Optimizing Materialized Views Recomputes
by Andrea Tardif and Justin Edrington
- How to detect and monitor materialized view (MV) refresh behavior in Lakeflow Declarative Pipelines
- Common causes of unnecessary full recomputes in MVs
- Best practices for optimizing incremental refreshes and managing complete recomputes to improve performance and control costs
Optimize Incremental Computation of Materialized Views
While digital-native companies recognize the critical role AI plays in driving innovation, many still face challenges in making their ETL pipelines operationally efficient.
Materialized Views (MVs) exist to store precomputed query results as managed tables, allowing users to access complex or frequently used data much faster by avoiding repeated computation of the same queries. MVs improve query performance, reduce computational costs, and simplify transformation processes.
Lakeflow Declarative Pipelines (LDP) provide a straightforward, declarative approach to building data pipelines, supporting both full and incremental refreshes for MV. Databricks pipelines are powered by the Enzyme engine, which efficiently keeps MVs up to date by tracking how new data affects the query results and only updating what is necessary. It utilizes an internal cost model to select among various techniques, including those employed in materialized views and manual ETL patterns commonly used.
This blog will discuss detecting unexpected full recomputes and optimizing pipelines for proper incremental MV refreshes.
Key Architectural Considerations
Scenarios for Incremental & Full Refreshes
A full recompute overwrites the results in the MV by reprocessing all available data from the source. This can become costly and time-consuming since it requires reprocessing the entire underlying dataset, even if only a small portion has changed.
While incremental refresh is generally preferred for efficiency, there are situations where a full refresh is more appropriate. Our cost model follows these high-level guidelines:
- Use a full refresh when there are major changes in the underlying data, especially if records have been deleted or modified in ways that the cost model can efficiently compute and apply the incremental change.
- Use an incremental refresh when changes are relatively minor and the source tables are frequently updated—this approach helps reduce compute costs.
Enzyme Compute Engine
Instead of recomputing entire tables or views from scratch every time new data arrives or changes occur, Enzyme intelligently determines and processes only the new or changed data. This approach dramatically reduces resource consumption and latency compared to traditional batch ETL methods.
The diagram below outlines how the Enzyme engine intelligently determines the optimal way to update a materialized view.
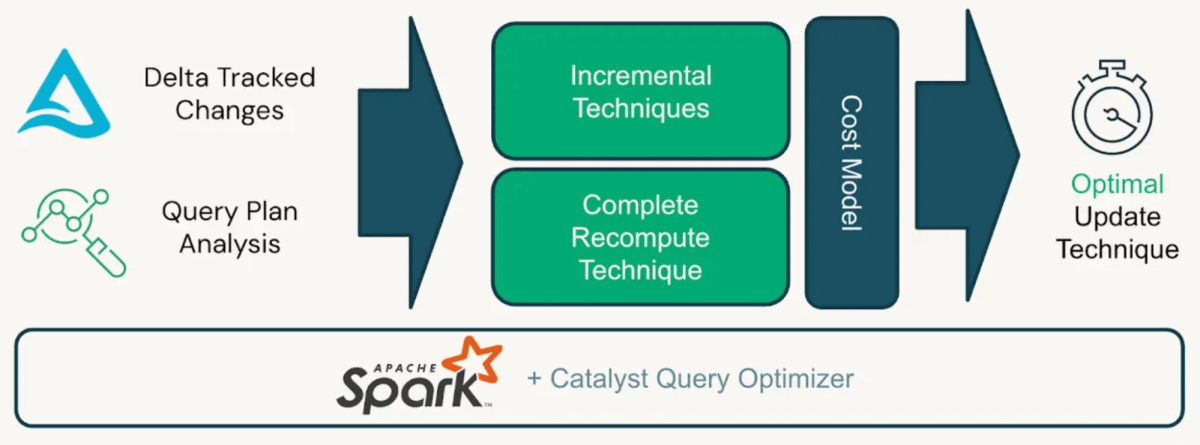
The Enzyme engine selects the update strategy and determines whether to perform an incremental or full refresh based on its internal cost model, optimizing for performance and compute efficiency.
Enable Delta Table Features
Enabling row tracking on source tables is required to incrementalize the MV recompute.
Row tracking helps detect which rows have changed since the last MV refresh. It enables Databricks to track row-level lineage in a Delta table and is required for specific incremental updates to materialized views.
