Training Stable Diffusion from Scratch for <$50k with MosaicML (Part 2)
by Mihir Patel, Cory Stephenson, Landan Seguin, Austin Jacobson and Erica Ji Yuen
We've replicated Stable Diffusion 2 for less than $50k, and we've open-sourced the training code so you can too! This is a 3x cost reduction from our last blog post and an 8x reduction from the original Stable Diffusion 2, making training large-scale diffusion models from scratch more accessible than ever before.
Using MosaicML has been fantastic for training diffusion models. Huge improvement over the tools I've used in the past." - Tony Francis, CEO, Dream3D
We're back! A few months ago we showed how the MosaicML platform makes it simple—and cheap—to train a large-scale diffusion model from scratch. Today, we are excited to show the results of our own training run: under $50k to train Stable Diffusion 2 base1 from scratch in 7.45 days using the MosaicML platform.

Training your own image generation model on your own data is now easy and accessible. By training your own diffusion models, you can:
- Use your proprietary data
- Tune the representations for certain art or photography styles
- Avoid violating intellectual property laws so your models can be used commercially
We've open-sourced our code and methods to train a diffusion model from scratch so that you can train your own; check it out here! If you're interested in training your own models, contact us for a demo, and read on to learn more about our engineering setup!
Setup

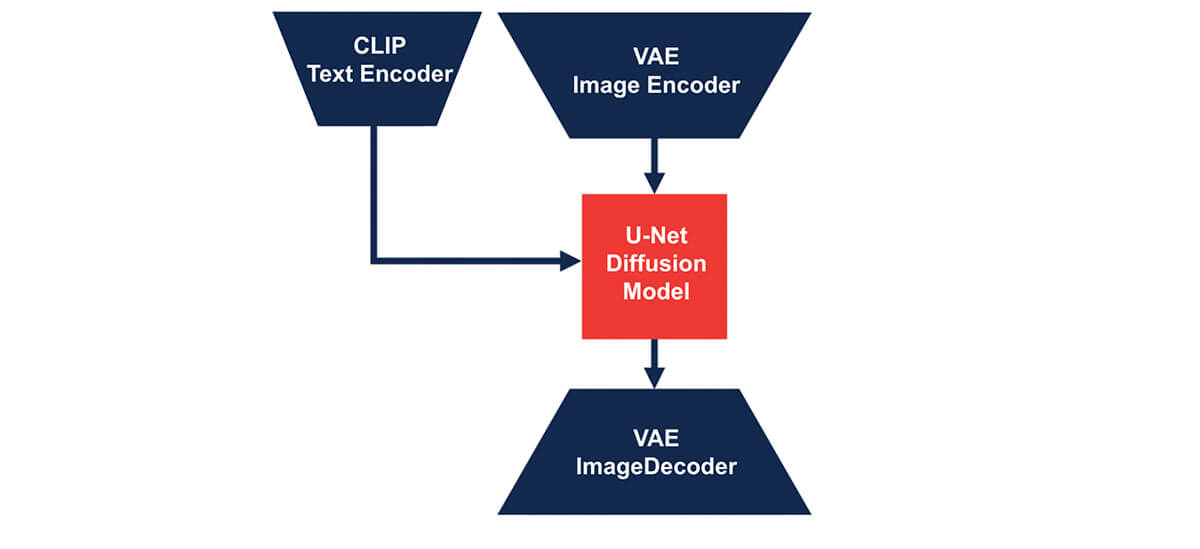
Model: Our diffusion model is a ComposerModel composed of a Variational Autoencoder (VAE), a CLIP model, a U-Net, and a diffusion noise scheduler, all from the HuggingFace's Diffusers library. All of the model configurations were based on stabilityai/stable-diffusion-2-base.
Data: We trained on a subset of LAION-5B that includes samples with English-only captions and an aesthetic score of 4.5+. Similar to Stable Diffusion 2 base, we did two phases of training based on the image resolution of the training data. For the first phase of training, we used all images with resolution >=256x256, amounting to 790 million image-caption samples. For the second phase of training, we only used images with resolution >=512x512, amounting to 300 million image-caption samples.
