What is Deep Learning?
A subset of ML using multilayer neural networks to learn hierarchical feature representations from raw data for image recognition and language processing
- Deep learning is a type of machine learning that uses multi layer neural networks to automatically learn complex patterns from large amounts of data.
- Deep learning powers applications such as image and speech recognition, natural language processing and recommendation systems where traditional models struggle.
- On Databricks, deep learning workflows run on the lakehouse so teams can prepare data, train models at scale and integrate them into production applications.
What is Deep Learning?
AI has advanced rapidly in recent years, powering applications from conversational chatbots to automated medical diagnostics. Many of these advances are driven by deep learning, a branch of machine learning that enables computers to recognize patterns in complex data such as images, text and audio. Unlike traditional programming, where developers define explicit rules, deep learning models learn patterns directly from large datasets by adjusting internal parameters over time, allowing them to identify relationships that would be difficult or impossible to program manually.
Organizations across industries use deep learning to power advanced analytics and intelligent automation. Applications range from recommendation engines that personalize digital experiences to computer vision systems that detect manufacturing anomalies. By transforming large volumes of raw data into actionable insights, deep learning helps organizations build, deploy and scale AI-driven applications.
How do we define deep learning?
Deep learning is a subset of machine learning that uses neural networks to learn patterns from large amounts of data. These models are loosely inspired by biological neural systemsand are often called deep neural networks (DNNs). They automatically learn data representations instead of relying on rules programmed for specific tasks.
Deep learning models are especially effective for analyzing complex and unstructured data such as images, audio and text. As a result, they power many modern AI applications, including image recognition, speech processing, recommendation systems and large language models (LLMs).
How does deep learning work?
In deep learning, a model learns tasks such as classification, prediction, generation or representation learning directly from data such as images, text or sound. The model performs a task repeatedly, adjusting its internal parameters incrementally to improve accuracy. Models are trained by using a large set of labeled data and neural network architectures that contain many layers.
Deep learning neural networks include:
- computational nodes called “neurons”
- connections between neurons in underlying layers
- at least two hidden layers that enable more in-depth calculations
- weighted connections that help identify the most important features for classification
- an activation function that determines how each neuron's output signal is passed to the next layer.
The agentic AI playbook for the enterprise

Deep neural network structures
Deep neural networks are composed of layers of interconnected artificial neurons (ANNs) that pass information forward through the model. Each neuron receives input from the previous layer, applies a mathematical transformation, and passes the result to the next layer. The network learns by adjusting internal parameters during training so it can recognize patterns and improve prediction accuracy.
Several core components enable deep neural networks to learn complex patterns:
- Activation functions: introduce non-linear behavior so the network can capture complex relationships in data.
- Weights and biases: numerical parameters that control how strongly one neuron influences another. These values are updated during training to improve accuracy.
- Hidden layers: intermediate layers between the input and output layers that allow the model to learn hierarchical patterns in data.
Early layers often detect simple features, such as edges or shapes in images, while deeper layers identify more complex patterns. For example, raw image pixels may pass through multiple layers of computation before the model outputs probabilities for different classes.
For a deeper explanation of how neurons interact across layers, see the Databricks entry on neural networks.
