What is Machine Learning? How It Works, Types and Use Cases
- Machine learning acts as a bridge between raw data and action, helping organizations turn patterns in data into predictions, automation and more informed decisions.
- Different machine learning methods solve different problems, from predicting outcomes with labeled data to uncovering hidden patterns and improving decisions through feedback.
- It also serves as the foundation for many modern AI systems, supporting everything from forecasting and recommendation engines to computer vision, large language models and generative AI.
Machine learning (ML) is a subset of artificial intelligence (AI) that enables systems to learn from data rather than relying on explicit programming. Instead of simply analyzing information, ML models identify patterns, improve with experience and generate predictions or decisions automatically.
Today, machine learning is used as a bridge between raw data and action—across both deeply technical systems and high-level business strategy. In technical environments, ML is embedded inside systems, infrastructure and products, such as personalization systems, chatbots and personal assistants, image recognition, facial detection, autonomous vehicles, cybersecurity and DevOps. In business contexts, ML supports decision-making, optimization and strategy in marketing, sales, finance and risk, operations, supply chain and human resources.
This guide will cover how machine learning works, the key types of ML and provide real-world examples of machine learning in use.
Machine Learning Definition
Machine learning refers to a class of algorithms that build predictive models by detecting statistical patterns in data.This pattern recognition ability enables machine learning models to make decisions or predictions without explicit, hard-coded instructions. ML models improve performance through exposure to data (model training) rather than explicit rule-based programming.
As a result, ML now powers applications across commercial and enterprise environments, from building large language models (LLMs) for generative AI tools to recommendation and forecasting models and natural language processing.
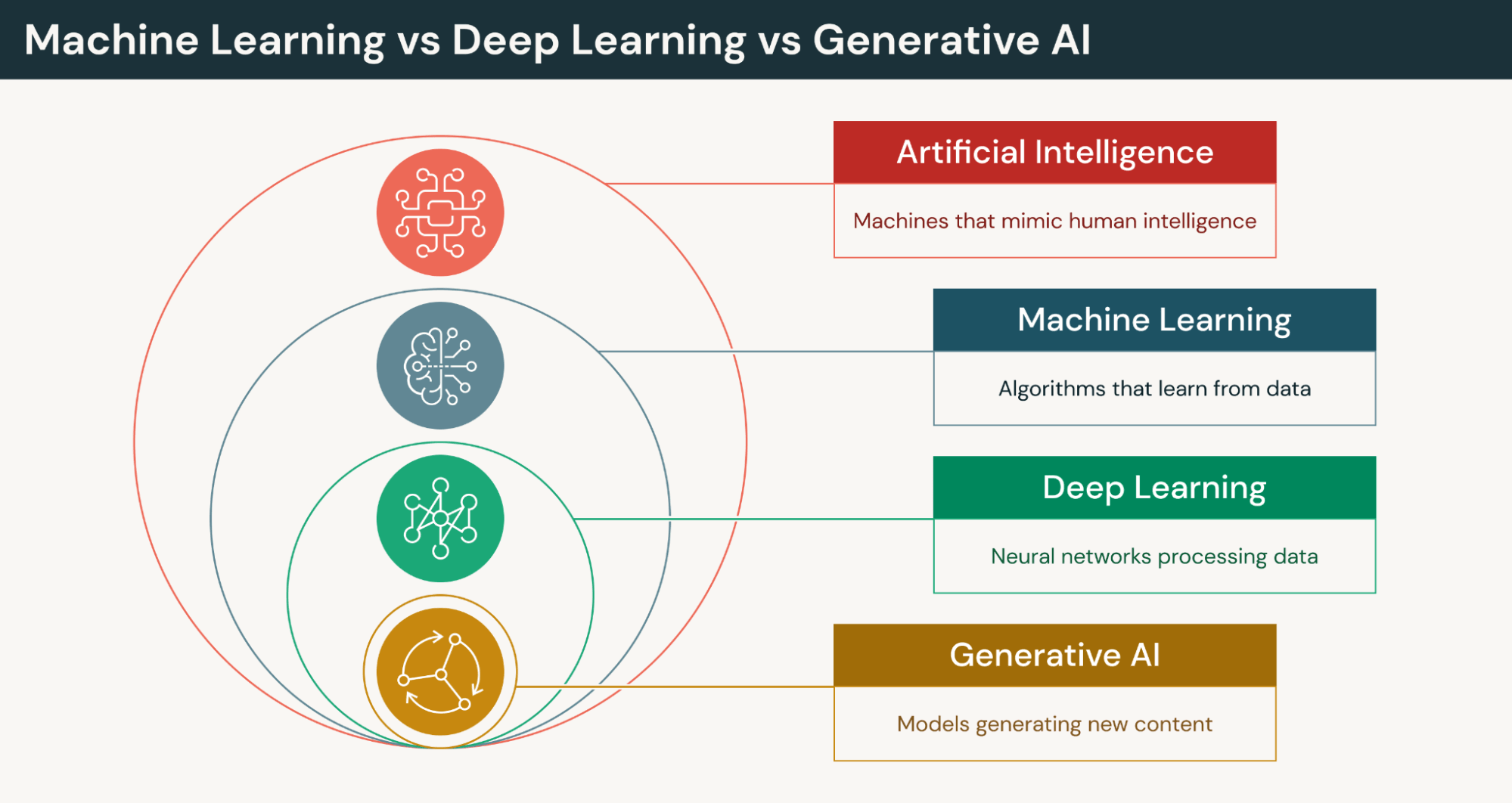
Machine Learning vs Generative AI
Generative AI (GenAI) has become an increasingly visible and widely discussed type of machine learning, especially in workplace and enterprise contexts. Think of machine learning as the umbrella category and GenAI as the subset of ML designed to generate new content in response to user inputs. Generative AI systems are built using machine learning.
