MosaicML StreamingDataset: Fast, Accurate Streaming of Training Data from Cloud Storage
by James Knighton, Karan Jariwala, Davis Blalock and Erica Ji Yuen
Loading your training data becomes an escalating challenge as datasets grow bigger in size and the number of nodes scales. We built StreamingDataset to make training on large datasets from cloud storage as fast, cheap, and scalable as possible. Specially designed for multi-node, distributed training, StreamingDataset maximizes correctness guarantees, performance, and ease of use.
Give our StreamingDataset repo a star here!

What's the Problem?
Sometimes feeding data into your model is easy. If you're training on your personal workstation with data already saved locally, chances are that everything will just work.
But what happens when you spin up a remote instance in the cloud? What if your data lives in an object store like S3? What if you want to do distributed training on multiple machines at once? What if you're pretraining a language model using a single pass through your entire dataset and need to pick up where you left off after a crash?
As soon as any of these situations arise, you can quickly find yourself wasting huge amounts of compute and developer time. Even worse, there are many subtle errors that can corrupt your training or evaluation.
At MosaicML, we've spent thousands of dollars and hundreds of hours on:
- Debugging network file systems
- Forgetting to delete provisioned cloud storage devices
- Under-utilizing our GPUs while waiting for large dataset downloads
- Paying quadruple egress fees when downloading redundant data across different machines
- Ruining training runs with incorrect data partitioning across nodes
And we've gotten off easy. For example, when training their OPT models, Meta reported wasting thousands of GPU-hours replaying their data loading after crashes in order to resume training where they left off.

After trying for weeks to get existing solutions like TorchData or WebDataset to work, we concluded that we needed to build our own dataset library to get the correctness guarantees, performance, and ease of use we needed. That's why we developed MosaicML StreamingDataset.
Correctness: No Silent Pitfalls
There are many ways to silently alter your results when doing distributed training. For example, it's easy to accidentally train on the same data on each machine or device, duplicating the same samples over and over again in each batch - impacting your model convergence.
Another pitfall of some existing solutions is that the data ordering depends on the number of devices. This can create "heisenbugs" where you encounter an issue in your "real" training run but can't reproduce it when debugging on a single machine. It also means that changing the number of devices during a training run—to deal with node failures or altered availability—changes the semantics of your run. E.g., your "single epoch" training run could end up seeing the same document before and after changing the device count.
To fix problems like these, StreamingDataset's shuffling algorithm randomizes and distributes data samples up front - so each data sample has a slot to go to. StreamingDataset automatically loads disjoint samples across logical machines, with deterministic sample ordering independent of the real number of devices you're using. Moreover, to get sufficient randomness in sample ordering, StreamingDataset shuffles across all samples assigned to a machine, rather than only the samples assigned to one data loader process for one device.
Efficiency: Faster Startup, Lower Costs
If you've ever trained on an ImageNet-scale dataset using cloud instances, you've probably had the unpleasant experience of waiting tens of minutes for the data to download from your storage bucket and/or get read from an attached storage device.
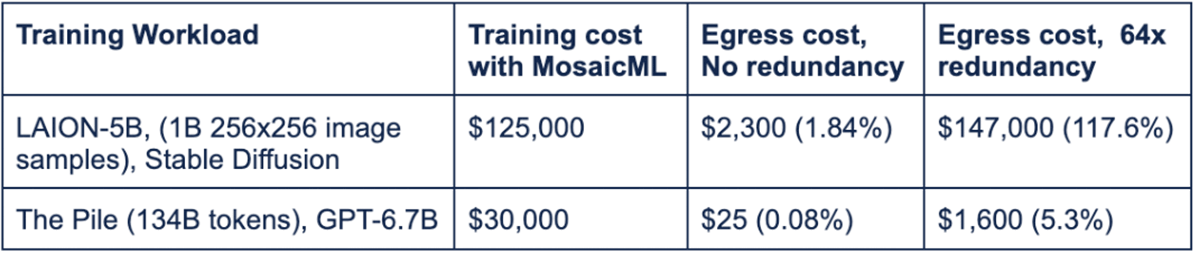
And if you've dug into the costs of this sort of training job, you may have noticed large egress fees. For example, if you store your data in AWS S3 in one region but train in another region (perhaps with better GPU availability), downloading ImageNet at the start of your run will cost you about $3. And what happens if you train on four machines at once? Each machine will download its own copy of the entire dataset. So instead of paying $3, you pay $12.
Do download costs matter? With no redundant data downloads, they probably don't (see Table 1). But if you duplicate data across many machines, they can increase the training cost significantly.
To reduce startup times and download costs, StreamingDataset includes a number of optimizations:
First, StreamingDataset lets different training machines download disjoint subsets of the dataset. This means that no matter how many machines you train on, you only download the data once.