Enabling deletion vectors is an optional feature. Deletion vectors allow Databricks to track which rows have been deleted from the source table. This prevents the need to rewrite full files, and avoids rewriting entire files when only a few rows are deleted.
To enable these table features on the source table, leverage the following SQL code:
Technical Solution Breakdown
This next section will walk through an example on how to detect when a pipeline triggers a full recompute versus an incremental refresh on an MV and how to encourage an incremental refresh.
This technical walkthrough follows these high-level steps:
- Generate a Delta table with randomly generated data
- Create and use a LDP to create a materialized view
- Add a non-deterministic function to the materialized view
- Re-run the pipeline and observe the impact on the refresh behavior
- Update the pipeline to restore incremental refresh
- Query the pipeline event log to inspect the refresh technique
To follow along with this example, please clone this script: MV_Incremental_Technical_Breakdown.ipynb
Within the run_mv_refresh_demo() function, the first step generates a Delta table with randomly generated data:
Next, the following function is run to insert randomly generated data. This is run before each new pipeline run to ensure that new records are available for aggregation.
Then, the Databricks SDK is used to create and deploy the LDP.
MVs can be created through either a serverless LDP or Databricks SQL (DBSQL) and behave the same. DBSQL MVs launch a managed serverless LDP that is coupled to the MV under the hood. This example leverages a serverless LDP to utilize various features, such as publishing the event log, but it would behave the same if a DBSQL MV were used.
Once the pipeline is successfully created, the function will then run an update on the pipeline:
After the pipeline has successfully run and created the initial materialized view, the next step is to add more data and refresh the view. After running the pipeline, check the event log to review the refresh behavior.
The results show that the materialized view was incrementally refreshed, indicated by the GROUP_AGGREGATE message:
| Run # | message | Flow Type |
|---|---|---|
| 2 | Flow '<catalog_name>.demo.random_data_mv' has been planned in DLT to be executed as GROUP_AGGREGATE. | No non-deterministic function. Incrementally refreshed. |
| 1 | Flow '<catalog_name>.demo.random_data_mv' has been planned in DLT to be executed as COMPLETE_RECOMPUTE. | Initial Run. Full recompute. |
Next, to demonstrate how adding a non-deterministic function (RANDOM()) can prevent the materialized view from incrementally refreshing, the MV is updated to the following:
To account for changes in the MV and to demonstrate the non-deterministic function, the pipeline is executed twice, and data is added. The event log is then queried again, and the results show a full recompute.
| Run # | Message | Explanation |
|---|---|---|
| 4 | Flow 'andrea_tardif.demo.random_data_mv' has been planned in DLT to be executed as COMPLETE_RECOMPUTE. | MV includes non-deterministic — full recompute triggered. |
| 3 | Flow '<catalog_name>.demo.random_data_mv' has been planned in DLT to be executed as COMPLETE_RECOMPUTE. | MV definition changed — full recompute triggered. |
| 2 | Flow '<catalog_name>.demo.random_data_mv' has been planned in DLT to be executed as GROUP_AGGREGATE. | Incremental refresh — no non-deterministic functions present. |
| 1 | Flow '<catalog_name>.demo.random_data_mv' has been planned in DLT to be executed as COMPLETE_RECOMPUTE. | Initial run — full recompute required. |
By adding non-deterministic functions, such as RANDOM() or CURRENT_DATE(), the MV cannot incrementally refresh because the output cannot be predicted based solely on changes in the source data.
Within the pipeline event log details, under planning_information, the JSON event details provide the following reason for preventing incrementalization:
If having a non-deterministic function is necessary for your analysis, a better approach is to push that value into the source table itself, rather than calculating it dynamically in the materialized view. We will accomplish this by moving the random_number column to pull from the source table instead of adding it in at the MV level.