Machine learning models are typically focused on prediction accuracy and are built for specific repeatable tasks, such as predicting customer churn, or classification and probability, as with fraud detection and lead conversion scores. GenAI is technically enabled by advanced machine learning techniques to learn patterns and data distributions to generate entirely new outputs that resemble training data. They create new content rather than score or classify.
GenAI relies on core ML principles such as training large datasets, optimization, neural networks, loss minimization and statistical pattern learning.
Machine Learning vs Deep Learning
Machine learning and Deep Learning are often used interchangeably, and they are related but not the same. Machine learning is a broad category of algorithms and data to enable systems to learn and perform tasks with limited or no human intervention. Deep learning (DL) is a specialized type of ML that uses multi-layered neural networks to learn more complex patterns.
The difference between machine learning and deep learning is mainly about scope, model complexity, data requirements and how features are learned. ML models require humans to define features and work with structured data using relatively simple algorithms to predict outcomes, classify data and detect patterns. DL requires large amounts of data and computing power. It learns features automatically from raw data and excels with unstructured data for more complex tasks.
Here’s a side-by-side comparison of ML, DL and generative AI:
| Aspect | Machine Learning (ML) | Deep Learning (DL) | Generative AI (GenAI) |
|---|---|---|---|
| Relationship | Parent category | Subset of ML | Often built using deep learning models |
| Core Capability | Prediction & classification | Complex pattern recognition | Content generation & synthesis |
| Technical Complexity | Moderate data & compute needs | Large datasets & high compute | Massive datasets & very high compute |
| Data Requirement | Works with structured & smaller datasets | Requires large amounts of labeled data | Typically trained on massive datasets (often unlabeled or self-supervised) |
| Explainability | Generally more interpretable | Less interpretable (“black box”) | Often least interpretable at scale |
| Business Use Cases | Fraud detection, churn prediction, forecasting | Facial recognition, voice assistants | Marketing copy generation, design automation, content creation |
How Does Machine Learning Work?
