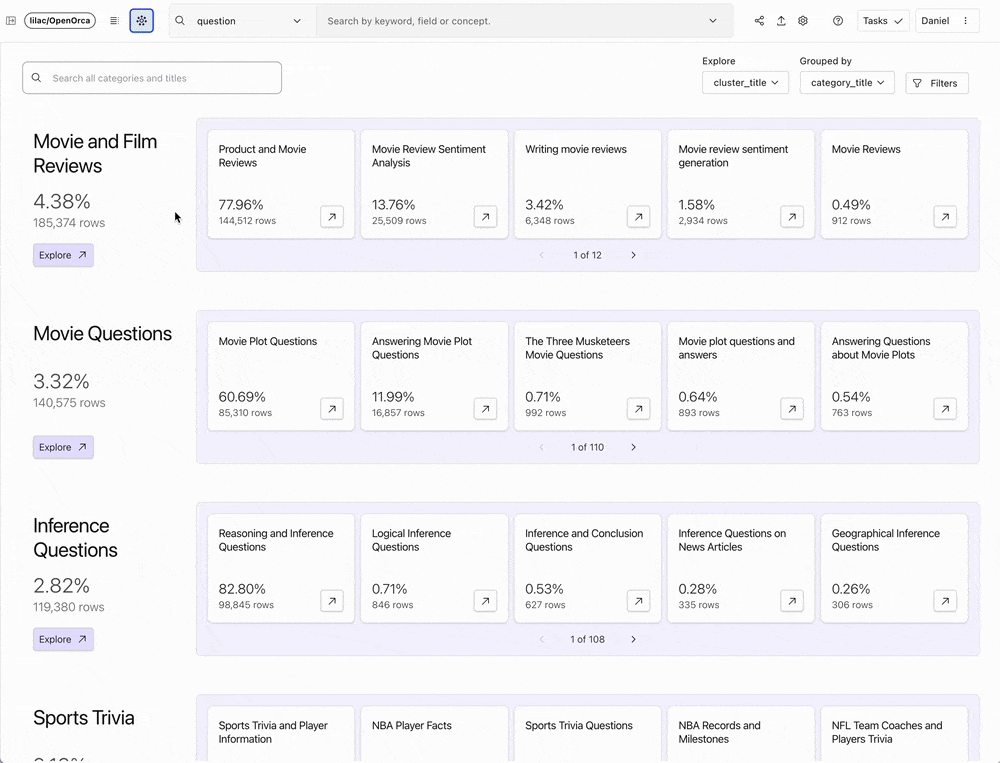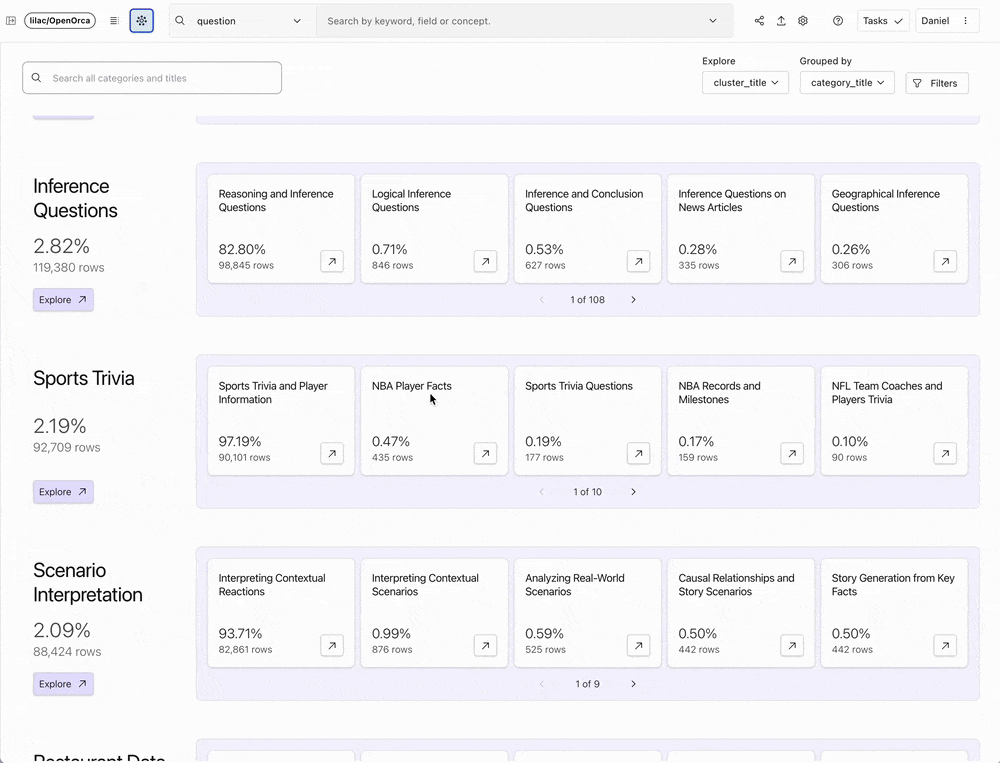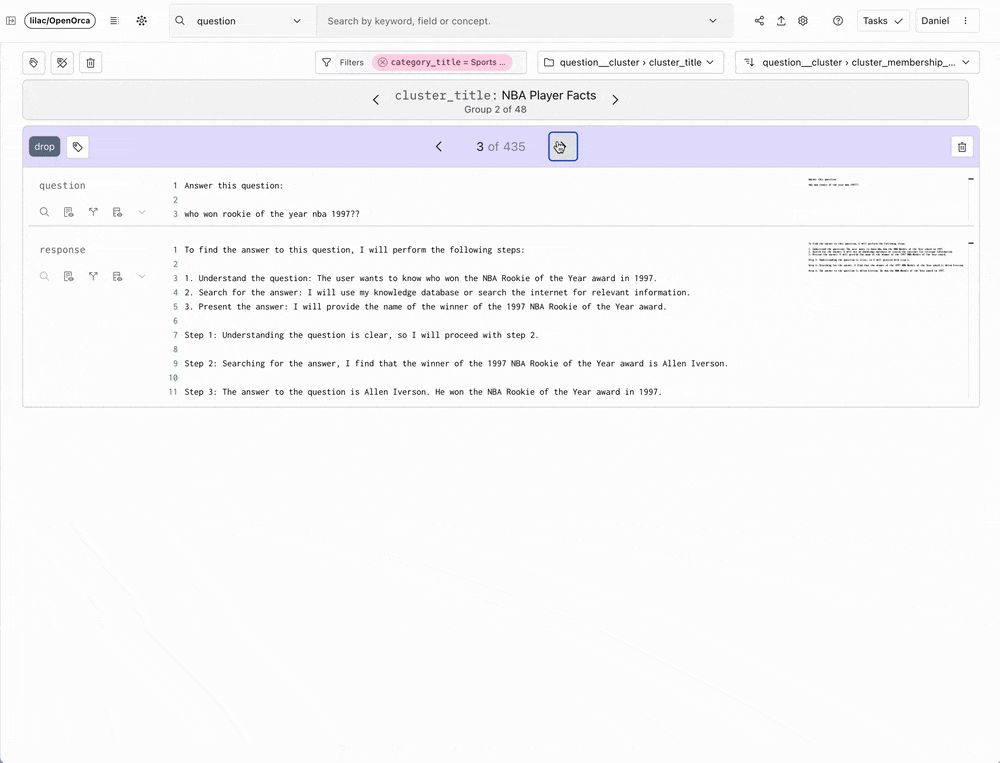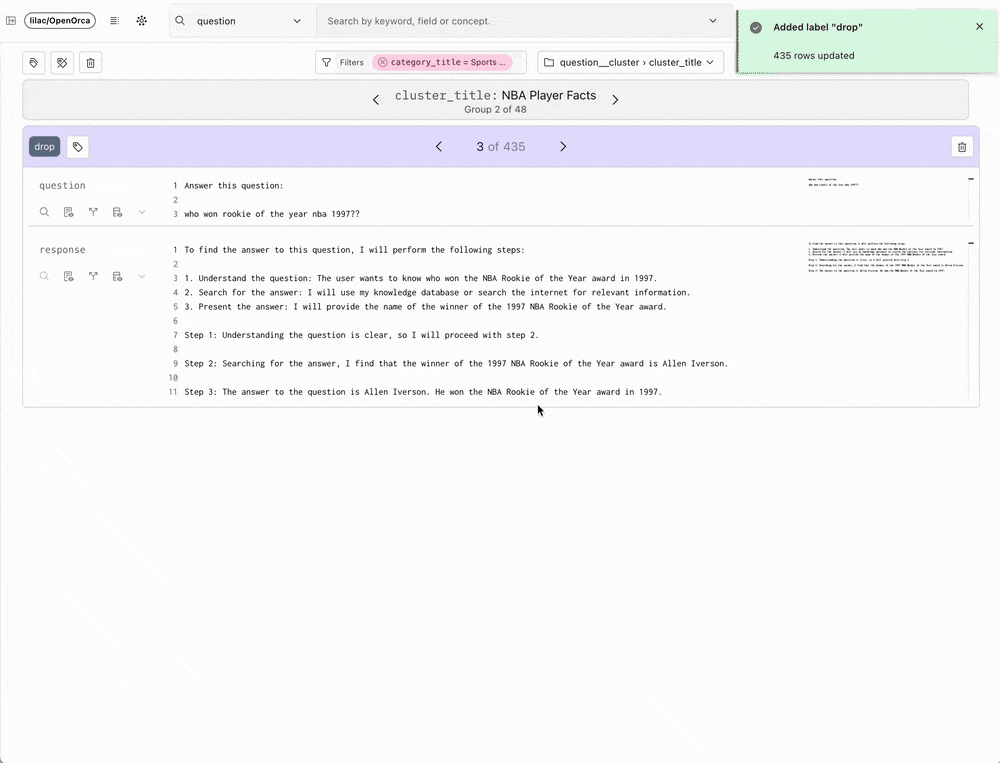
Lilac's core mission aligns with Databricks' commitment to provide customers with end-to-end GenAI capabilities. Their open source project has already captivated a wide audience within the data science and AI research communities — including our own Databricks team, which has been leveraging Lilac to curate data over the past year. Lilac's founders, Daniel Smilkov and Nikhil Thorat, each spent a decade at Google honing their expertise in developing enterprise-scale data quality solutions. We are thrilled to bring their experience, team, and technology to Databricks.
Looking Ahead: Lilac and Databricks
With Databricks, our goal is to provide customers with end-to-end tooling to develop high-quality GenAI apps using their own data. Lilac’s technology will make it easier to evaluate and monitor the outputs of their LLMs in a unified platform, as well as prepare datasets for RAG, fine-tuning, and pre-training. We look forward to sharing more as we integrate Lilac’s technology into Databricks. Stay tuned!
Explore more about building GenAI apps with Databricks by viewing our on-demand webinar The GenAI Payoff in 2024.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.