Announcing MPT-7B-8K: 8K Context Length for Document Understanding
by Sam Havens and Erica Ji Yuen
Today, we are releasing MPT-7B-8K, a 7B parameter open-source LLM with 8k context length trained with the MosaicML platform. MPT-7B-8K was pretrained starting from the MPT-7B checkpoint in 3 days on 256 NVIDIA H100s with an additional 500B tokens of data.
We are pleased to announce an addition to our MPT Foundation Series with the release of MPT-7B-8k. With its 8k context length, MPT-7B-8K specializes in document summarization and question-answering. Like all the other models in the MPT Foundation Series, MPT-7B-8k is optimized for faster training and inference, and can be finetuned on domain-specific data on the MosaicML platform.
Today, we are releasing 3 models:
- MPT-7B-8k: A decoder-style transformer pretrained starting from MPT-7B, but updating the sequence length to 8k and training for an additional 500B tokens, resulting in a total of 1.5T tokens of text and code. License: CC-BY-SA-3.0
- MPT-7B-8k-Instruct: a model for long-form instruction following (especially summarization and question-answering). Built by finetuning MPT-7B-8k on several carefully curated datasets. License: CC-BY-SA-3.0
- MPT-7B-8k-Chat: a chatbot-like model for dialogue generation. Built by finetuning MPT-7B-8k on approximately 1.5B tokens of chat data. License: CC-By-NC-SA-4.0
Whether you're looking to streamline workflows, improve the understanding of complex documents, or simply save time and effort, MPT-7B-8k on the MosaicML platform is a great starting point for businesses looking to add reasoning capabilities to their language data.
How does MPT-7B-8k compare to other models?
MPT-7B-8k is:
- Licensed for the possibility of commercial use.