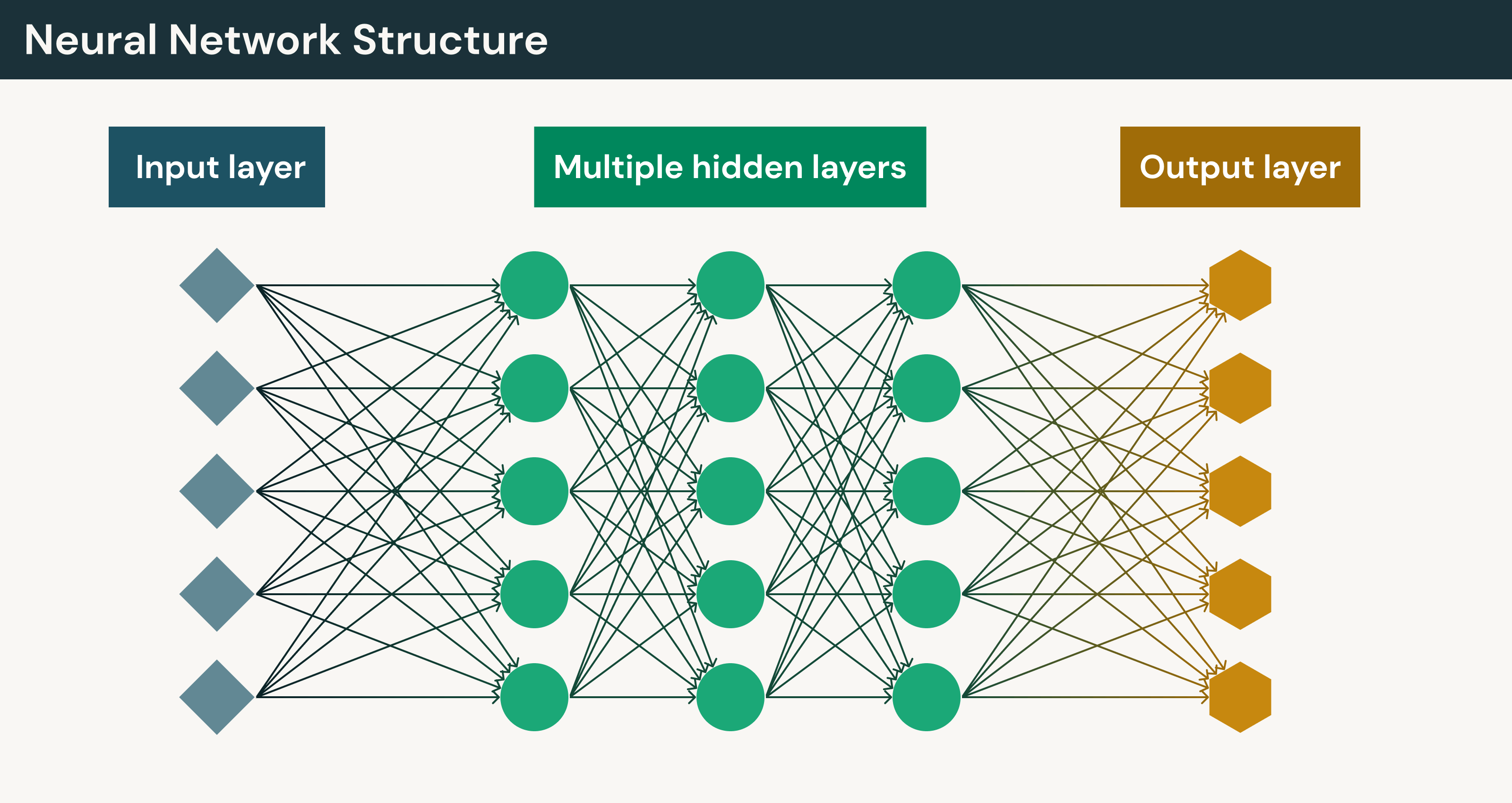
Types of deep learning layers
Deep learning models are built from several types of layers that work together to process data and generate predictions. Each layer plays a specific role in transforming raw input into meaningful outputs.
- Input layer: Receives the raw input data and passes it to the network.
- Hidden layers: Perform intermediate computations that transform the input into useful internal representations.
- Output layer: Produces the model’s final prediction, classification or generated value.
Training deep learning networks
Training a deep learning network is the process of adjusting a model's parameters so it can make accurate predictions from data. Deep learning models improve accuracy by repeatedly adjusting the weights and biases that connect neurons throughout the network.
The training process typically follows a cycle:
- Input data: The model processes training data such as images, text or audio.
- Prediction: The network generates an output or prediction.