Below is the updated materialized view query to reference the static random_number column within the MV:
Once new data is added and the pipeline is run again, query the event log. The output shows that the MV performed a GROUP_AGGREGATE rather than a COMPLETE_RECOMPUTE!
| Run # | Message | Explanation |
|---|---|---|
| 5 | Flow '<catalog_name>.demo.random_data_mv' has been planned in DLT to be executed as GROUP_AGGREGATE. | MV uses deterministic logic — incremental refresh. |
| 4 | Flow '<catalog_name>.demo.random_data_mv' has been planned in DLT to be executed as COMPLETE_RECOMPUTE. | MV includes non-deterministic — full recompute triggered. |
| 3 | Flow '<catalog_name>.demo.random_data_mv' has been planned in DLT to be executed as COMPLETE_RECOMPUTE. | MV definition changed — full recompute triggered. |
| 2 | Flow '<catalog_name>.demo.random_data_mv' has been planned in DLT to be executed as GROUP_AGGREGATE. | Incremental refresh — no non-deterministic functions present. |
| 1 | Flow '<catalog_name>.demo.random_data_mv' has been planned in DLT to be executed as COMPLETE_RECOMPUTE. | Initial run — full recompute required. |
A full refresh can be automatically triggered by the pipeline under the following conditions:
- Use of non-deterministic functions like UUID() and RANDOM()
- Creating materialized views that involve complex joins, such as cross, full outer, semi, anti, and large numbers of joins.
- Enzyme determines that it is less computationally expensive to perform a full recompute
Learn more about incremental refresh compatible functions here.
Real World Data Volume
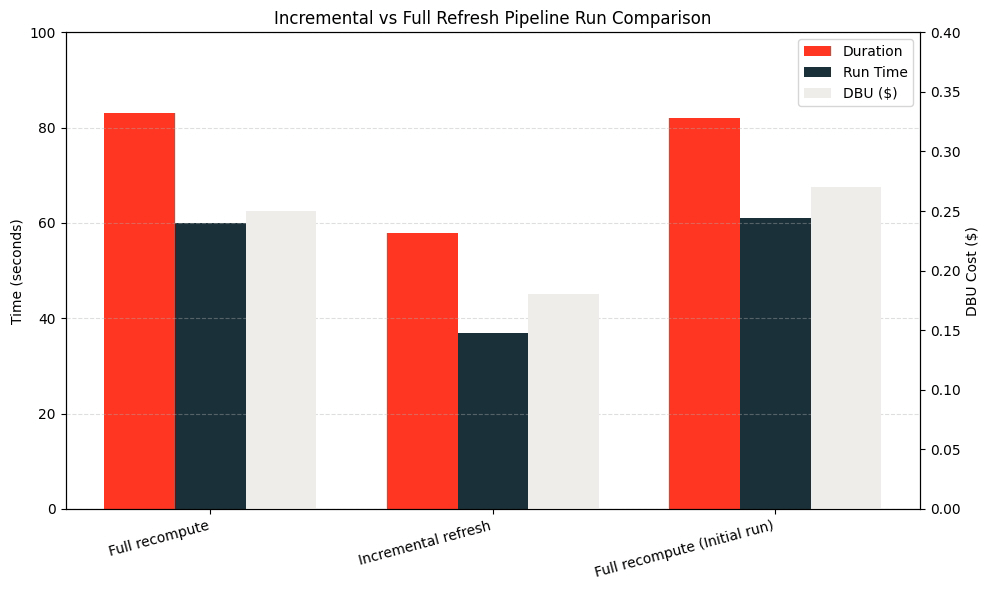
In most cases, the data ingestion is much larger than inserting 5 rows. To illustrate this, let's insert 1 billion rows into the initial load and then 10 million into each pipeline run.
Using dbldatagen to randomly generate data and the Databricks SDK to create and run an LDP, 1 billion rows were inserted into the source table, and the pipeline was run to generate the MV. Then, 10 million rows were added to the source data, and the MV was incrementally refreshed. Afterwards, the pipeline was force-refreshed to perform a full recompute.
Once the pipeline completes, use the list_pipeline_events and the billing system table, merged on dlt_update_id, to determine the cost per update.
As shown in the graph below, the incremental refresh was twice as fast and cheaper than the full refresh!
Operational Considerations
Strong monitoring, observability, and automation practices are crucial for fully realizing the benefits of incremental refreshes in declarative pipelines. The following section outlines how to leverage Databricks’ monitoring capabilities to track pipeline refreshes and cost.
Monitoring Pipeline Refreshes
Tools like the event log and the LDP UI interface provide visibility into pipeline execution patterns, helping detect when various refreshes occur.
We've included an accelerator tool to help teams track and analyze materialized view refresh behavior. This solution leverages AI/BI dashboards to provide visibility into refresh patterns. It uses the Databricks SDK to retrieve all pipelines in your configured workspace, gather event details for the pipelines, and then produce a dashboard similar to the one below.
