Blazingly Fast LLM Evaluation for In-Context Learning
With MosaicML you can now evaluate LLMs on in-context learning tasks (LAMBADA, HellaSwag, PIQA, and more) hundreds of times faster than other evaluation harnesses. For 70B parameter models, LAMBADA takes only 100 seconds to evaluate on 64 A100 GPUs, and evaluation of a 1.2 trillion parameter model takes less than 12 minutes when using 256 NVIDIA A100 GPUs.
When training large language models (LLM), a common way to evaluate their performance is to use in-context learning (ICL) tasks. These tasks require LLMs to complete sentences or answer questions posed in natural language without updating the model's weights. The model must infer what the task is, figure out how the task works, and determine how to apply it to a new example, all by using contextual clues in the prompt — without ever having been trained to perform that specific task. For example, a model might be asked to translate from English to Spanish in the following manner, and be expected to predict the next word, "perro".
What makes ICL evaluation tricky for LLMs is that it requires a diverse range of evaluation techniques that are distinct from the simple loss functions typically used for evaluation. For example, while traditional ML metrics like cross-entropy can be executed using a single PyTorch library function call, ICL metrics such as LAMBADA accuracy rely on a more complex series of steps, including selecting the subset of output logit indices corresponding to the continuation and verifying that the most likely logit matches the correct token at all the indices.
Other ICL metrics such as multiple choice accuracy (as used by PIQA, HellaSwag, etc.) require an even more complex series of steps: calculating model outputs on all question + answer choice pairs, calculating perplexity on the subset of the output indices corresponding to the answers, then grouping by questions and determining how often the lowest perplexity answer corresponds to the correct choice.
For this blog post, our baseline ICL evaluation method is the EleutherAI/lm-evaluation-harness, an industry-standard ICL evaluation codebase that supports a diverse array of ICL tasks. While this codebase is easy-to-use, convenient, and supports a huge variety of ICL tasks, its single code path for all tasks leaves room for efficiency gains and it has no default support for either multi-GPU data parallelism or FSDP model sharding.
With our latest Composer release (0.12.1), we've improved the efficiency of language modeling (e.g. LAMBADA) and question-answering (e.g. PIQA) ICL tasks, yielding a 7.45x speedup on a single A100 GPU. We also use Composer's native multi-GPU inference support and FSDP model sharding to linearly scale run time with GPU count and support model sizes over 1.2T parameters, giving you the power to rapidly evaluate even the largest models.
To explain how we delivered these massive speedups, we dig into 3 key features:
- First, we show how multi-GPU inference speeds up evaluation linearly with device count, reducing eval time from hours to seconds.
- Second, we show how Composer can log live ICL eval metrics during a training run.
- Finally, we will show how Composer's FSDP integration allows us to evaluate massive models (over 1.2T parameters on 256 GPUs!) without sacrificing usability.
Rapid Multi-GPU Eval with Composer
Our Composer-based ICL evaluation code works with multi-GPU acceleration and FSDP (data parallelism + parameter sharding) out of the box. With data parallelism, if you double the number of GPUs, you cut the run time for your evaluation in half. And with parameter sharding, you can evaluate models that are too large to fit on a single machine.
To measure the performance of our implementation, we evaluated GPT-Neo 125M, 1.3B, and 2.7B on two commonly used ICL benchmarks: LAMBADA and PIQA. The LAMBADA language modeling task requires a model to predict the last word of a multi-sentence passage drawn from a dataset of books independently published on the Internet. We evaluated on the 5,153 examples in the LAMBADA test set.
The PIQA dataset is a multiple-choice test probing a model's intuitions about physical situations. It consists of 1,838 multiple-choice questions describing a physical goal as well as two potential solutions, only one of which is correct. There are multiple techniques for probing a language model's ability to answer multiple-choice questions. The method we adopt is to run each question + answer pair through the model and determine which answer the model gave a higher average per-word perplexity.
