What is MLOps?
Practices and tools for deploying, monitoring, and governing ML models in production, bridging dev and ops for reliable, reproducible ML systems
- MLOps applies DevOps style practices to machine learning so teams can reliably take models from experiments into production and keep them running well over time.
- MLOps covers the full machine learning lifecycle from data preparation and model training to deployment, monitoring and governance, with automation and reproducibility at each stage.
- On Databricks, MLOps is supported by the Lakehouse Platform and MLflow, which centralize data, experiments, deployment and monitoring for production AI workloads.
What is MLOps?
MLOps stands for Machine Learning Operations. MLOps is a core function of Machine Learning engineering, focused on streamlining the process of taking machine learning models to production, and then maintaining and monitoring them. MLOps is a collaborative function, often comprising data scientists, devops engineers, and IT.
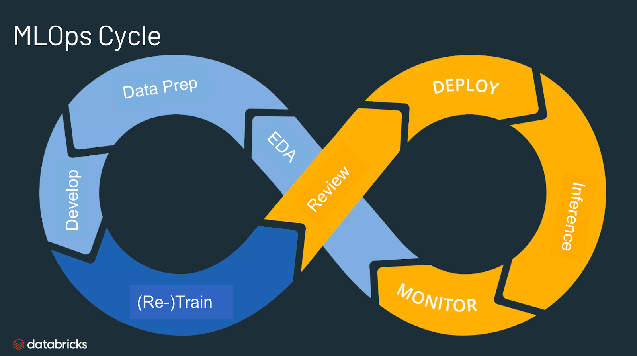
What is the use of MLOps?
MLOps is a useful approach for the creation and quality of machine learning and AI solutions. By adopting an MLOps approach, data scientists and machine learning engineers can collaborate and increase the pace of model development and production, by implementing continuous integration and deployment (CI/CD) practices with proper monitoring, validation, and governance of ML models.
Why do we need MLOps?
Productionizing machine learning is difficult. The machine learning lifecycle consists of many complex components such as data ingest, data prep, model training, model tuning, model deployment, model monitoring, explainability, and much more. It also requires collaboration and hand-offs across teams, from Data Engineering to Data Science to ML Engineering. Naturally, it requires stringent operational rigor to keep all these processes synchronous and working in tandem. MLOps encompasses the experimentation, iteration, and continuous improvement of the machine learning lifecycle.
What are the benefits of MLOps?
The primary benefits of MLOps are efficiency, scalability, and risk reduction. Efficiency: MLOps allows data teams to achieve faster model development, deliver higher quality ML models, and faster deployment and production. Scalability: MLOps also enables vast scalability and management where thousands of models can be overseen, controlled, managed, and monitored for continuous integration, continuous delivery, and continuous deployment. Specifically, MLOps provides reproducibility of ML pipelines, enabling more tightly-coupled collaboration across data teams, reducing conflict with devops and IT, and accelerating release velocity. Risk reduction: Machine learning models often need regulatory scrutiny and drift-check, and MLOps enables greater transparency and faster response to such requests and ensures greater compliance with an organization's or industry's policies.
What are the components of MLOps?
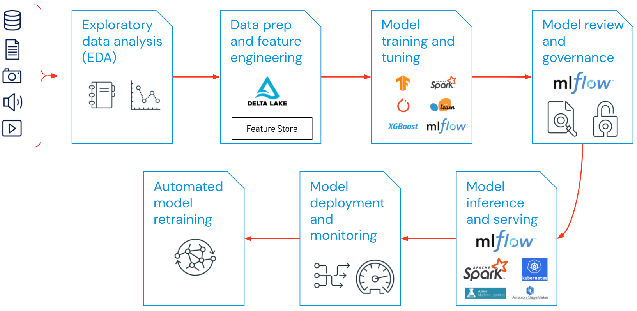
The span of MLOps in machine learning projects can be as focused or expansive as the project demands. In certain cases, MLOps can encompass everything from the data pipeline to model production, while other projects may require MLOps implementation of only the model deployment process. A majority of enterprises deploy MLOps principles across the following:
- Exploratory data analysis (EDA)
- Data Prep and Feature Engineering
- Model training and tuning
- Model review and governance
- Model inference and serving
- Model monitoring
- Automated model retraining
The agentic AI playbook for the enterprise

What are the best practices for MLOps?
The best practices for MLOps can be delineated by the stage at which MLOps principles are being applied.