- Error calculation: The prediction is compared to the correct answer and the difference is measured as a loss.
- Parameter updates: The model adjusts its internal parameters to reduce that error.
Deep learning networks can contain millions or even billions of parameters, making it impossible to manually determine how each connection contributes to prediction errors. Instead, training relies on mathematical optimization techniques such as backpropagation and gradient descent to determine how the model's parameters should be updated.
Backpropagation
Backpropagation is the process used to compute gradients of the loss with respect to each weight and bias.During training, the model's output is compared with the correct result, often called the ground truth. A loss function measures how far the prediction is from that correct answer.
The error signal is then sent backward through the network, layer by layer. As the error moves through the model, it calculates how each connection influenced the prediction and how those parameters should change to reduce the error.
By using backpropagation, deep learning systems can efficiently train very large neural networks.
Gradient descent
Gradient-based optimization methods such as stochastic gradient descent and Adam are used to update a model’s weights and biases during training.Gradient descent is an optimization method used to update a model's weights and biases during training. After backpropagation calculates how each parameter contributed to prediction error, gradient descent adjusts those parameters in the direction that reduces the loss function.
These adjustments occur in small steps across many training cycles as the model processes batches of data. Over time, the model may converge toward parameters that reduce prediction error, depending on the optimizer, learning rate and training dynamics.
Types of deep learning models
Deep learning includes a variety of neural network architectures designed to handle different types of data and tasks. While all deep learning models rely on layered neural networks, their structures are optimized for specific patterns such as images, text, sequences or relational data.