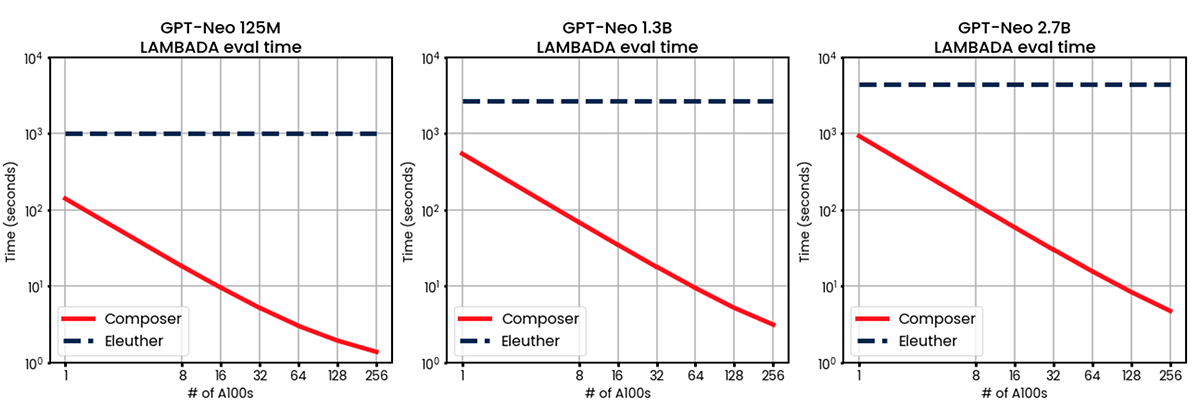
We measured the run time of our Composer-based ICL eval on pre-trained GPT-Neo 125M, 1.3B and 2.7B parameter models downloaded from HuggingFace on 1, 8, 16, 32, 64, 128, and 256 A100-40GB GPUs. We used the EleutherAI/lm-evaluation-harness as a baseline.
As you can see in figure 2, for both the LAMBADA and PIQA tasks our results show near-perfect linear scaling. When we double the number of GPUs, the run time is cut in half. Though we didn't measure above 256 GPUs, we expect the near-perfect linear scaling to continue.
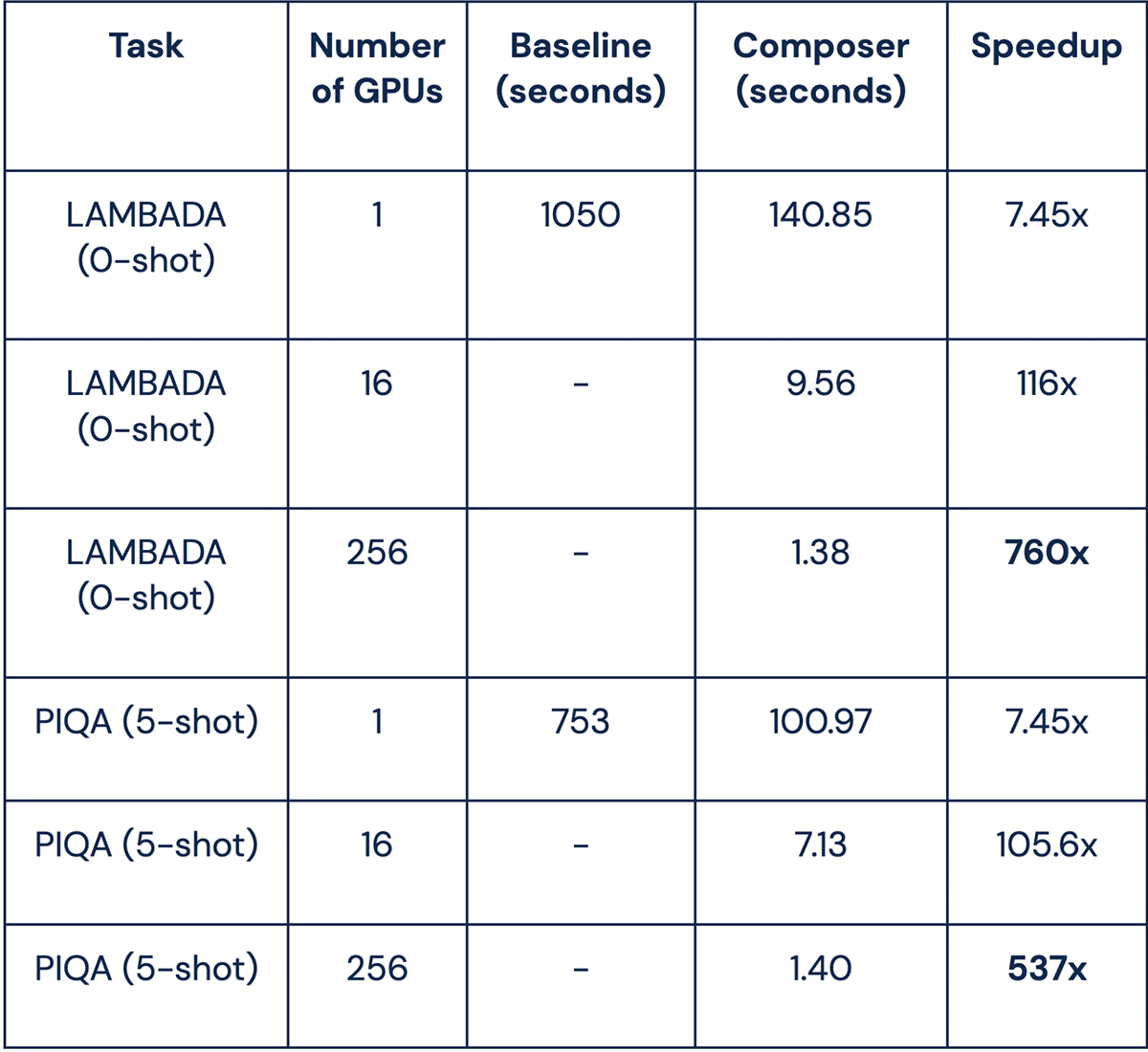
In the table below, you can see that for GPT-Neo 125M, we reduced the time to evaluate LAMBADA from a baseline of roughly 16 minutes down to 1.38 seconds on 256 GPUs—a 760x speedup! Part of this speedup is from multiple GPUs, and part of it is from our faster ICL implementation: our setup shows a 7.45x speedup for LAMBADA and PIQA on 1 GPU, thanks to replacing Python list operations with PyTorch tensor operations and keeping all tensors on GPU during evaluation.
Measuring ICL Live During Training
Today's generation of large language models are typically trained on hundreds of GPUs for days to weeks at a time. Of course, it would be nice to see some intermediate evaluation results during training. But performance matters: without multi-GPU support for evaluation, a single GPU would be doing all the work while the remaining GPUs sit idle for minutes or hours on end. If you're running evaluation on a single GPU, you could be waiting up to 16 minutes per evaluation for even the smallest 125M parameter models, which would blow up to >100 hours for a 70B parameter model.
