The Simplification of AI Data
The Feature Store Evolved
by Mani Parkhe, Craig Wiley, Patrick Wendell and Matei Zaharia
Talk to any data science organization and they will almost unanimously tell you that the biggest challenge to building high quality AI models is accessing and managing the data. Over the years, practitioners have turned to a variety of different technologies and abstractions to help accelerate experimentation and development. In the past few years, Feature Stores have become an increasingly popular way for practitioners to organize and prepare their data for machine learning. In early 2022, Databricks made its Feature Store generally available. This summer, we are excited to introduce feature engineering and management as native capabilities in Databricks Unity Catalog. It marks a major evolution in how AI data can be more simply managed. This evolution unites feature management with a best in class data catalog simplifying and securing the process of creating features and using them to train and serve models.
Feature Engineering in Unity Catalog: a step towards centralizing ML data
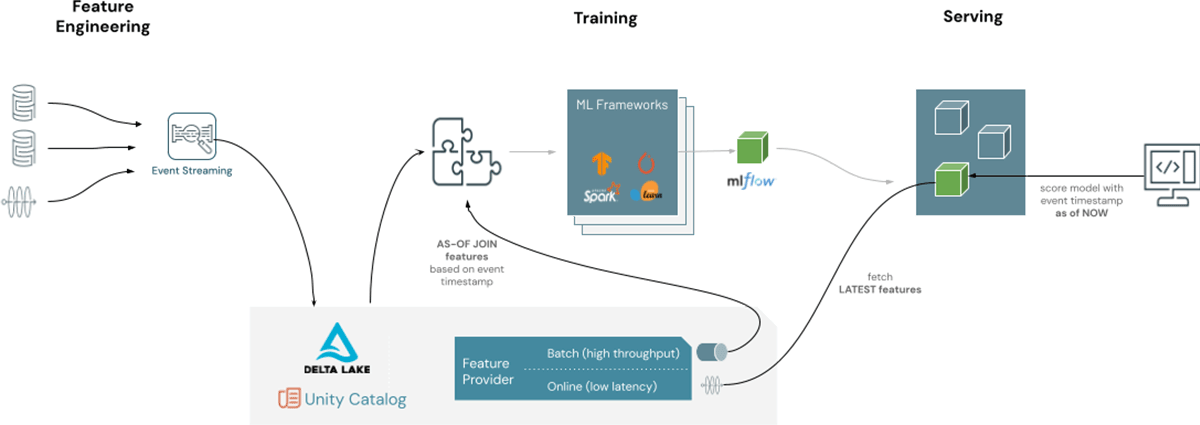
Feature Stores are a type of catalog designed to meet two primary requirements, they must facilitate the easy discovery and usage of ML data and they must make that stable high quality data easily available to high performance model training and serving systems. Feature Stores enable data scientists to easily discover new features available in their organization, add new features, and effortlessly use them directly in their ML applications.
The Unity Catalog provides centralized access control, sharing, auditing, lineage, and data discovery capabilities across your Lakehouse and your Databricks workspaces. As we worked with Feature Store customers, they would time and again ask for Unity Catalog capabilities such as sharing and governance of their features. It became increasingly clear … "Why have these two separate catalogs: one for your features and one for everything else?"
Once we started to implement the unified Features in Unity Catalog experience, it became evident just how impactful this evolution of the feature store would be on many aspects of the AI development workflow.
Your best Feature Store is a Lakehouse
Feature Engineering in Unity Catalog simplifies the training and deployment of models by building feature store capabilities directly into the Unity Catalog, the catalog that manages the Lakehouse.
- Simplify discovery of features: Unity Catalog is a one stop shop to discover all Lakehouse entities: tables and features, models, functions, and more. No longer do we have multiple discovery systems for the same data.
- Enables governing and sharing features: Unity Catalog provides unified enterprise-level governance of all entities (tables, functions, models), as well as the tools, like row- and column-level security and policies, for teams to easily share features across workspaces assuming governance permits. As Unity Catalog evolves by adding richer governance and security capabilities, your features will get those automatically.