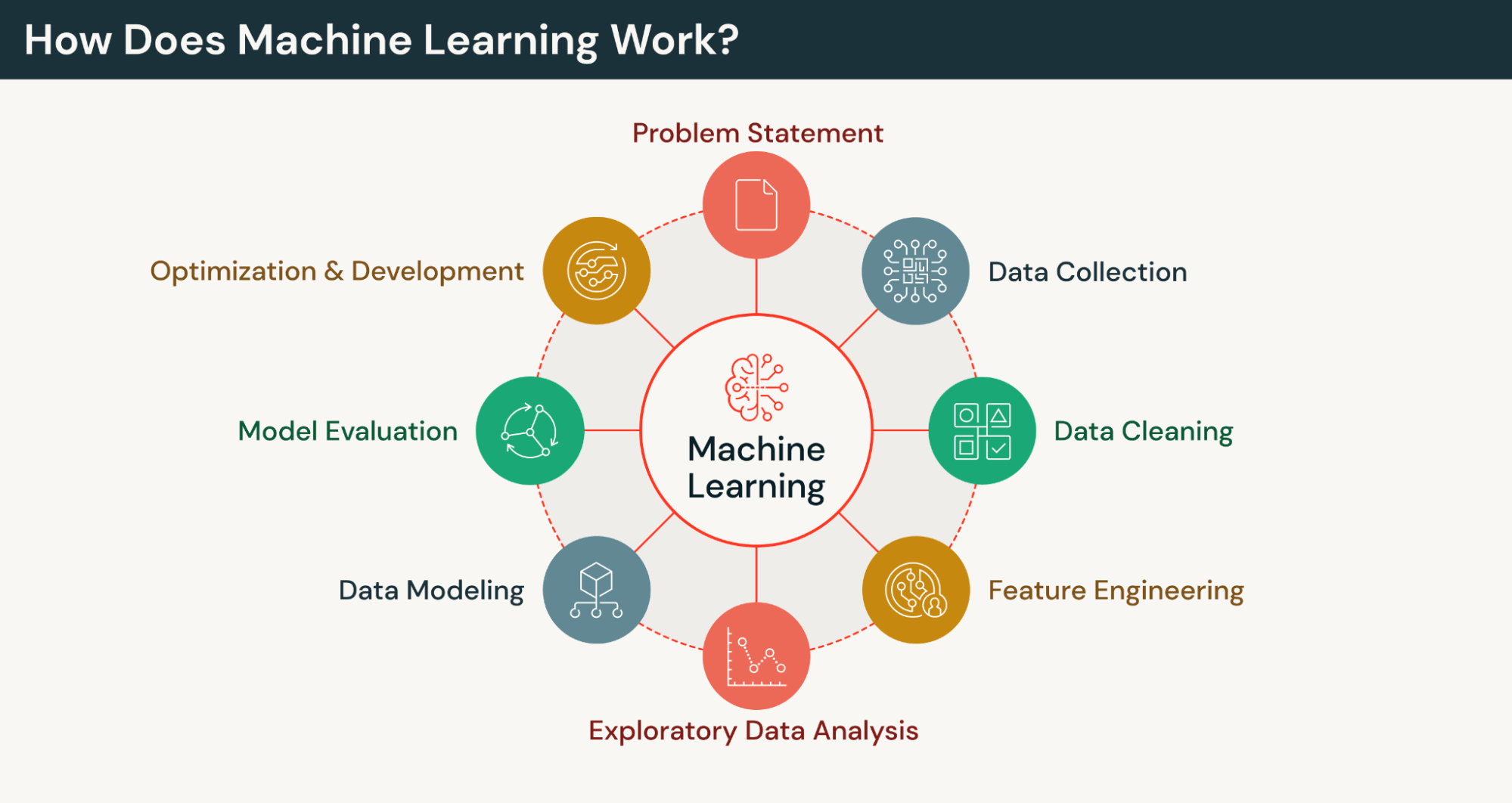
At a high level, machine learning works by using algorithms to learn from data and teach computers to recognize patterns so they can make predictions or decisions without being explicitly programmed.