- Trained on a large amount of data (1.5T tokens like XGen vs. 1T for LLaMA, 1T for MPT-7B, 300B for Pythia, 300B for OpenLLaMA, and 800B for StableLM).
- Prepared to handle long inputs thanks to ALiBi. With ALiBi, the model can extrapolate beyond the 8k training sequence length to up to 10k, and with a few million tokens it can be finetuned to extrapolate much further.
- Capable of fast training and inference via FlashAttention and FasterTransformer
- Equipped with highly efficient open-source training code via the llm-foundry repository
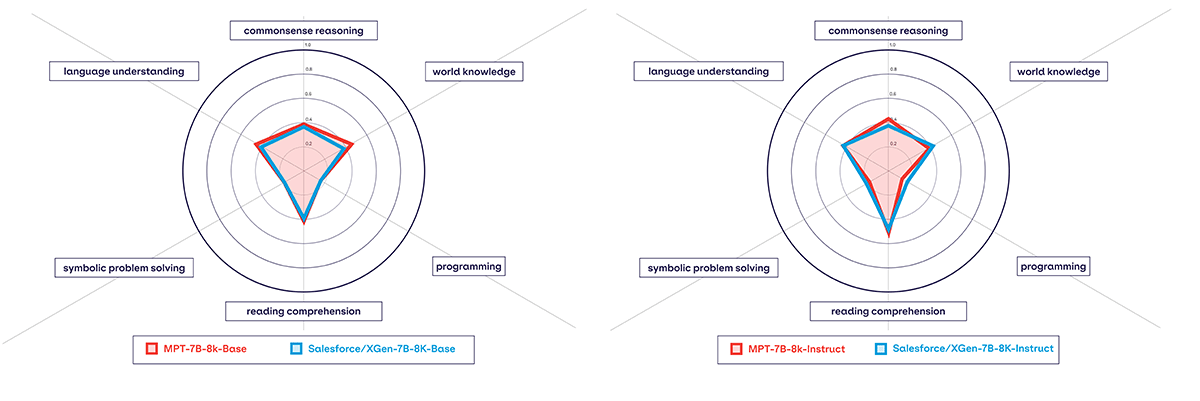
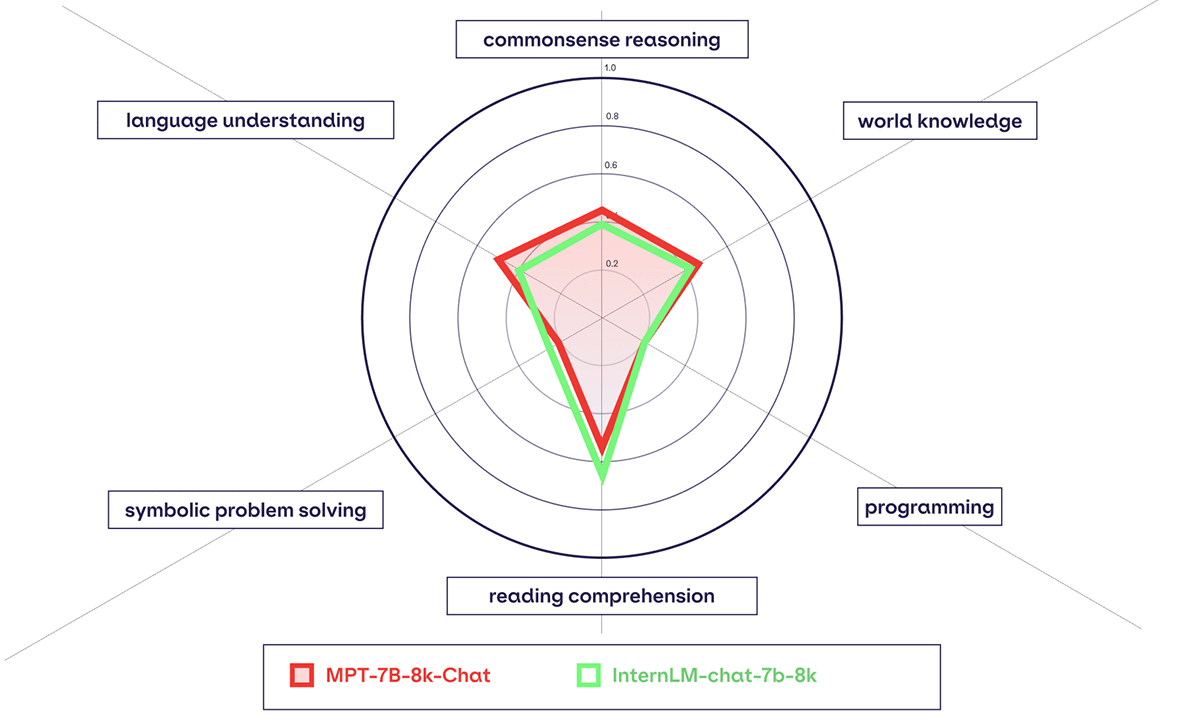
In addition, MPT-7B-8k models perform similarly or better than other open source 8K context length models on our in-context learning evaluation harness. To learn more about our in-context learning evaluation harness and to see full results comparing different open-source LLMs - check out our new LLM evaluation page.
If you prefer seeing qualitative results - feel free to download the model and share your results in our Community Slack, or check out a long-context length reading comprehension example at the bottom of the blog.
What's next?
Want to get started with deploying LLMs trained and customized on your data? The MosaicML platform gives you the tools and infrastructure to easily and efficiently build, customize, and deploy the MPT-style models on your secure cloud of choice. If you're interested in training and deploying your own MPT or LLMs on the MosaicML platform, sign up here.
Appendix
MPT-7B-8k-Instruct Example
In the following example we have provided MPT-7B-8K-Instruct with a long passage about rats from the MCAS Grade 10 English Language Arts Reading Comprehension Exam and asked it to give an explanation of something mentioned in the text. The model gives a reasonable answer given the content of the paragraph.