Common architectures include convolutional neural networks (CNNs) for image analysis, recurrent neural networks (RNNs) for sequential data and autoencoders for representation learning. Modern approaches such as transformers, diffusion models and graph neural networks extend deep learning to applications like large language models, generative AI and complex network analysis.
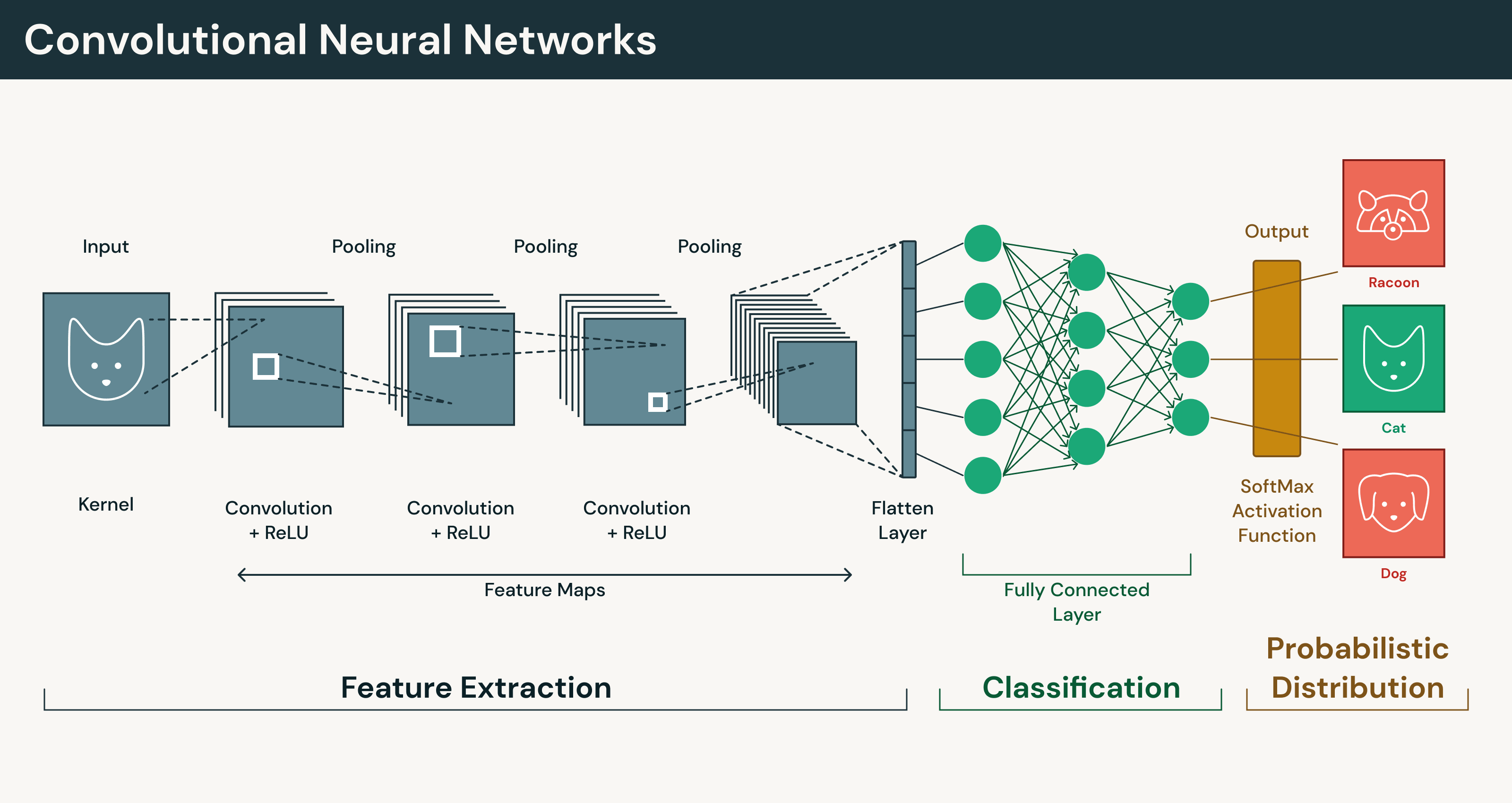
Convolutional neural networks (CNNs)
CNNs are deep learning models designed to process visual and spatial data. They are widely used in computer vision tasks such as image classification, object detection and image segmentation.
CNNs analyze images using convolutional layers that scan small regions to detect patterns. Instead of treating every pixel independently, the network learns visual features such as edges, shapes and textures. Early layers capture simple patterns, while deeper layers combine those signals into more complex representations. This ability to learn hierarchical visual features makes CNNs well suited for tasks such as medical imaging systems that detect tumors, facial recognition for identity verification and autonomous driving systems that interpret road conditions and obstacles.
Recurrent neural networks (RNNs)
RNNs are deep learning models designed to process sequential data, where the order of information matters. They are commonly used for tasks involving time series, speech and natural language text. Unlike feedforward neural networks, which treat each input independently, RNNs process inputs step by step so earlier outputs influence how the model interprets later inputs.
A key feature of RNNs is the hidden state, which acts as an internal memory that carries information forward through the sequence. This allows the model to capture relationships across time, such as how earlier words influence the meaning of later ones in a sentence. Traditional RNNs can struggle with long sequences because training may suffer from vanishing or exploding gradients, making it difficult to retain information from earlier steps. Architectures such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs) address this limitation by introducing mechanisms that help preserve important information across longer sequences.