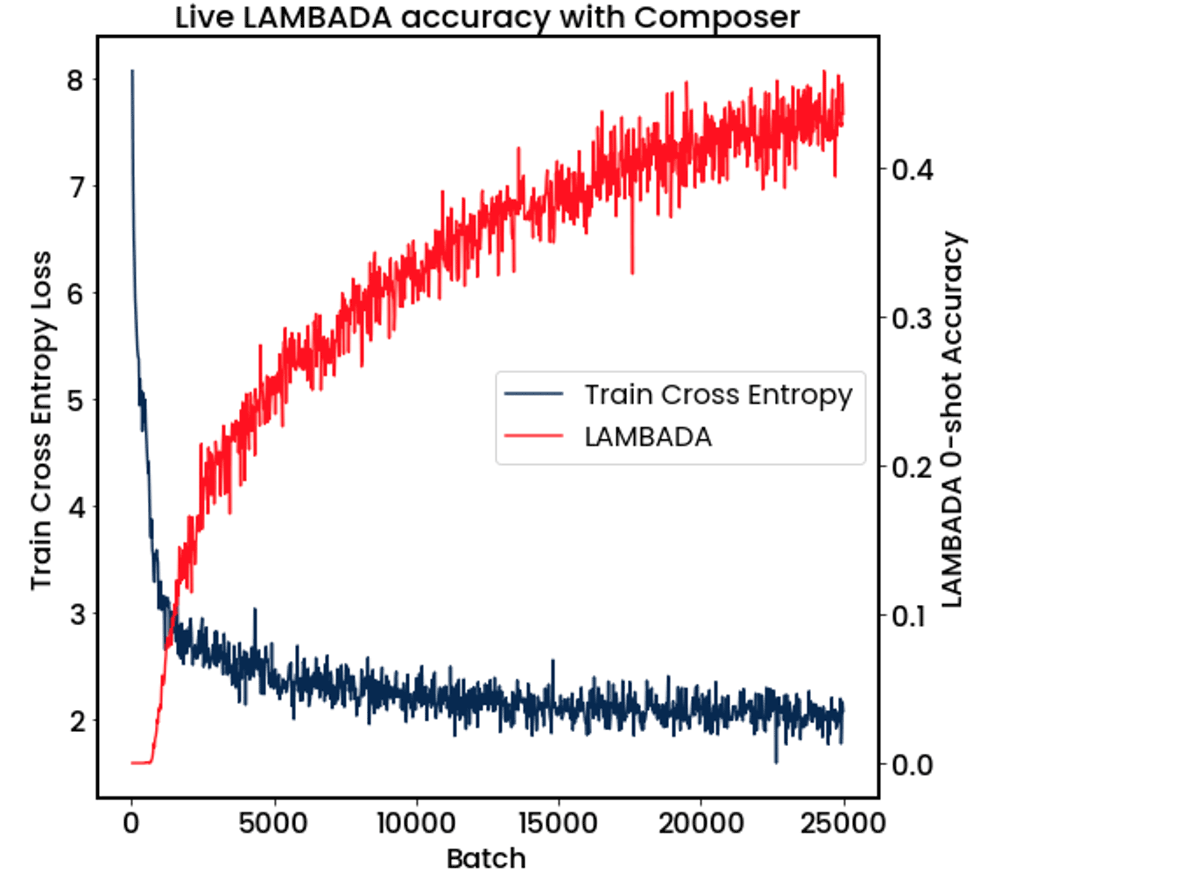
Using our Composer ICL evaluator, it's now possible to run ICL evaluation during multi-GPU training runs and parallelize across all GPUs. As shown in Figure X, we were able to train a GPT-1B parameter model on 8 GPUs and evaluate the model's LAMBADA score every 25 batches with minimal overhead. Composer allows you to watch how this key metric evolves over time in experiment trackers like Weights and Biases, CometML, or Tensorboard.
Evaluating Huge Models
As we've covered above, it's now feasible to evaluate live ICL metrics during multi-GPU training runs and greatly reduce the overall evaluation time when running on large clusters. At small model scales, this parallelization is a convenience, but at large model scales it is a necessity. For models that are too large to fit on a single device, we use Composer's integration for FSDP model sharding. With FSDP, the model weights are sharded across all devices and gathered layer-by-layer as needed. This enables us to evaluate massive models like LLMs, limited only by the total memory of the cluster, rather than the memory of each device.
On 64 GPUs, we found that evaluation time perfectly scales with model size from under 2 minutes at 70B parameters to 12 minutes with 450B parameters. To put it all in perspective: with 64 GPUs we can evaluate a 450B model faster than the non-parallelized baseline harness can evaluate a 125M parameter model.