ML works through a few core steps:
- Collect and prepare data — clean errors and duplicates, handle missing values, and convert text or images into numeric, machine-readable form.
- Split the data — use a training set to learn patterns and a validation set to evaluate performance.
- Train the model — compare predictions to actual outcomes and adjust internal parameters to reduce error and improve accuracy.
ML models are mathematical structures (the trained outputs) that find patterns in data to make predictions or classifications.
For example, an image classification system first collects the data (images) and converts the images (jpeg files) into numeric values. Features like edges, textures, color, etc. are manually extracted and an algorithm, such as logistic regression or support vector machine (SVM), is chosen to look at thousands of labeled examples and to make and compare predictions to actual labels to learn patterns that allow it to make predictions against new images. More complex approaches like deep learning can be used, in which case that model automatically extracts the features.
Machine Learning Model Optimization and Parameters
To show how ML learns from labeled historical data we’ll use a customer churn (churned vs. retained customers) prediction example with the goal of learning features and probability of churn. Each customer is represented as a set of numeric features (e.g., logins per week, support tickets, months as a customer, days since last login) and include this sample format: [logins, tickets, tenure, inactivity]
A simple scoring formula might look like this:
Churn Score = (A × support tickets) − (B × logins per week) − (C × months as a customer) + (D × days since last login) + Bias
Let’s say we use a logistic regression model and A, B, C, and D are model parameters. The model makes initial random guesses of churn probability for each parameter, compares those predictions vs actual labels, and adjusts internal weights to reduce errors.
After training, the model can score new customers and predict churn likelihood by discovering patterns like customers with x number of support tickets are more likely to churn, or customers with longer tenure are less likely to churn.
| Feature | Value |
|---|---|
| Logins | 3 |
| Inactivity | 14 days |
| Support Calls | 3 |
| Tenure | 2 months |
| Churn probability | = 72% |
The agentic AI playbook for the enterprise

Machine Learning Uses Cases
Machine learning is widely used in modern AI and data-driven systems across industries. This section will cover some practical, real-world applications.
Computer Vision
Computer vision is a machine learning domain focused on understanding and interpreting image and video data. It enables models to see and extract meaning from visual inputs. Common tasks include image classification, object detection, segmentation and text extraction (optical character recognition).
Real-world applications for computer vision include image analysis in healthcare, autonomous vehicles and driver monitoring systems, quality inspection and predictive maintenance for manufacturing, automated checkout and loss prevention in retail, and document processing in financial services.
Natural Language Processing (NLP)
Natural language processing (NLP) is a machine learning field focused on analyzing and generating human language data spanning both text and speech.
Real world applications of NLP include automated customer support (chatbots and virtual assistants), document processing, sentiment analysis in financial services, content tagging and summarization and text generation.
Time Series Analysis
Time series analysis as a machine learning approach applied to historical sequential or time-ordered data to forecast future values, detect trends, identify anomalies or understand temporal patterns.
Business use cases for time series analysis include demand forecasting for retail and e-commerce, monitoring systems for fraud detection or usage fluctuations for energy and utilities, and demand forecasting to predict quarterly revenue.
Image Generation
Image generation is a machine learning application where models create new images from learned data patterns such as text prompts, sketches or other images. Generated images are derived from patterns learned during training, not copied from inputs.
Models commonly used for image generation include diffusion models, which start with random noise and gradually diffuse it into high-quality images, variational autoencoders that compress images into a latent space and then reconstruct them, and generative adversarial networks where two networks compete to create fake images and detect fake images to improve through adversarial training.
Real world applications of image generation include content creation, design or simulation.

