M Science turns alternative data into actionable insights
by Ben Tallman and Spenser Marshall

There are thousands of datasets available to institutional investors, each dataset promising to unlock significant insights in investment decisioning. Across the thousands of datasets, and their many potential applications, there are many different schemas, biases, strengths, and shortcomings. Selecting, testing, and productionizing these datasets is a significant undertaking. Ultimately, investors are looking for the insights from the data, not the data itself.
At M Science, our mission is to create actionable insights for investors, based on alternative data. We review the universe of available data, test many of them to determine efficacy, and select the ones that are most predictive of company KPIs. Using this curated selection of alternative data, we deliver data and data-derived products via written research, dashboards, and data feeds.
We started on this mission over two decades ago, as the first research provider to be purely data-driven. In the early 2000s, the alternative data landscape was different: there were few alternative datasets available, and we focused on web harvested data. As the digitization of the world has proceeded, so did our data assets. M Science was the first research firm to use anonymized consumer transaction data, and we have since evolved to incorporate digital purchase, web traffic, technographic, and a variety of other data types into our products.
Improving products by scaling
Timely delivery of our products helps our clients outperform -- if our clients get insights sooner, they can develop their investment theses and execute their trades sooner. Before M Science was cloud-native, we frequently ran into noisy-neighbor problems with our on-prem infrastructure. It was a good problem to have: our data assets were growing more quickly than our infrastructure. But it became obvious that we needed a more flexible and scalable solution.
In our cloud migration, we wanted to focus on creating insights from data, not managing cloud infrastructure. As such, M Science partnered with Databricks early on (in fact, we were one of Databricks first customers!), and at the time, Databricks was primarily a solution for cloud management and Apache Spark™ implementation. We still love Databricks for cloud management and Spark implementation, but we're even more pleased that Databricks' feature set has expanded far beyond the initial functionality.
If you walked into an M Science office six years ago, you may have heard teams bartering for priority to execute queries on our on-prem servers. Today, you would hear teams discussing how to scale down AWS resources via Photonizing a job. This shift has benefitted our clients: our research products are now timelier than they've ever been. Scaling with Databricks has enabled us to improve our products for our clients.
More datasets with less complexity
Having multiple datasets in each research product is incredibly valuable: it allows us to gain conviction in our KPI forecasts, cover new industries, and examine companies from more angles. But, more data generally means more complexity.
We're always looking to take the complexity out for our teams, and allow them to focus on insight generation, which is why we moved toward a lakehouse architecture. By layering in Unity Catalog, we have a single pane of glass for all our data, reducing unnecessary copies and ensuring the right level of fine-grained access controls. This organization enables us to retain our agility, while expanding our breadth of data.
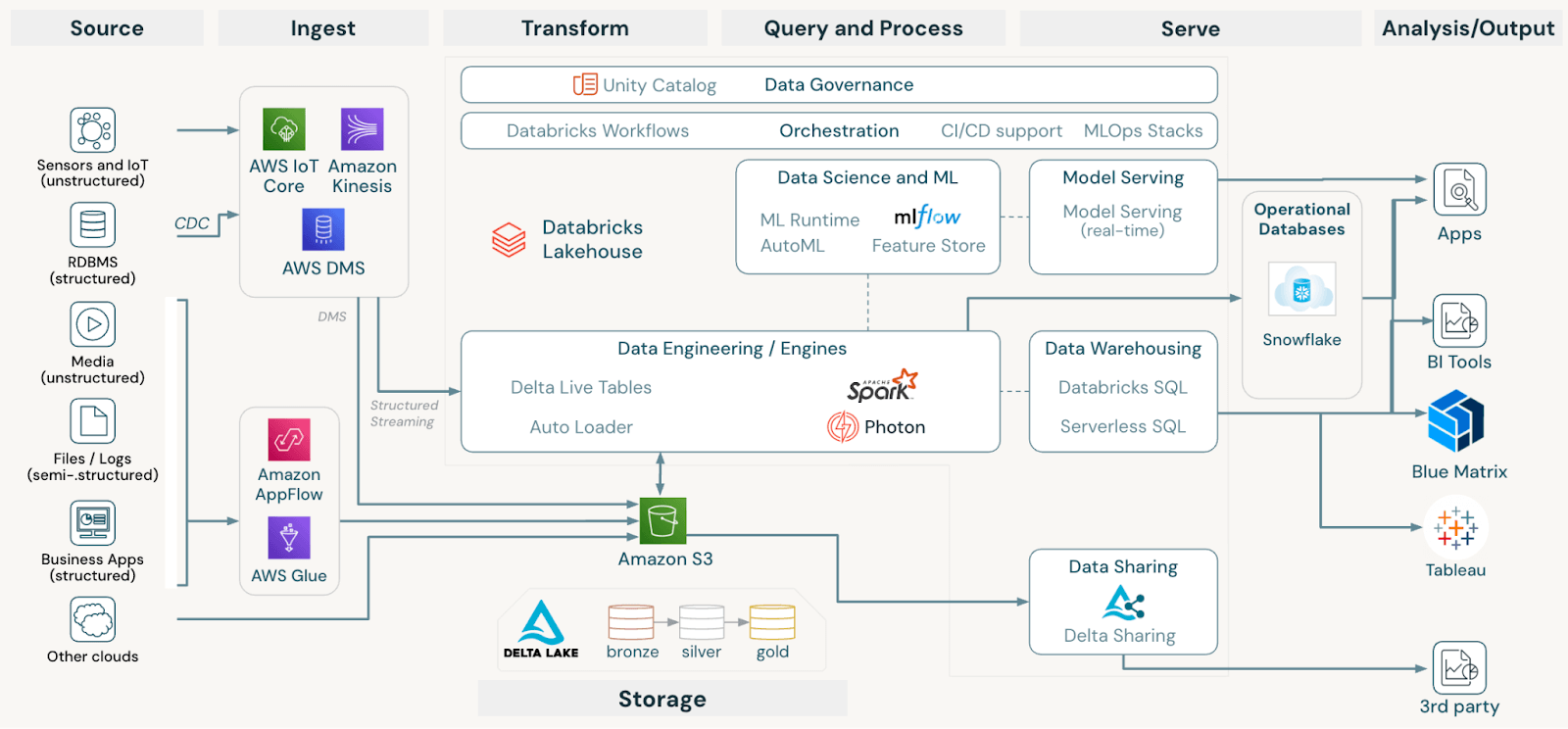
All infrastructure decisions are made with the overriding goal of optimizing our investor client experience, and Unity Catalog helps us organize our vast (and growing) data resources to best service our clients.
Next steps: leveraging Databricks technology to create best-in-class products for our clients
Over the past two decades, we have built a foundation of data, data knowledge, and insights from data, that uniquely position M Science to optimize large language models (LLMs). We are using Databricks infrastructure to deploy our retrieval augmented generation (RAG) design pattern, and we're using Databricks for fine tuning tools. By standing on Databricks' shoulders, we're seeing rapid improvement in the utility of our LLM-based tools.
We're also very excited about using Databricks governance and privacy tools, including clean rooms, to help firms across the Databricks ecosystem to compliantly monetize their data.
Proudly, we stand at the forefront of data innovation, and our journey with Databricks is proof that when great minds collaborate, the possibilities are limitless. Stay tuned for more exciting updates from this powerful partnership.
Join the Databricks Market Data Analytics virtual event and learn how to reduce the barriers to sharing data for data, analytics and AI.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.