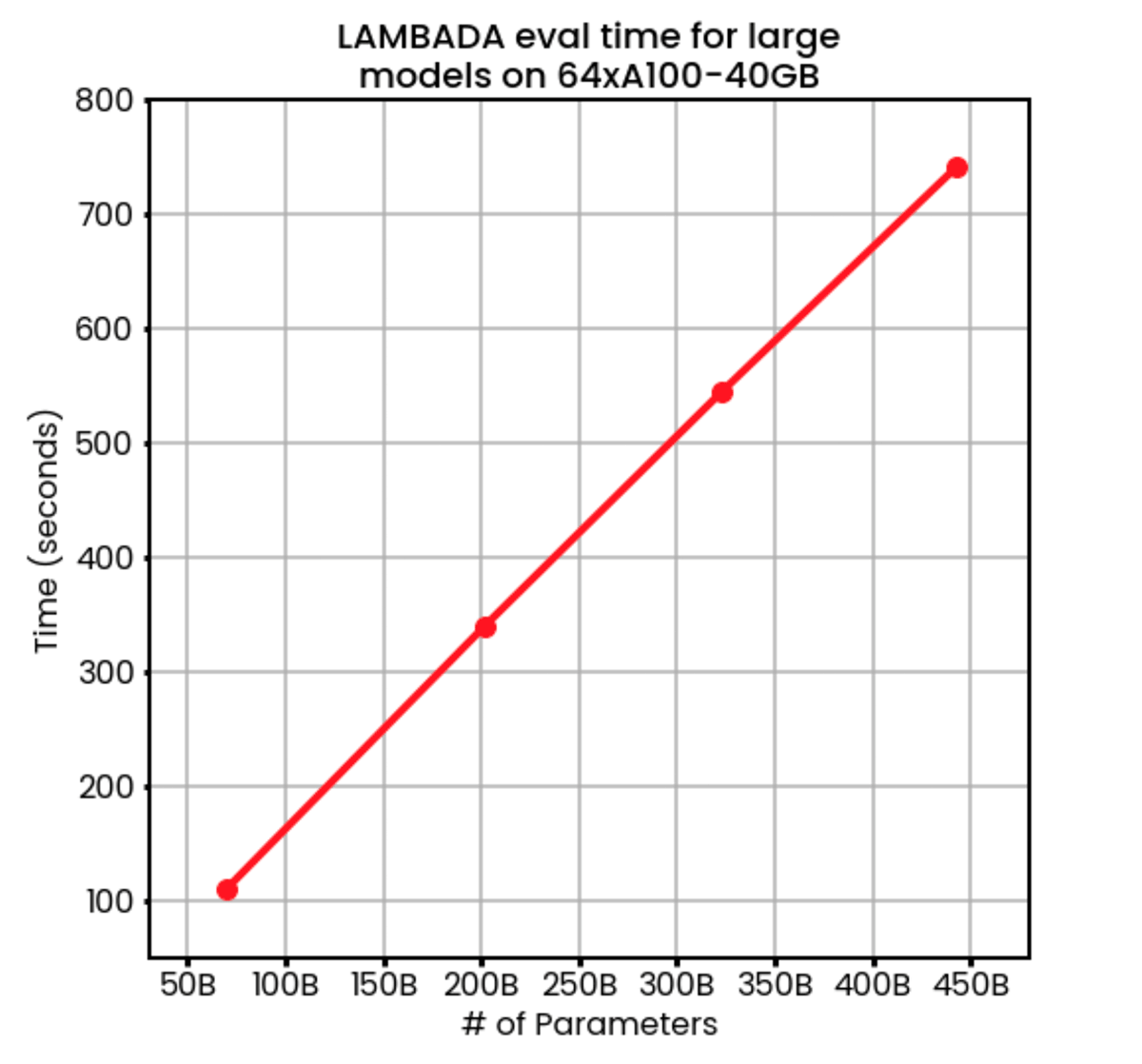
But we didn't stop there: finally, we decided to push the limits on our 256-GPU research cluster. With FSDP + Composer ICL eval, we were able to evaluate LAMBADA on a 1.2T parameter model in only 12 minutes!
What's Next
Our Composer ICL evaluation framework is now available in Composer v.0.12.1. Our code is set up to accept any user-provided ICL dataset in either a language modeling format or a multiple-choice test format, and we welcome community feedback (join our Slack!) on what features to implement next.
Ready to get started? Download our latest Composer library, or request a demo of our MosaicML platform. And keep up with the latest news by following us on Twitter and subscribing to our newsletter.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.