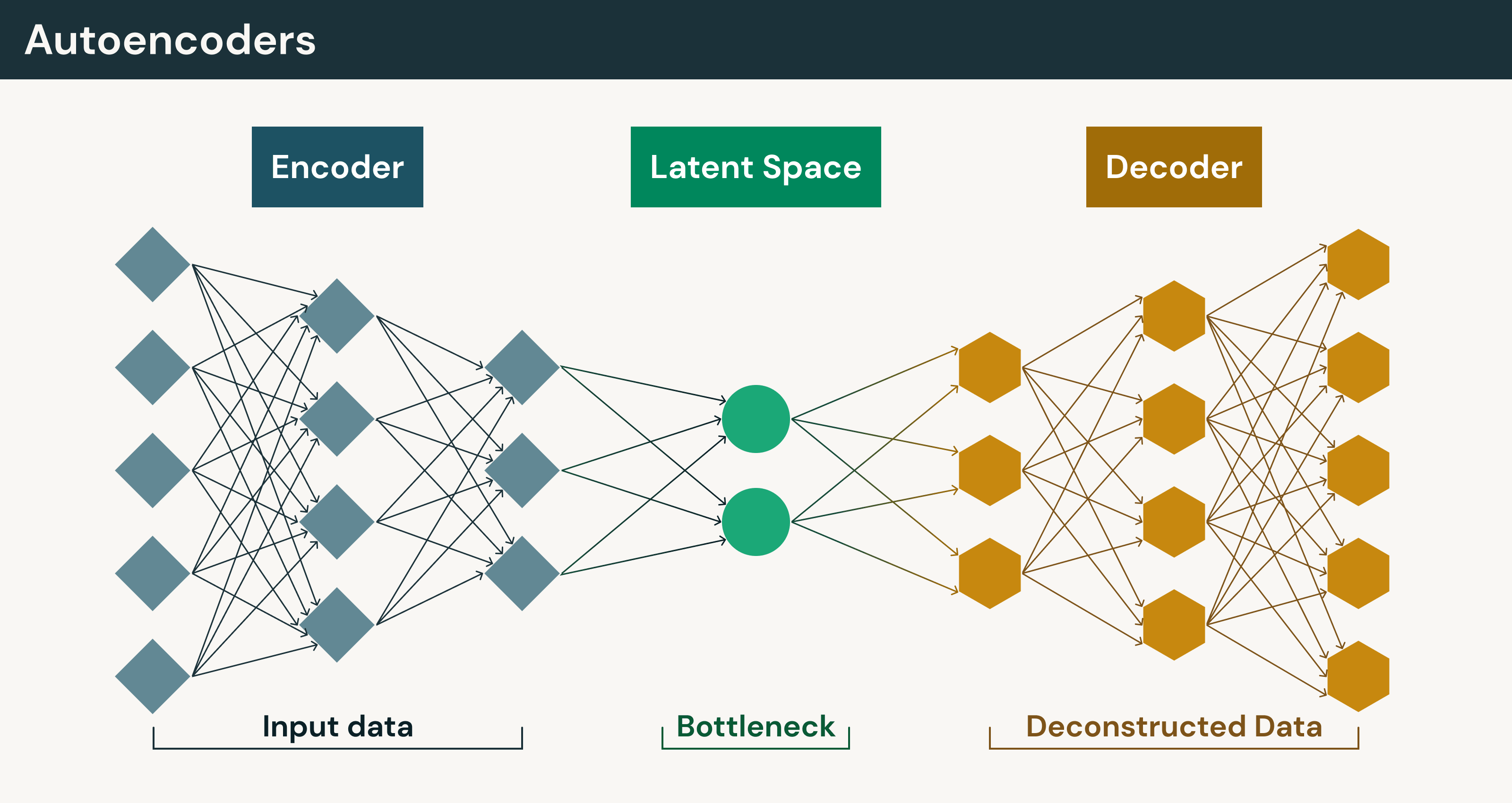
Autoencoders
Autoencoders are neural networks that compress input data into a smaller representation and then reconstruct the original data from that compressed form. The architecture includes two main components:
- Encoder: converts the input into a compact representation
- Decoder: reconstructs the original data from that representation
During training, the model minimizes reconstruction loss, the difference between the original input and the reconstructed output. Because the model learns patterns directly from the structure of the data rather than labeled examples, autoencoders are often considered a form of self-supervised learning.
The compressed representation learned by the encoder is known as the latent space, which captures the most meaningful features of the data in a lower-dimensional format. Learning this representation allows autoencoders to support tasks such as dimensionality reduction, feature extraction, denoising corrupted data, anomaly detection and data compression.