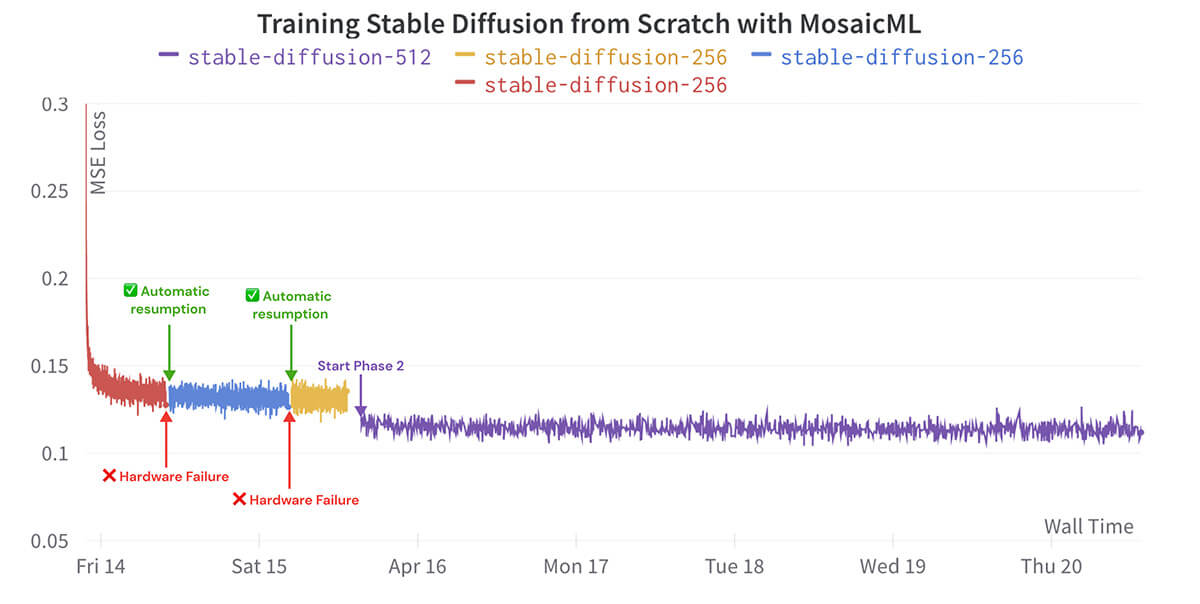
Compute: Both phases of training ran on 128 NVIDIA A100 GPUs. The first training phase was run for 550k iterations in 1.6 days while the second phase was run for 850k iterations in 4.9 days, for a total of 20,051 A100 hours for training. In addition to the training time, we pre-computed the latents for the VAE and CLIP model to reduce training time and cost when making multiple passes over the dataset. Pre-computing the latents required an additional 3,784 A100 hours, resulting in 23,835 A100 hours in total. Assuming a cost of $2 / A100 hour, the total price tag is $47.7k.
Tech Stack: We used Composer for our training framework, StreamingDataset to load our 100TB of data, and the MosaicML platform for overcoming infrastructure challenges when training and evaluating on 128 GPUs.
Challenges and Solutions
Whether for diffusion models or large language models, training at scale has significant challenges. We trained our diffusion model using the MosaicML platform, which addresses these challenges automatically so you can focus on training the best possible model. Below are three main challenges with large-scale training and how our platform solves them.
Infrastructure
Training large models on large datasets requires significant compute. The MosaicML platform effortlessly orchestrates hundreds of GPUs on any cloud provider. For example, our primary training run took place on a cluster of 128 A100 GPUs. To ensure evaluating the model didn't slow training, we automatically kicked off evaluation runs at every checkpoint on different clusters using different cloud providers, seamlessly scaling up to 64 GPUs and back down to 8 GPUs depending on availability.
