Blazingly Fast Computer Vision Training with the Mosaic ResNet and Composer
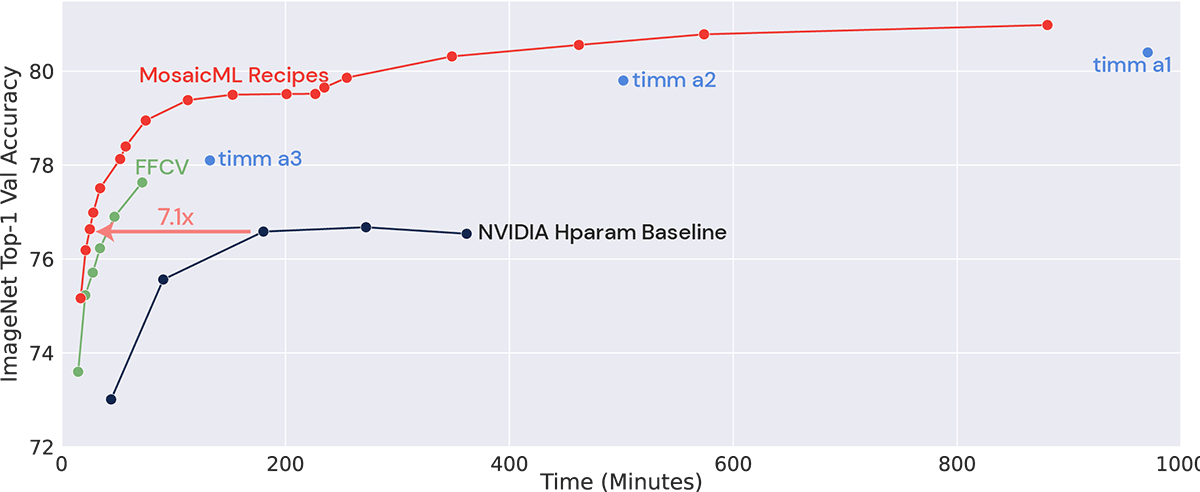
Match benchmark accuracy on ImageNet (He et al., 2015) in 27 minutes, a 7x speedup (ResNet-50 on 8xA100s). Reach higher levels of accuracy up to 3.8x faster than existing state of the art (Wightman et al., 2021). Try it out in Composer, our open-source library for efficient neural network training. It’s written in standard, easy-to-use PyTorch, so modify it to suit your needs and build on it!
Introducing the Mosaic ResNet, the most efficient recipe for training ResNets on ImageNet
ResNets are the workhorses of the computer vision world. Although they are ancient by deep learning standards (seven years old to be exact), they remain a go-to choice for image classification and as backbones for segmentation and object detection. In the years since ResNets first came out, hundreds of researchers have proposed improvements to the training recipe that speed up training or enhance final performance.
Today, we are releasing the Mosaic ResNet, a modern training recipe that combines a dozen of the best such improvements (including new improvements and better versions of existing ones that we developed in-house) with the goal of maximizing efficiency. Simply put, the Mosaic ResNet can be trained faster and cheaper than any other ResNet recipe we know of, and it does so without sacrificing any accuracy. This speedup is available for any budget, whether you plan a short training run to get baseline accuracy or a longer training run to reach the highest accuracy possible. These recipes modify the training algorithm; the network architecture is the same ResNet you’ve known and loved since 2015 (with updated anti-aliasing pooling via Blurpool).
The numbers speak for themselves. We measure efficiency by looking at the tradeoff between final accuracy and training time or cost (after all, time is money on the cloud; see our Methodology blog post for more details about how we quantify efficiency). As the plot below shows, for the same accuracy, the Mosaic ResNet is significantly faster than our NVIDIA Deep Learning Examples-derived baseline (7.1x faster) and other recently proposed training recipes like ResNet Strikes Back in the TIMM repository (2x to 3.8x) or the PyTorch blog (1.6x).
In the past, combining the diverse set of improvements in this recipe would have required assembling a hodgepodge of code and inserting it into your training loop in messy, ad hoc, bug-prone ways. For this reason, we built Composer, a PyTorch library that enables you to easily assemble recipes of improvements to train faster and better models. Composer makes it easy to use our new ResNet recipe, adapt it to suit your purposes, and improve on it. Composer contains dozens of improvements for numerous other tasks (like BERT, GPT, and image segmentation), and we will release many more efficiency-maximizing recipes in the coming months.