Transformer models
Transformer models are a deep learning architecture designed to process sequential data such as text, speech and time-series information.They rely on attention mechanisms, especially self-attention, to model relationships within a sequence. During training, transformers can process sequence elements in parallel, which improves efficiency compared with step-by-step sequence models.
Earlier sequence models such as RNNs process inputs step by step, which can slow training and limit how much context the model captures. Transformers instead analyze sequences in parallel, making it easier to train large models on massive datasets. This approach underpins many LLMs and supports applications including text generation, translation, summarization, audio processing and computer vision.
![]()
Mamba models
Mamba models are a newer deep learning architecture introduced in 2023 for processing sequential data. The architecture is built on state space models (SSMs), a framework designed to represent how information evolves over time within a sequence. Mamba models learn relationships across sequential inputs such as text, audio and time-series data.
Transformers rely on attention mechanisms to evaluate relationships between tokens. Mamba models instead track information through structured state updates that carry relevant context forward through a sequence. Structured state updates reduce memory and computational overhead, especially when working with very long inputs. Greater efficiency makes Mamba architectures an emerging architecture of interest for long-context and sequence-modeling tasks.
Generative adversarial networks (GANs)
Generative adversarial networks (GANs) are a class of generative deep learning models designed to create new data that resembles patterns in a training dataset. GANs train two neural networks together in a competitive process. One network, the generator, produces synthetic outputs such as images or videos. The other network, the discriminator, evaluates whether a sample appears real or artificially generated. Over time, the generator improves its outputs so they increasingly resemble real data.
GAN training follows a repeating cycle:
- Discriminator training: The discriminator learns to classify samples as real or fake using a mix of real data and synthetic data produced by the generator.
- Generator training: The discriminator is temporarily frozen while the generator updates its parameters using feedback from the discriminator.
- Adversarial improvement: Both networks improve together as the generator produces more realistic outputs and the discriminator becomes better at detecting them.
Training continues until the generated samples become difficult to distinguish from real ones. GAN training can be unstable and often requires careful tuning to avoid problems such as mode collapse or inconsistent outputs.
Diffusion models
Diffusion models are a class of generative deep learning models that produce realistic outputs — most commonly images — by learning how to remove noise from data.
Diffusion models use a two-part framework: a predefined forward process that gradually adds noise, and a learned reverse process that removes noise.:
- Noise addition: Gaussian noise is gradually added to training examples over multiple steps until the original signal becomes nearly indistinguishable from random noise.
- Noise removal: The model learns to reverse this process by predicting how to progressively remove noise and reconstruct the original data.
Once trained, diffusion models generate new outputs by starting with pure random noise and repeatedly applying the learned denoising process. Each step gradually transforms the noisy input into a more structured and realistic sample. The iterative approach has proven highly effective for generating high-quality images and forms the foundation of many modern generative AI systems. Compared with earlier techniques such as GANs, diffusion models often provide more stable training and more consistent output quality.
Graph neural networks
Graph neural networks (GNNs) are deep learning models designed to work with graph-structured data, where information is represented as nodes (entities) connected by edges (relationships). Unlike traditional deep learning models that process structured formats such as image grids or text sequences, graphs represent data as networks of interconnected elements. GNNs are especially useful for problems where understanding relationships between entities is more important than analyzing individual data points.
GNNs learn by passing information between connected nodes so each node can update its representation using both its own attributes and information from neighboring nodes. By capturing both direct and indirect connections across a network, GNNs allow machine learning systems to reason about complex relationships and patterns.
Conclusion
Deep learning is a subset of machine learning that uses multi-layer neural networks to learn complex patterns from large datasets. Its ability to capture relationships that traditional approaches often struggle to detect has made it a core technology behind many modern AI systems, including computer vision, speech recognition and LLMs.
That impact has made deep learning a foundational part of modern AI, especially as organizations expand into generative AI and more advanced machine learning use cases.
Ready to train custom deep learning models on your data? Explore Databricks Model Training and learn how it helps teams scale model development for production AI workloads.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.