Machine Learning Use Cases Across Industries
| Industry | Use Case | ML Problem Type | Business Value |
|---|---|---|---|
| Financial Services | Fraud Detection | Classification / Anomaly Detection | Reduce financial losses |
| Retail | Demand Forecasting | Time Series Forecasting | Optimize inventory |
| Healthcare | Disease Prediction | Classification | Early intervention |
| Manufacturing | Predictive Maintenance | Time Series / Regression | Reduce downtime |
| Telecommunications | Network Traffic Forecasting | Time Series | Optimize infrastructure |
| Energy & Utilities | Equipment Failure Detection | Anomaly Detection | Prevent outages |
| Marketing | Customer Segmentation | Clustering | Targeted campaigns |
| Automotive | Autonomous Driving Perception | Computer Vision | Improve safety |
| Logistics | Route Optimization | Optimization / ML | Reduce delivery costs |
| HR | Resume Screening | NLP Classification | Faster hiring |
| SaaS / Tech | User Churn Prediction | Classification | Improve retention |
| Cybersecurity | Intrusion Detection | Anomaly Detection | Improve security posture |
| Media & Entertainment | Content Recommendation | Recommendation Systems | Increase engagement |
| Real Estate | Price Prediction | Regression | Accurate valuation |
Machine Learning Benefits and Challenges
From improved decision making and automation to reduced customer churn and healthcare diagnostics, machine learning is widely used today to deliver meaningful benefits across industries. Companies gain the most benefits when they have large amounts of structured data, clear business metrics, repeatable pattern-based problems and strong data governance.
Like any powerful technology, machine learning also comes with challenges, risks and limitations worth understanding. Success requires high-quality data, strong governance, technical expertise and ongoing model monitoring.
| Benefits | Challenges |
|---|---|
|
|
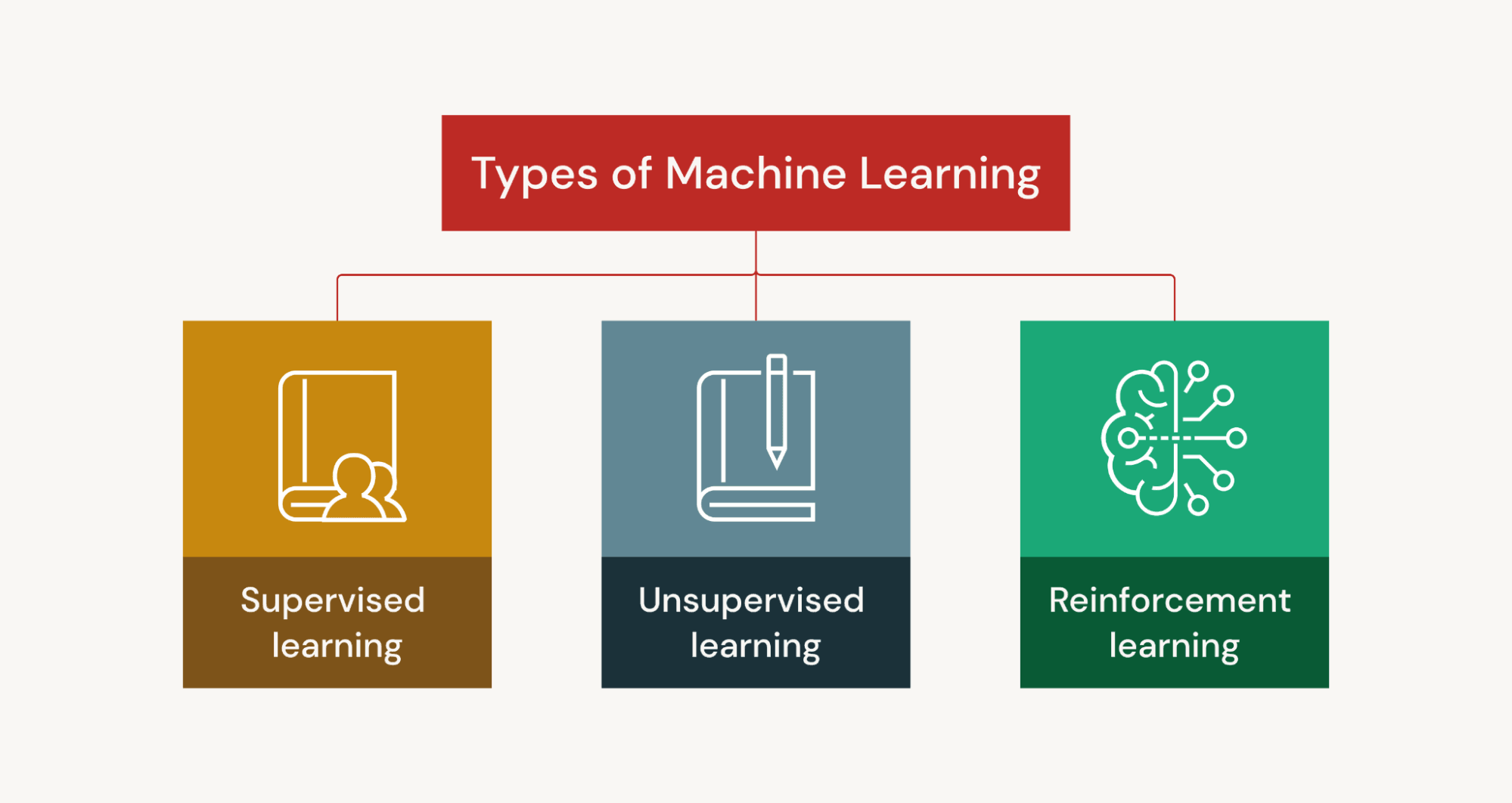
Types of Machine Learning
There are many categories of machine learning based on how models learn from data. While these approaches share the goal of enabling systems to learn from data, they differ in how learning occurs.