Quick Start: Using the Mosaic ResNet Recipe in Composer
This isn’t just about looking good for a benchmark. We’ve packaged these recipes of speedup methods, tuned all of the necessary hyperparameters, and made them available to you in PyTorch using Composer.
For example, some of the training techniques for one of our recipes can be easily specified with our Trainer in just a few lines of code:
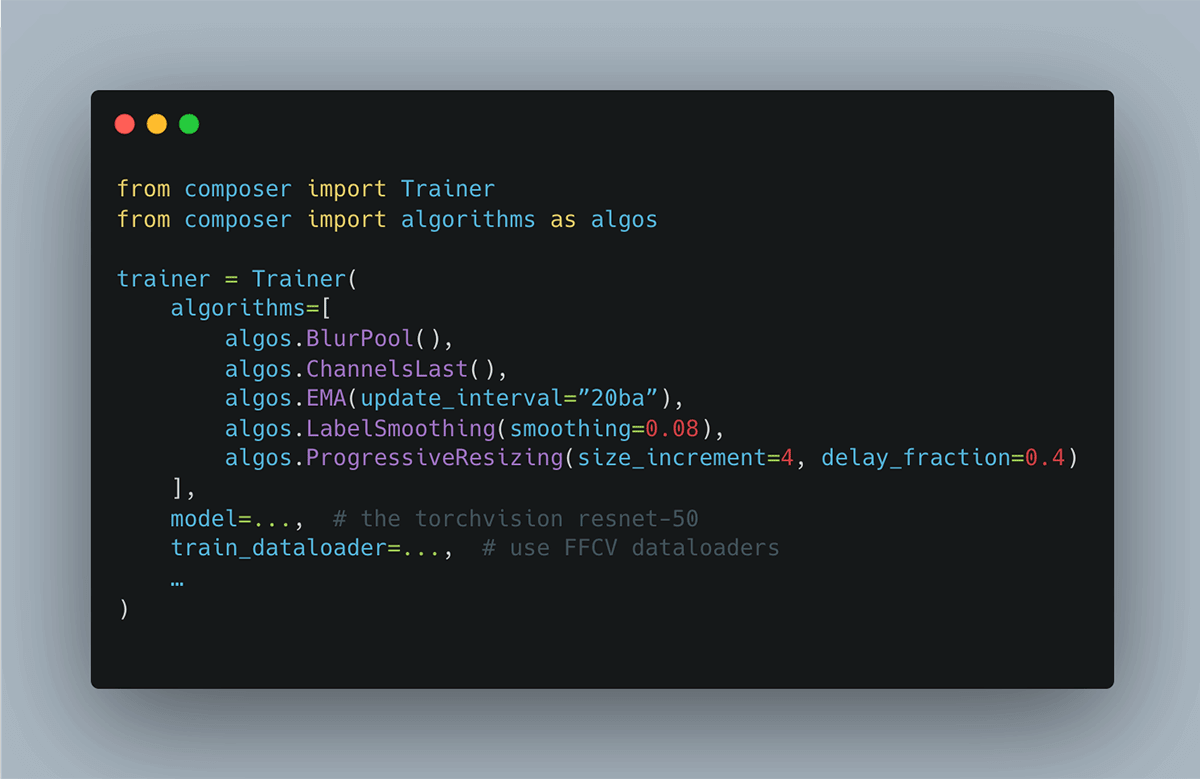
A few of them (binary cross-entry loss, train and test resolution, using FFCV dataloaders) need to be specified elsewhere. For full details on our hyperparameters, and scripts for easy reproduction, see our benchmarks repository.