Even after training is underway, software or hardware failures can halt training, leaving GPUs idle until someone notices or requiring someone on-call 24/7 to babysit the run. Thankfully, the Node Doctor and Watchdog features of the MosaicML platform automatically detect failed nodes and resume jobs as needed. With auto-resumption, we recover from failures and continue training with zero human intervention, avoiding expensive downtime and human babysitting. Just launch and train!
Efficient software
Software is difficult to configure optimally. Our PyTorch-based Composer library maximizes training efficiency at scale. As shown in our previous blog post, Composer demonstrated excellent throughput scaling as the number of GPUs increased. For this update, we added further optimizations (Low Precision GroupNorm and Low Precision LayerNorm, Fully Sharded Data Parallel) to achieve near-perfect strong scaling up to 128 GPUs, bringing the cost down to $50k. We also used Composer's native Exponential Moving Average (EMA) algorithm, which allowed us to start EMA close to the end of training (iteration 800k of the final phase) to gain all the benefits of EMA while saving on memory and compute for the majority of training.
Managing 100TB of Data
We trained with a subset of LAION-5B that contained 790 million samples, amounting to >100TB of data. The sheer size of the dataset makes it difficult to manage, especially when working with multiple clusters with separate local storage. The MosaicML StreamingDataset library makes working with massive datasets much simpler and faster. There were three key features of the StreamingDataset library that were especially useful for this training run:
- Mixing datasets stored in different locations. We bucketed samples based on image resolution into different datasets. At training time, we used the MosaicML StreamingDataset library to train on a mixture of resolutions from these datasets.
- Instant mid-epoch resumption. We were able to instantly resume training in the middle of an epoch. This saved hours by avoiding the need to iterate over the entire dataset to get back to where we left off.
- Elastic determinism. The MosaicML StreamingDataset library deterministically shuffles data, even when changing the number of GPUs used for training. This made it possible for us to exactly reproduce training runs, dramatically simplifying debugging.
Human Evaluation Results
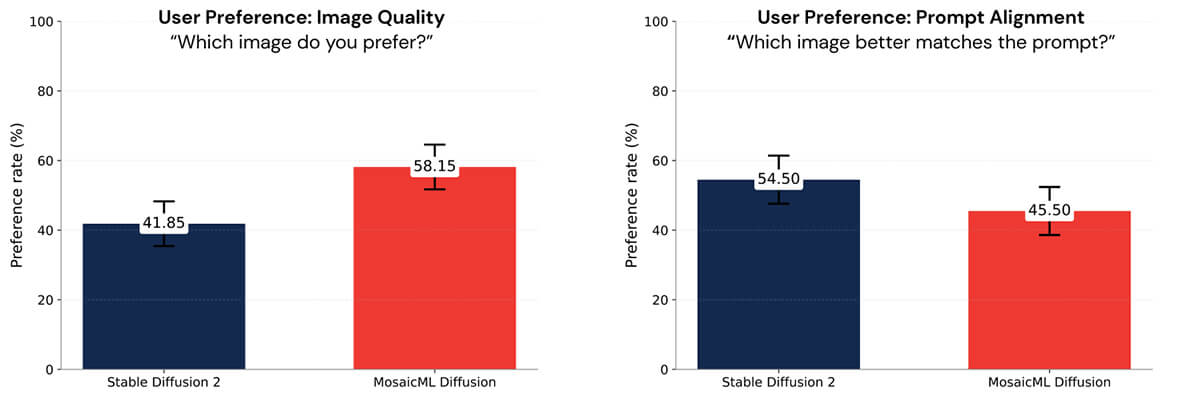
Evaluating image generation models is difficult, and there is no substitute for human evaluation. In a blind human evaluation, we measured user preferences in image quality and prompt alignment between Stable Diffusion 2 and our diffusion model. Based on user preferences, we concluded that the two models were comparable in quality (see Figure 5) All images were generated based on prompts from the Drawbench benchmark proposed in the Imagen paper. For more details, see our follow-up blog post coming soon.