MPT Models Overview
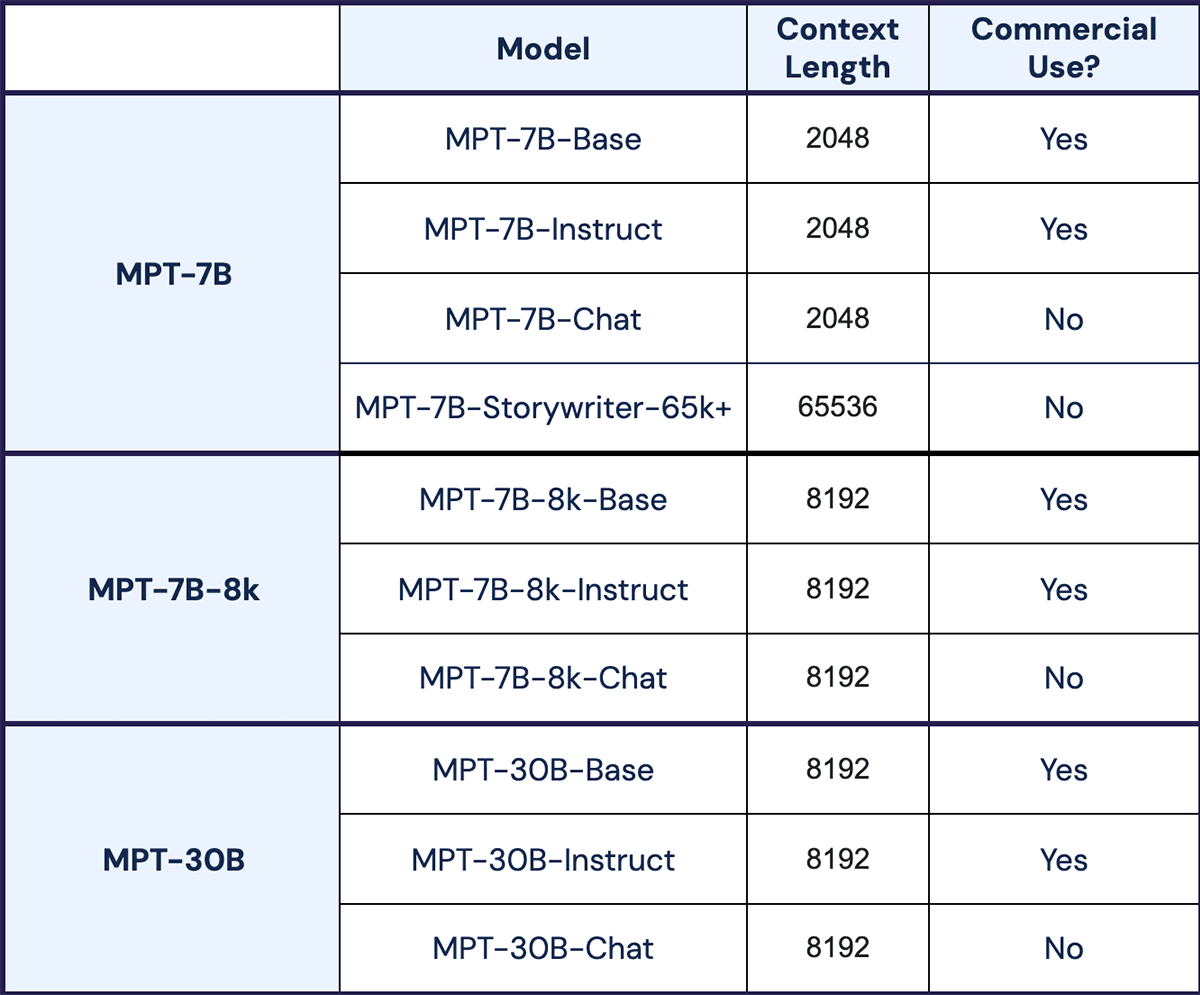
MPT-7B-8k FAQ
When would I choose…
- MPT-7B-8k over MPT-7B? Use 8k in most cases, except when coding or reasoning ability are the only criteria, in which case you should evaluate both models
- MPT-7B-8k-Chat over MPT-7B-Chat? You should always use MPT-7B-8k-Chat.
- MPT-7B-8k-Instruct over MPT-7B-Instruct? 8k-Instruct excels at longform instruction following; use it when you have inputs longer than 2048 tokens or for summarization and question answering.
- MPT-7B-8k-Instruct over MPT-7B-8k-Chat? You should use the Instruct variant when the noncommercial license of Chat is an issue. For long-document question answering and summarization, you should test both models on your use case.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.