StreamingDataset also downloads samples asynchronously. Training begins as soon as a batch's worth of samples are downloaded and proceeds to each successive batch as soon as those samples are downloaded. This reduces startup time as much as logically possible without altering the training.
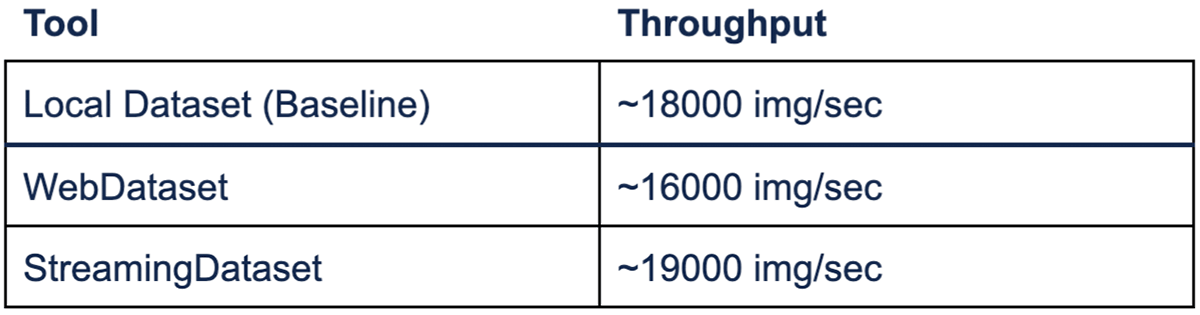
To drive down egress and storage costs further, StreamingDataset supports best-in-class compression algorithms like Zstd, Brotli, and bzip2. Furthermore, StreamingDataset's MDS format cuts extraneous work to the bone, resulting in higher throughput for workloads that are bottlenecked by the dataloader, meaning the training job finishes in less time.1
As a final optimization, StreamingDataset uses its deterministic sample ordering to gracefully resume training right where it left off, without having to pause and replay the whole dataset-so-far. Moreover, it does so without re-downloading data you've already trained on during single-epoch training. This fast resumption can save thousands of dollars in egress fees and idle GPU compute time compared to existing solutions.
Works at Scale
These optimizations are great, but don't just take our word for it. Actually…maybe you should. Because our research team uses StreamingDataset all the time on real-world training jobs. The models below were trained on on-premise or OCI hardware, with data streaming from AWS S3.
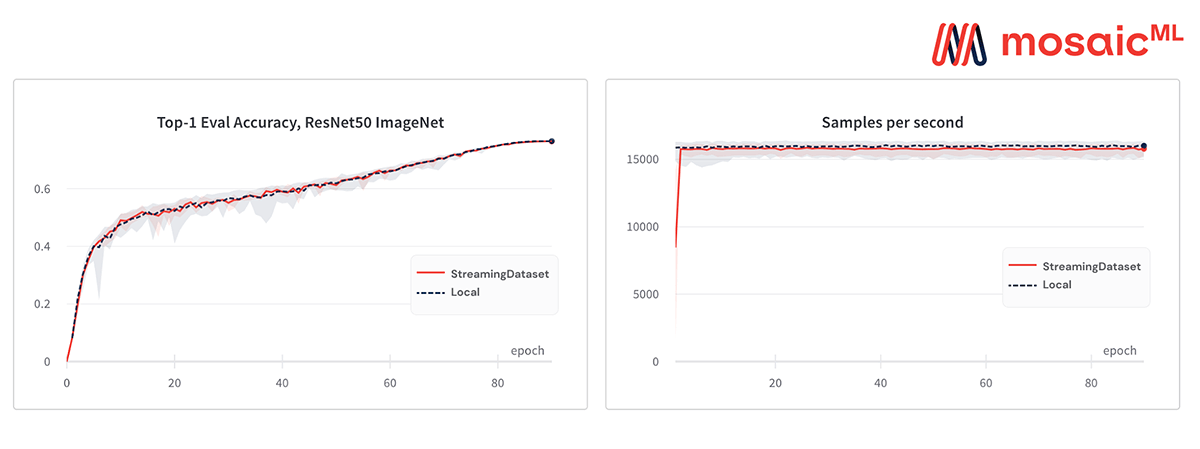
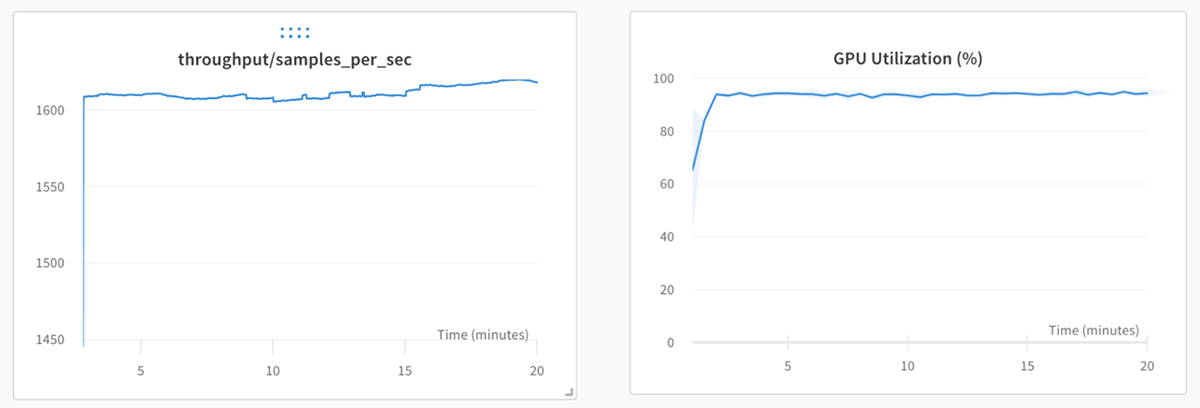
Stable Diffusion on LAION-400m
StreamingDataset starts up in two minutes and streams fast enough to keep all GPUs busy.