- No data-copy: You can use the same table as a source of features for ML and in other data applications and BI dashboards. Since Delta is built to natively support these different applications, data does not need to be copied over or independently cached for different applications. Your AI data never goes out of sync.
- Built-in lineage graph helps navigate the relationship between entities: This helps customers ensure they are training/serving on the right data and enables debugging errors and change in model performance by tracking back from models to features using a single unified graph.
Any table with primary keys can be used as features to train and serve models
Organizations typically want to standardize on a single ELT framework for all data engineering pipelines in order to maintain consistency and ensure enterprise policies are applied to all datasets in the Lakehouse. Merging the feature engineering capabilities into Unity Catalog enables organizations to use the same standardized ELT framework to write and maintain feature engineering pipelines.
To simplify the process of creating new features in Unity Catalog, we upgraded the SQL syntax to support TIMESERIES clause as part of the PRIMARY KEY constraint. This enables applications that automatically use features for training and scoring models, to perform appropriate point-in-time joins [AWS][Azure][GCP]
Customers may have existing feature tables created using a home grown feature store implementation, open source libraries, or vendor DSLs. By adding the PRIMARY KEY constraint on these Delta tables they use these features directly to train and serve ML models.
Automatic lineage tracking eliminates training/serving skew
MLflow models trained on Databricks using features automatically capture the lineage to the features used in model training. This lineage is stored as a feature_spec.yaml artifact within the model. This addresses a pain-point that the users do not need to independently maintain a mapping of models and features. Inference systems can use this specification and feature metadata for model scoring. Additionally, this information can be used for lineage graphing systems to show all the features required for a model and forward links from a feature to all the models that use it.
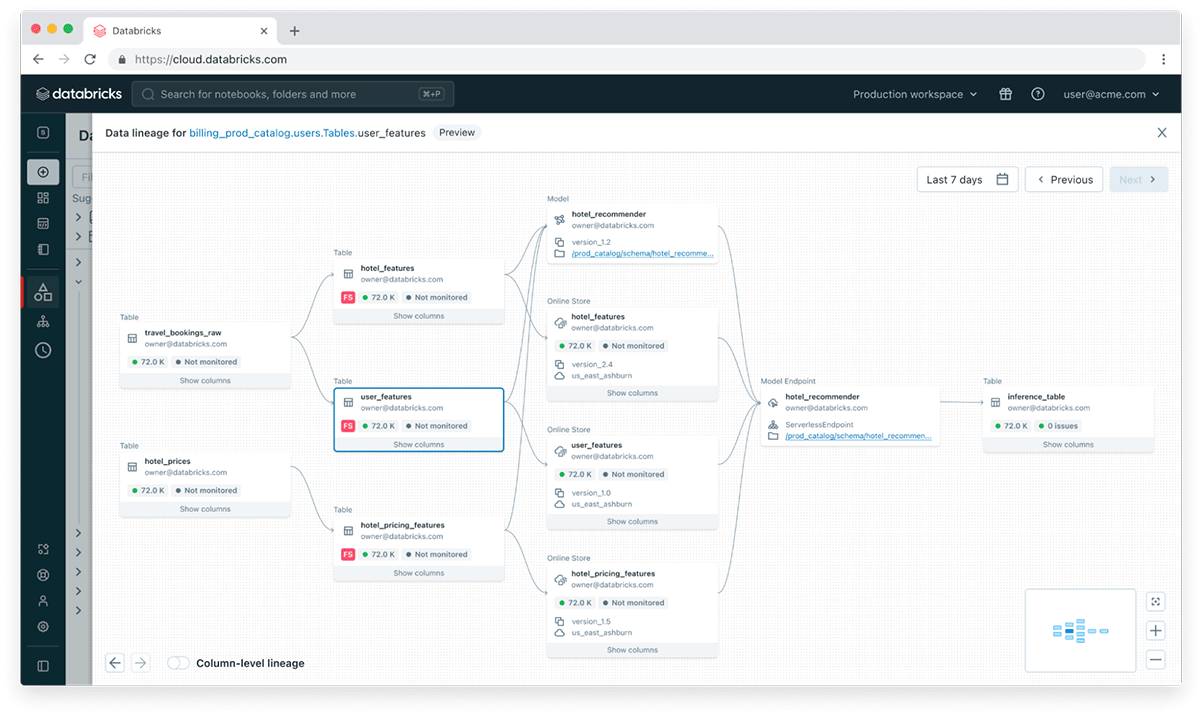
Features are auto-served to models
When models are deployed in Databricks Model Serving, the system uses lineage to track the features required for inference and uses the appropriate online table in the Lakehouse to serve features. This simplifies the code an MLOps engineer needs to write for model scoring. They only need to call the model serving endpoint with the necessary IDs and features are automatically looked up. Furthermore since models, features, and other data assets in the Unity Catalog, all access to these assets follow the same enterprise governance.