- Exploratory data analysis (EDA) - Iteratively explore, share, and prep data for the machine learning lifecycle by creating reproducible, editable, and shareable datasets, tables, and visualizations.
- Data Prep and Feature Engineering- Iteratively transform, aggregate, and de-duplicate data to create refined features. Most importantly, make the features visible and shareable across data teams, leveraging a feature store.
- Model training and tuning - Use popular open source libraries such as scikit-learn and hyperopt to train and improve model performance. As a simpler alternative, use automated machine learning tools such as AutoML to automatically perform trial runs and create reviewable and deployable code.
- Model review and governance- Track model lineage, model versions, and manage model artifacts and transitions through their lifecycle. Discover, share, and collaborate across ML models with the help of an open source MLOps platform such as MLflow.
- Model inference and serving - Manage the frequency of model refresh, inference request times and similar production-specifics in testing and QA. Use CI/CD tools such as repos and orchestrators (borrowing devops principles) to automate the pre-production pipeline.
- Model deployment and monitoring - Automate permissions and cluster creation to productionize registered models. Enable REST API model endpoints.
- Automated model retraining - Create alerts and automation to take corrective action In case of model drift due to differences in training and inference data.
What is the difference between MLOps and DevOps?
MLOps is a set of engineering practices specific to machine learning projects that borrow from the more widely-adopted DevOps principles in software engineering. While DevOps brings a rapid, continuously iterative approach to shipping applications, MLOps borrows the same principles to take machine learning models to production. In both cases, the outcome is higher software quality, faster patching and releases, and higher customer satisfaction.
Does training large language models (LLMOps) differ from traditional MLOps?
While many of the concepts of MLOps still apply, there are other considerations when training large language models like Dolly. Let’s go through some of the key points where training LLMs might differ from the traditional MLOps approach:
- Computational Resources: Training and fine-tuning large language models typically involves performing orders of magnitude more calculations on large data sets. To speed this process up, specialized hardware like GPUs are used for much faster data-parallel operations. Having access to these specialized compute resources becomes essential for both training and deploying large language models. The cost of inference can also make model compression and distillation techniques important.
- Transfer Learning: Unlike many traditional ML models that are created or trained from scratch, many large language models start from a foundation model and are fine-tuned with new data to improve performance in a more specific domain. Fine-tuning allows state-of-the-art performance for specific applications using less data and fewer compute resources.
- Human Feedback: One of the major improvements in training large language models has come through reinforcement learning from human feedback (RLHF). More generally, since LLM tasks are often very open-ended, human feedback from your application’s end users is often critical for evaluating LLM performance. Integrating this feedback loop within your LLMOps pipelines can often increase the performance of your trained large language model.
- Hyperparameter Tuning: In classical ML, hyperparameter tuning often centers around improving accuracy or other metrics. For LLMs, tuning also becomes important for reducing the cost and computational power requirements of training and inference. For example, tweaking batch sizes and learning rates can dramatically change the speed and cost of training. Thus, both classical ML and LLMs benefit from tracking and optimizing the tuning process, but with different emphases.
- Performance Metrics: Traditional ML models have very clearly defined performance metrics, such as accuracy, AUC, F1 score, etc. These metrics are fairly straightforward to calculate. When it comes to evaluating LLMs, however, a whole different set of standard metrics and scoring apply — such as bilingual evaluation understudy (BLEU) and Recall-Oriented Understudy for Gisting Evaluation (ROGUE) that require some extra considering when implementing.
What is an MLOps platform?
An MLOps platform provides data scientists and software engineers with a collaborative environment that facilitates iterative data exploration, real-time co-working capabilities for experiment tracking, feature engineering, and model management, as well as controlled model transitioning, deployment, and monitoring. An MLOps automates the operational and synchronization aspects of the machine learning lifecycle.
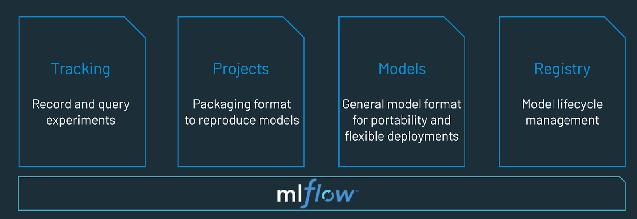
Try Databricks - a fully managed environment for MLflow - the world's leading open MLOps Platform. https://www.databricks.com/try/databricks-free-ml
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.