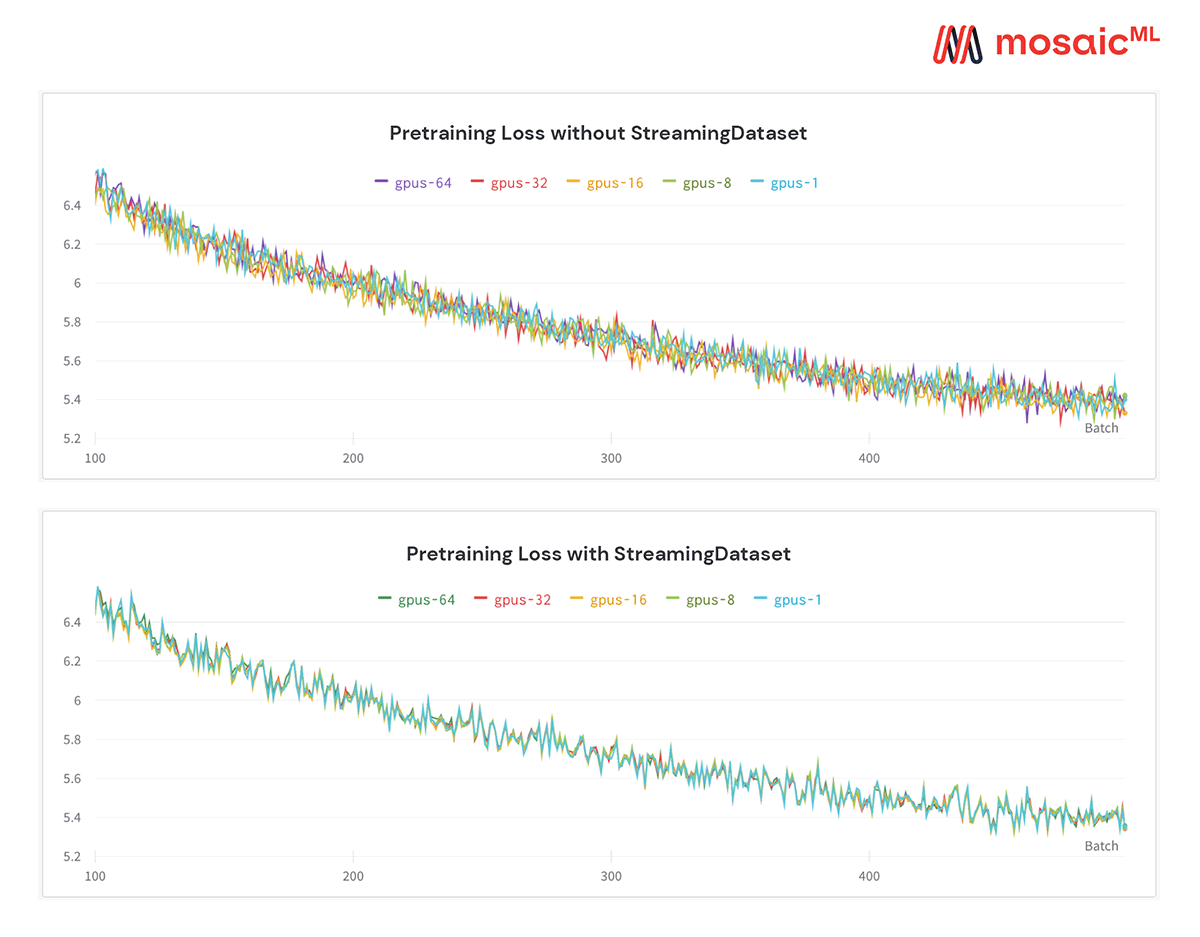
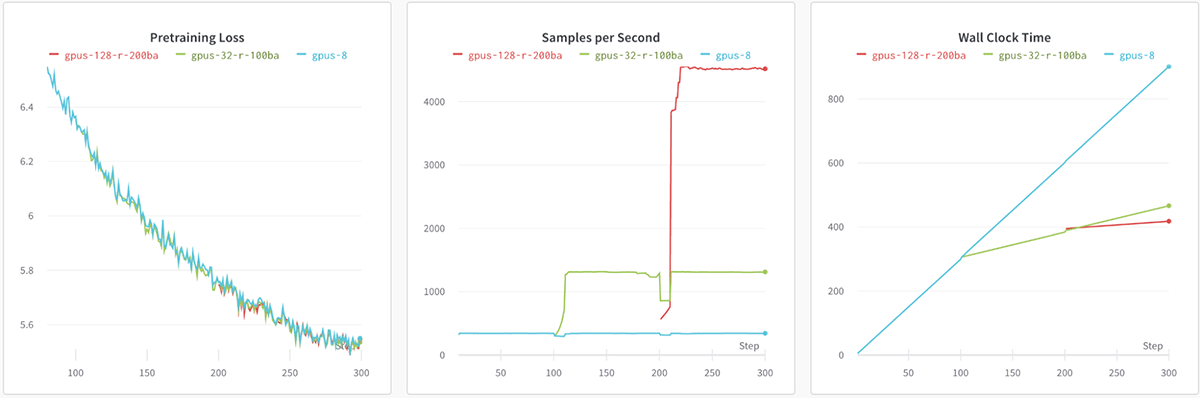
GPT on The Pile
StreamingDataset can stop and resume training on any # of devices with deterministic results. Here, we train a GPT model for 300 steps on 8 GPUs, checkpointing to object storage every 100 batches. We resume the run on 32 GPUs from the checkpoint @ batch-100, and continue training and checkpointing. Finally, we resume the run on 128 GPUs from the new checkpoint @ batch-200. The throughput scales linearly as expected, and the training loss curve for all three runs is the same (within numerics).
In fact, all of our previous model work across PubMedGPT, Segmentation, Classification, and general-purpose LLM pretraining was done with MosaicML StreamingDataset!
Ease of Use: The StreamingDataset
Ready for the best part? We expose all the above functionality through a simple StreamingDataset class, a drop-in replacement for your existing PyTorch IterableDataset to seamlessly integrate into your existing training workflows.
StreamingDataset supports a variety of data formats, including CSV, TSV, JSONL, and our versatile Mosaic Data Shard (MDS) format. Transcoding to MDS gets you the most speed and is easy to do; we provide plenty of example scripts, and our MDSWriter will automatically transcode common data types like numbers, text, images, and any Python object.
Based on feedback from customers and internal users, we've also added a number of usability features:
- Random access: Even if a sample isn't downloaded yet, you can access
my_dataset[i]to get samplei. The download will kick off immediately and the result will be returned when it's done. - Zero-redundancy subsets: Because we support random access and just-in-time downloading, you can store your dataset once and let different users work with different subsets of it.