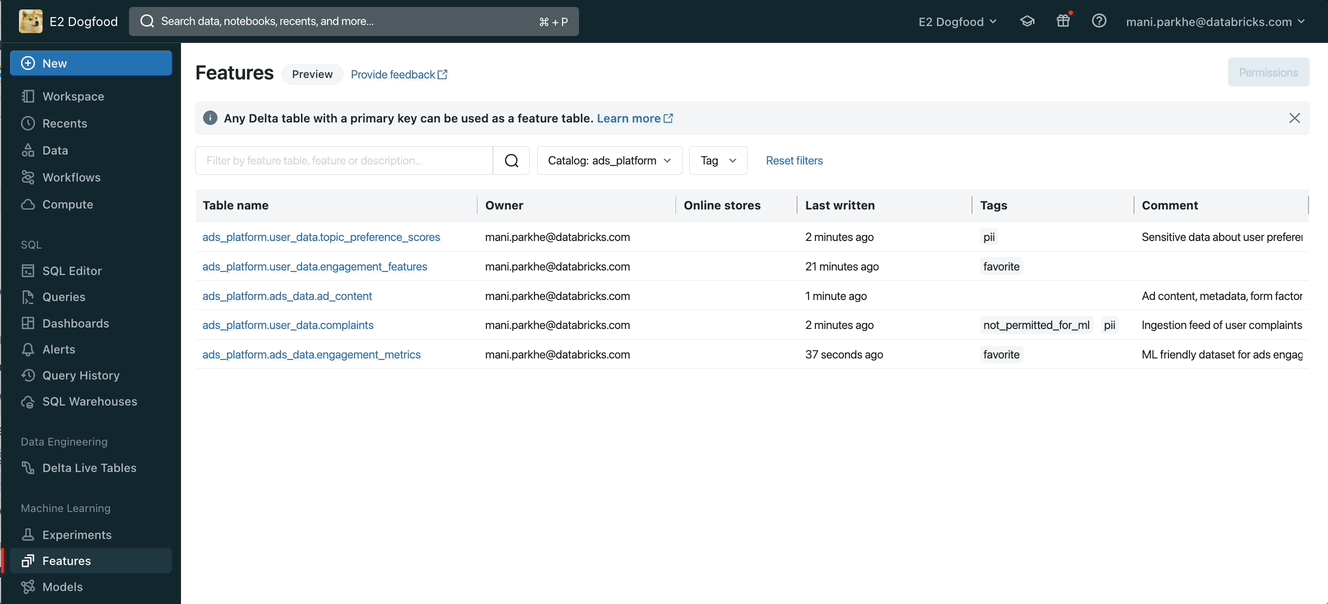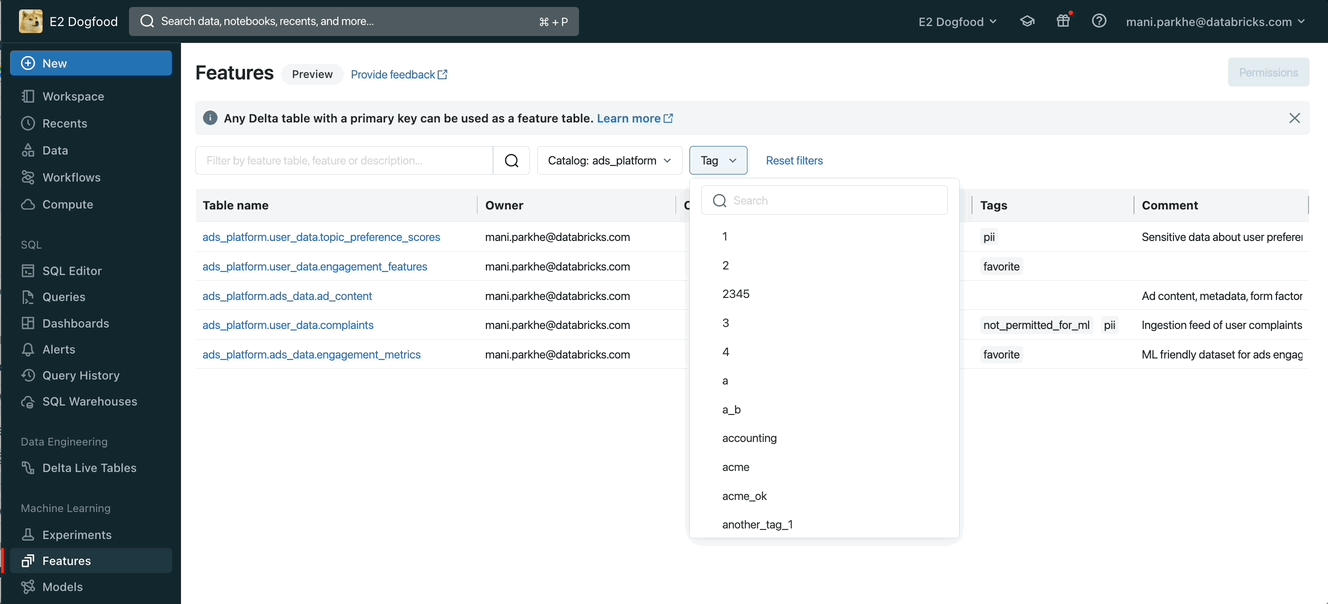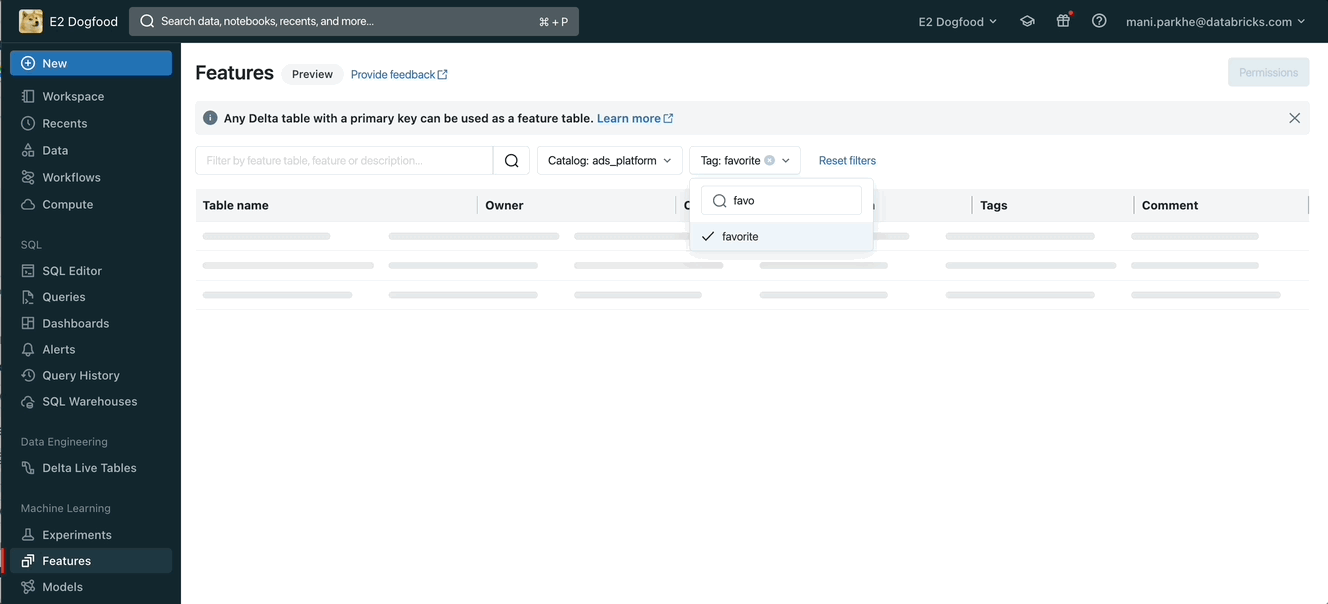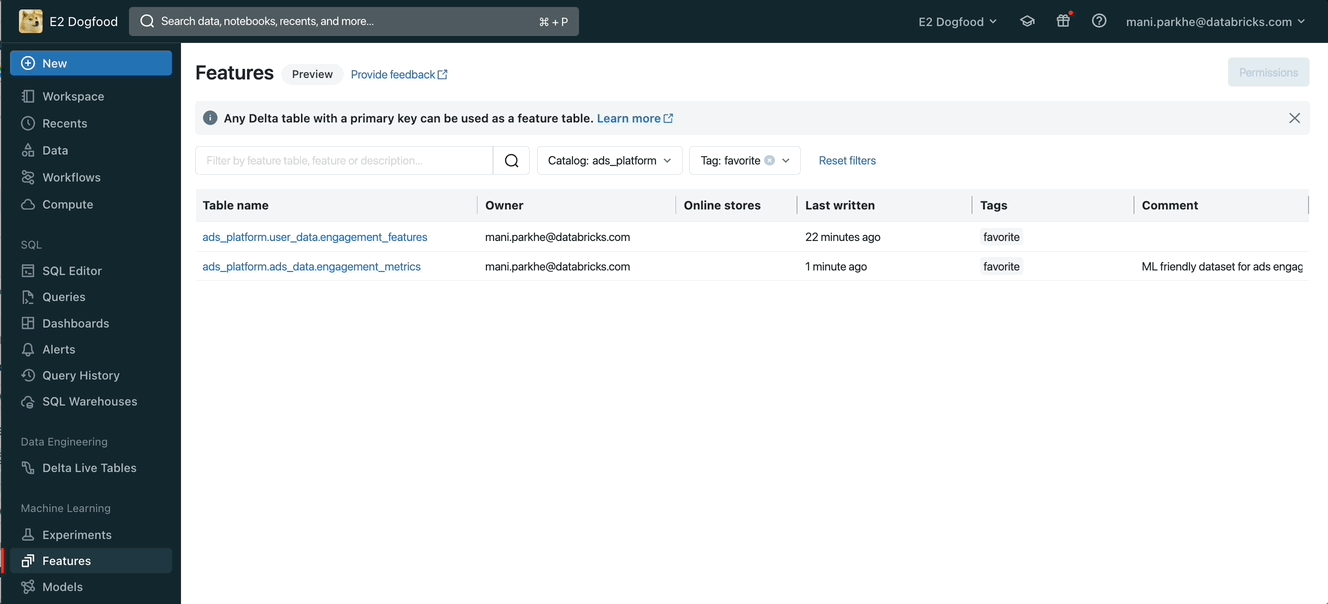
Curate and discover features using tags
Data Scientists can find all the features created using Databricks Feature Store APIs or other ELT frameworks and SDKs. You can select a specific catalog from Unity Catalog to list all Delta tables with primary keys. However, user tags simplify this curation and discovery journey and address various use cases like
- Users want to create curated sets for ML Data tables they are frequently used.
- Data Scientists want to create a personal collection of favorite features and tables.
- Teams want to create curated sets of features that are considered to be high quality for ML use cases.
Unity Catalog discovery tags can be applied across catalogs and schemas. Users can apply these tags for different entities like tables, views, models, functions.. etc. Additional guidelines to explore user tags in Unity Catalog are available for AWS, Azure, and GCP.
Getting started with Feature Engineering in the Unity Catalog
You can discover new features in the Lakehouse by clicking on the Features button under Machine Learning in the left navigation. By selecting a catalog you can see all the existing tables you can use as features to train ML models.
To get started, following the Feature Engineering in Unity Catalog documentation available info AWS, Azure, and GCP. You can get started with this end-to-end notebook.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.