What's Next?
This blog post illustrated model outputs and loss curves, described high-level model training details, and highlighted challenges of large-scale training that we avoided thanks to the MosaicML platform. Unfortunately, as much as we believe in transparency, we have chosen not to release model weights at this time due to the legal ambiguity surrounding image generation models trained on LAION-5B. This is a key reason why the ability to train image generation models on your data is so vital.
In the next few days, we will release a follow-up blog post that includes the full technical details on this effort. If you're looking to train your own diffusion model using the same tools we did, sign up for a demo of the MosaicML platform or reach out to us on our Community Slack! And if you want to keep up with the latest news from MosaicML, follow us on Twitter
Appendix
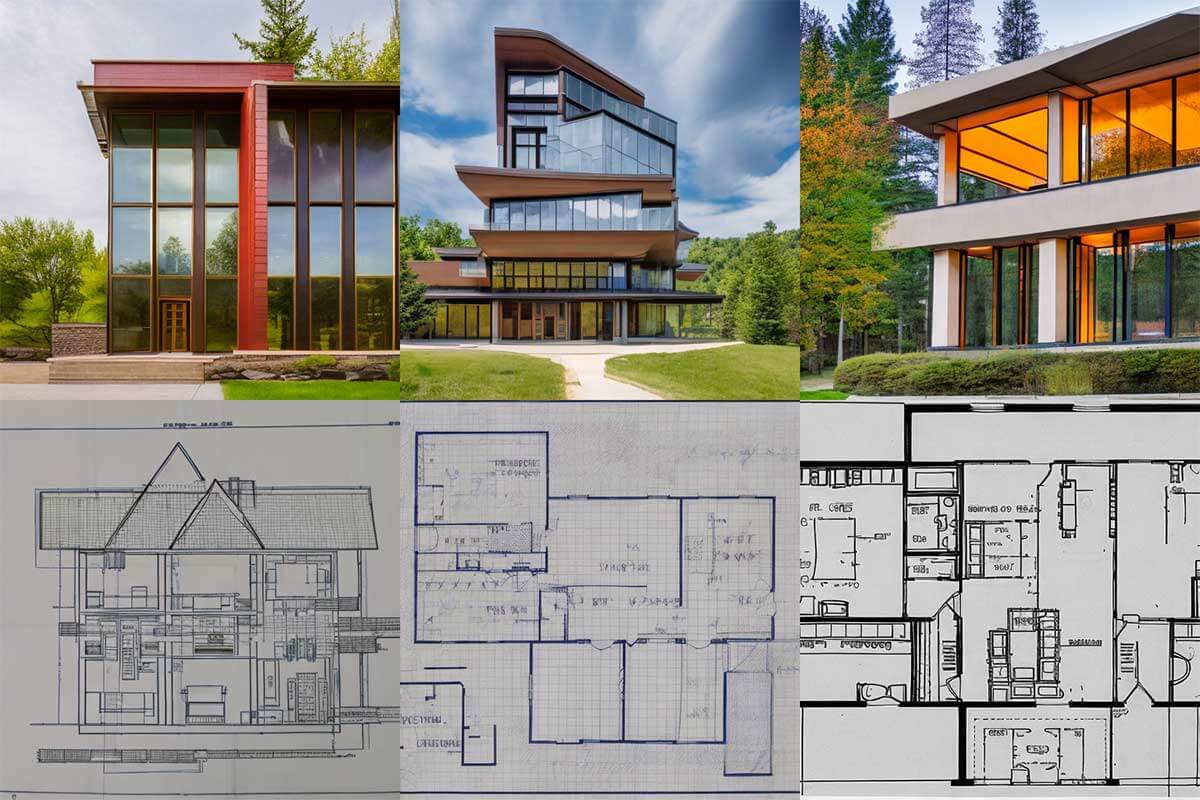
More image generation fun with our diffusion model. Our team had a blast getting creative with different subjects and styles!











Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.