Details on the Recipe
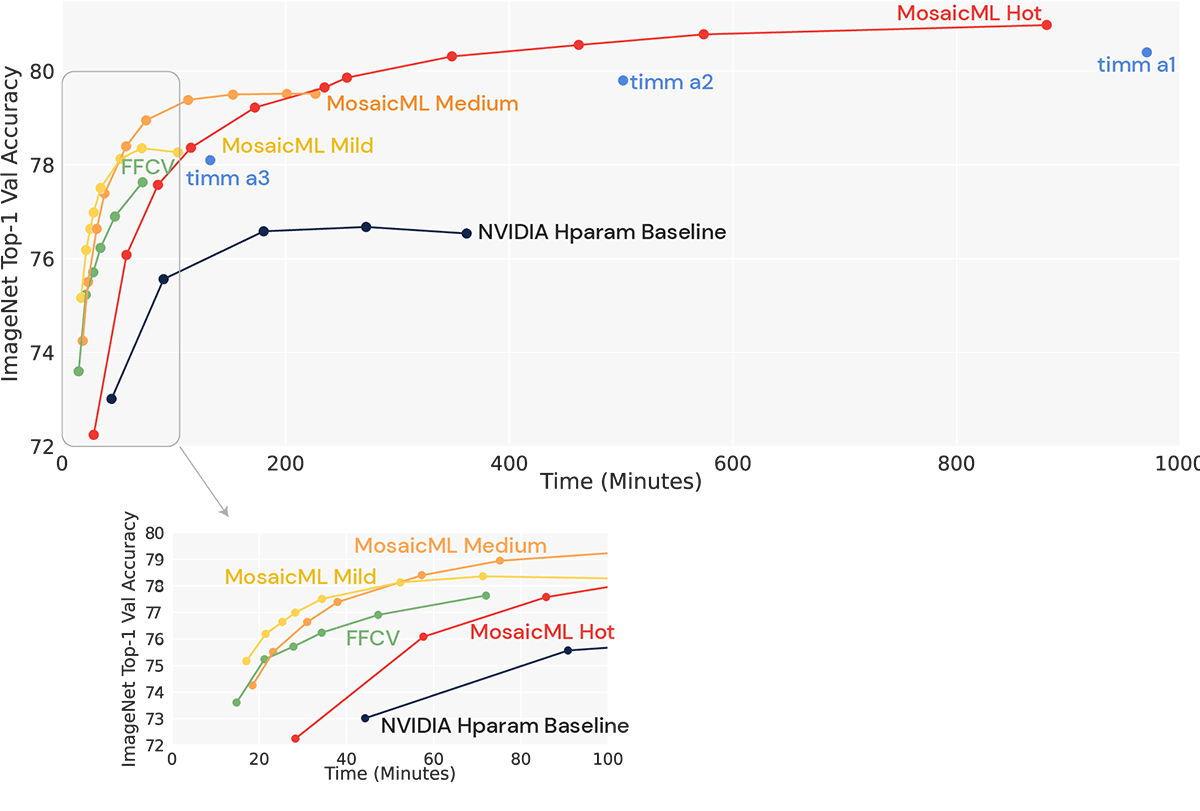
We actually cooked up three Mosaic ResNet recipes – which we call Mild, Medium, and Hot – to suit a range of requirements. The Mild recipe is for shorter training runs, the Medium recipe is for longer training runs, and the Hot recipe is for the very longest training runs that maximize accuracy. The most important difference between these recipes is that longer runs benefit from more regularization, while shorter runs suffer when they are over-regularized. The Medium and Hot recipes build on the Mild recipe by increasing regularization accordingly.

Conclusion
We developed a new recipe for training ResNets in the most efficient manner possible, getting you results faster and saving you money in the process. This Mosaic ResNet improves upon even the most competitive ResNet baselines, garnering speedups of up to 7.1x. You can check out the complete results of the hundreds of training runs we conducted to create this recipe using Explorer, our tool for evaluating the efficiency of training algorithms. Our recipes are fully replicable using Composer, our open-source library for efficient training, and you can use a publicly-available docker image for an easy path to run an environment with all the dependencies installed (Tag: resnet50_recipes).
While we’re satisfied with the range of recipes and hardware platforms we evaluated, there’s still so much more that can be done. Perhaps we overlooked your favorite baseline? Download Composer and benchmark against us! Maybe you have a homebrew wafer-scale system that Composer could bring speedups to? Profile our recipes on your own hardware! Is there a speed-up method that you think could make the Mosaic ResNet even better? Add it to Composer and let us know! And please, be a part of our community and give us feedback on Twitter and Slack.
Hungry for more?
Stay tuned for a much deeper dive on all the details – a comprehensive write-up on the science and engineering of this work - and more Mosaic recipes on popular benchmarks like BERT and GPT. Star our Github repo to stay plugged into the latest updates and speedups.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.