Supervised Learning
Supervised machine learning happens when the model learns a mapping from labeled data where inputs are paired with correct outputs to make predictions. It’s commonly used for classification (categories) and regression (continuous values) tasks. Regression tasks might include revenue forecasting and customer churn prediction while classification tasks could be spam or fraud detection.
Algorithms used for supervised learning include linear regression, logistic regression, decision trees, random forest, support vector machines and neural networks.
Models are trained and evaluated on “ground truth,” the actual or correct output for a given input. During training, predictions are compared to labels using a loss function, and parameters are updated to reduce error. A simple labeled dataset for spam detection might look like the following:
| Email ID | Email Text | Spam (Label) |
|---|---|---|
| 1 | “Win a free iPhone now!!! Click here” | Spam |
| 2 | “Team meeting at 2 PM today” | Not Spam |
| 3 | “Limited time offer – claim your prize” | Spam |
| 4 | “Here is the report you requested” | Not Spam |
| 5 | “Congratulations! You’ve won $1,000” | Spam |
Self-Supervised Learning
Self-supervised learning is a type of machine learning where the model learns from unlabeled data by creating its own labels from the data itself. It learns from raw data by predicting part of the data from other parts. This reduces reliance on manually labeled datasets which can be time-consuming, expensive and impractical at scale.
Common use cases for self-supervised learning include large language modeling or representation learning for applications such as natural language processing, computer vision, speech and multimodal data processing.
Semi-Supervised Learning
With semi-supervised learning, models are trained with a small amount of labeled data and a large amount of unlabeled data to improve accuracy with limited labels or when labeling is expensive. The labeled data provides initial guidance and the unlabeled data improves learning at scale.
Common use cases for semi-supervised learning are speech recognition and image recognition with limited labeled images.