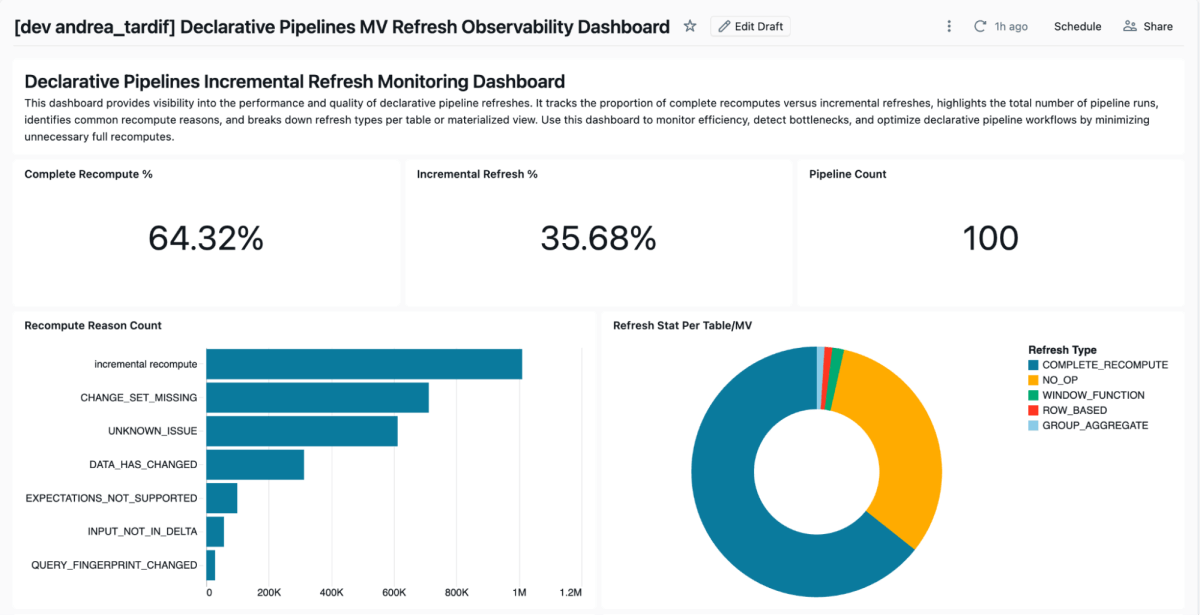
Github Link: monitoring-declarative-pipeline-refresh-behavior
Key Takeaways
Incrementalizing the material view refreshes allows Databricks to process only new or changed data in the source tables, improving performance and reducing costs.
With MVs, avoid using non-deterministic functions (i.e., CURRENT_DATE() and RANDOM()) and limit query complexity (i.e., excessive joins) to enable efficient incremental refreshes. Ignoring unexpected full recomputes on MVs that could be refactored to be incremental recomputes could lead to:
- Increased compute costs
- Slower data freshness for downstream applications
- Pipeline bottlenecks as data volumes scale
With serverless compute, LDPs leverage the built-in execution model, allowing Enzyme to perform an incremental or full recompute based on the overall pipeline computation cost.
Leverage the accelerator tool to monitor the behavior of all your pipelines in an AI/BI dashboard to detect unexpected full recomputes.
In conclusion, to create efficient materialized view refreshes, follow these best practices:
- Use deterministic logic where applicable.
- Refactor queries to avoid non-deterministic functions
- Simplify join logic
- Enable row tracking on the source tables
Next Steps & Additional Resources
Review your MV refresh types today!
Databricks Delivery Solutions Architects (DSAs) accelerate Data and AI initiatives across organizations. They provide architectural leadership, optimize platforms for cost and performance, enhance developer experience, and drive successful project execution. DSAs bridge the gap between initial deployment and production-grade solutions, working closely with various teams, including data engineering, technical leads, executives, and other stakeholders to ensure tailored solutions and faster time to value. To benefit from a custom execution plan, strategic guidance, and support throughout your data and AI journey from a DSA, please contact your Databricks Account Team.
Additional Resources
- Load and process data incrementally with Lakeflow Declarative Pipelines flows | Databricks Documentation
- Incremental refresh for materialized views | Databricks Documentation
Create an LDP and review MV incremental refresh types today!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.