- Arbitrary data types and encodings: When creating an MDS dataset, you aren't limited to common data types. You can pass any Python objects you want, along with
encode()anddecode()callbacks to convert the objects to and from bytes.
With these and other features, StreamingDataset ensures you have complete control over your data without sacrificing efficiency.
Getting Started
We designed StreamingDataset so that you can get started quickly.
1. First, install the library via pip:
2. Next, convert your raw dataset into one of our supported streaming formats:
- MDS (Mosaic Data Shard) format, which can encode and decode any Python object
- CSV / TSV
- JSONL

3. Upload your streaming dataset to the cloud storage of your choice ( AWS, OCI and GCP are supported today; Azure is coming soon). Below is one example of uploading a directory to an S3 bucket using the AWS CLI.
4. In your training code, replace the original PyTorch IterableDataset with your new streaming.StreamingDataset.
And that's it! Check out our StreamingDataset docs for more detailed information and end-to-end NLP and vision examples.
What's Next?
If you like MosaicML Streaming, give us a star on GitHub! Also, feel free to send us feedback through our Community Slack or opening an issue on Github. For updates on all the new features we're adding, follow us on Twitter!
Finally, if you've felt any of the large-scale machine learning pain points we've talked about, you might be interested in the MosaicML Cloud platform. We'll get you training high-quality, multibillion-parameter models in hours instead of months. We handle the heavy lifting and orchestration, so you can focus on your model training. If this sounds good, sign up for a demo today!
1 For larger model training like LLMs and Stable Diffusion, this effect disappears as the models are not dataloader bottlenecked.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.