Unsupervised Learning
Unsupervised machine learning is when the model learns from unlabeled data where no correct answer (ground truth) is provided and models generate labels from the data itself. There is no “correct” answer. The goal is to discover the underlying structure or patterns by predicting withheld or transformed data. This reduces the reliance on manually labeled datasets.
Unsupervised learning is commonly used to uncover hidden structures such as similarities, correlations and groupings that may not be obvious to humans in applications such as customer segmentation, market basket analysis and anomaly detection.
There are three main categories of unsupervised learning:
- Clustering – Grouping similar data points together based on patterns to discover natural segments in data. Clustering can be used for customer segmentation, grouping similar news articles and segmenting medical patients by symptoms.
- Association – Identifying relationships or co-occurrence patterns between variables in large datasets to discover “if-then” rules. Association rule learning is used in market basket analysis (customers who buy bread and peanut butter also buy jelly).
- Dimensionality reduction – Reducing the number of features while preserving key information. This data simplification technique is used for visualization, noise reduction and faster computation. Use case examples include compressing image data, visualizing high-dimensional datasets in 2D, and feature compression before modeling.
Unsupervised learning often requires careful data preprocessing and hyperparameter tuning to produce meaningful results.
Reinforcement Learning
Reinforcement Learning (RL) is a type of machine learning where an agent learns by trial and error, interacting with an environment, receiving rewards or penalties, and improving its behavior over time. Instead of learning from labeled data or pattern discovery, RL learns the best sequence of actions to maximize long-term reward.
In this type of learning the agent (learner/decisionmaker) makes decision using these core components:
- State – Agent observes the current situation
- Action – The choice the agent makes
- Reward signal – Feedback (positive or negative)
- Policy – Strategy for choosing actions or updating strategy
Reinforcement learning is commonly used for complex, sequential decision-making problems in applications like robotics, autonomous driving, game playing, recommendation systems and optimization. It can be implemented using policy-based RL (learning the policy directly, ie, “What should I do?”) or value-based RL where the policy is derived by choosing the action with the highest value (“if I take this action, how much future reward can be expected?”)
There is also a type of RL called deep reinforcement learning which uses neural networks to approximate policies and handle more complex environments (robotics) and larger state spaces (industrial control systems).
Deep Learning
Deep learning (DL) is a subset of machine learning that uses multi-layer artificial neural networks (“deep” networks) to automatically learn complex patterns directly from large amounts of data. “Deep” refers to the number of layers (sometimes hundreds) in the neural network vs traditional ML which use one-to-two layers of computation. Deep learning is powerful because it can model complex relationships in unstructured data like text, images, audio and video.
With DL, input data is passed through multiple neural network layers and each layer extracts more complex features until the final layer produces a prediction. Using an image recognition example, the input starts with a photo of a cat. The model automatically learns the features of ears, whiskers, fur, tail, body shape, etc. Layer 1 detects edges; layer 2 detects shapes, layer 3 detects objects; and the final layer predicts “cat” with 98% confidence. No manual feature engineering is required.
During training, the model has weights and parameters that can be adjusted after a prediction to improve model performance. Errors are quantified using a loss function that shows how bad the prediction is. A technique called backpropagation calculates how much each weight contributed to the error and an optimization algorithm called gradient descent updates weights in the direction that reduces error.
There are notable technical, operational and business tradeoffs with deep learning:
| Advantage | Tradeoff |
|---|---|
| High accuracy on complex tasks | Requires large amounts of labeled data |
| High performance | High GPU/TPU cost |
| Learns features automatically | Hard to interpret and explain |
| Handles unstructured data | Complex pipelines and infrastructure |
| Generalizes well with large data | Can overfit small datasets |
| Rapid advancements, cutting-edge capabilities | Models can become obsolete/frequent retraining |
| Powerful generative capabilities | Bias/misinformation, regulatory/ethical concerns |
Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are a type of deep learning model specifically designed to process and analyze image and video data that uses convolutional layers to process grid-like inputs. They automatically learn spatial features from images using convolutional filters and are the foundation of most modern computer vision systems, image classification, object detection and some applications in video and other structured data formats.
CNNs apply learned small filters and slide them across an image to automatically extract key features (e.g., edges, textures, shapes) to produce a feature map, reducing the need for manual feature engineering. Deeper layers detect higher-level features, and a final layer outputs a classification.
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) are a type of neural network designed to model sequential data where order and context matter. They are built to handle text, speech, time series, sensor data and video sequences.
Unlike feedforward networks, RNNs process inputs in a loop, remembering previous inputs in a sequence to influence later predictions. This creates an internal “memory” (hidden state) that helps RNNs capture dependencies in sequences like text, speech or time series data. Common use cases are language modeling (predicting the next word), machine translation, speech recognition and sentiment analysis.
Transformers
Transformers is a deep learning neural network architecture originally designed to process sequential data (like text) that now powers many state-of-the-art AI systems, including large language models. Transformers use a self-attention mechanism to understand relationships between all parts of a sequence at once. This allows the model to focus on the most relevant parts of the input when generating outputs or making predictions.
Before transformers, recurrent neural networks processed words one at a time, which was hard to scale. Transformers can process entire sequences of many data types (text, images, audio) in parallel, making it foundational to modern generative AI.
Mamba Models
Mamba models are a newer neural network architecture introduced in 2023 as an alternative to transformers, based on state space models (SSMs), designed to handle long sequences efficiently. SSMs were introduced to improve memory and computational efficiency and long-context processing.
Like transformers, Mamba models can prioritize the most relevant information in a sequence but use state-space dynamics instead of self-attention to process long sequences efficiently for large language model (LLM) workloads.
Machine Learning Operations (MLOps)
MLOps is a set of practices that operationalizes machine learning by making model development, deployment and maintenance repeatable, scalable and reliable in production. It manages the end-to-end lifecycle of ML models in a reliable, scalable and automated way.
The MLOps lifecycle
Data collection → data preparation → model training → model validation → deployment → monitoring → retraining
The operational priorities of machine learning systems are data quality and preprocessing, model selection, evaluation metrics, avoiding overfitting, inference reliability and ensuring models generalize beyond training data. ML systems require data pipelines, version control, automated training, deployment infrastructure, monitoring for performance and drift, governance and compliance. And production ML requires ongoing iteration.
With MLOps, automated pipelines retrain at scheduled intervals, the model version is stored in a registry, performance can be monitored daily, and alerts can be sent when accuracy drops.
Machine Learning Libraries
Machine learning libraries are pre-built software tools that provide reusable algorithms, utilities, and frameworks to help developers and data scientists build, train, evaluate and deploy ML models. Instead of building ML models from scratch, ML libraries and frameworks use pre-written code to implement models faster and easier.
Most ML development is done using common programming languages like Python and libraries provide standardized APIs for model development workflows.
Machine learning libraries fall into two general categories:
- Deep learning frameworks used for neural networks employ libraries such as PyTorch, TensorFlow, Keras, JAX and Hugging Face Transformers.
- Traditional ML/data science libraries used for regression, classification and clustering employ libraries such as scikit-learn, XGBoost, NumPy, Pandas, SciPy, Matplotlib.
Conclusion
Machine learning transforms data into predictive and adaptive systems by enabling models to learn from patterns rather than rely on hard-coded rules. While traditional analytics describe what has happened, ML extends those insights to predict outcomes, detect anomalies and automate decisions.
It forms the foundation of modern AI applications, powering large language models, computer vision, recommendation systems and generative AI. From supervised and unsupervised methods to reinforcement learning and deep learning, different approaches enable organizations to solve a wide range of technical and business problems.
As data volumes continue to grow, machine learning will remain central to building intelligent systems that scale, adapt and drive measurable impact.
Explore Databricks to see how teams build production-quality ML and GenAI applications grounded in enterprise data.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.