Supercharging AI Model Building: Data and Task Parallelism with Ray and Databricks
How combining Ray and Databricks Spark enabled Pilot Company to build forecasting models faster and more efficiently.
- Learn how combining Spark’s data parallelism and Ray’s task parallelism dramatically accelerates machine learning (ML) training and tuning, cutting compute costs and cycle times.
- Explore a real-world retail sales forecasting case store models tuned 8x faster thanks to Ray on Databricks.
- See how Databricks lakehouse architecture, Unity Catalog and MLflow support scalable end-to-end pipelines for retail and enterprise AI teams.
Optimal Infrastructure, Maximum Impact: Why Parallelism Matters for AI in Retail
Accurate sales forecasts enhance customer satisfaction across all industries, including the travel and retail sectors. Pilot Company operates more than 900 locations, with business operations that depend on fast and reliable predictions to serve our guests. Legacy bottlenecks — such as underutilized compute and lengthy model cycles — could lead to outdated forecasts, which may negatively impact our guest experience.
Pilot Company needed an AI pipeline that empowered frequent, granular forecasting — without escalating infrastructure spend. Traditional batch or manual retraining methods could not keep up.
To address these challenges, Pilot Company leveraged:
- Databricks Spark clusters (Runtime 16.4) for Extract, Transform, Load (ETL), big data prep and partitioning
- Lakehouse architecture for unified, governed storage and seamless access
- Databricks Unity Catalog for secure team data sharing
- Managed MLflow for experiment tracking and reproducibility
Layering in Ray for task parallelism on top of Spark’s data parallelism enables Pilot Company to streamline end-to-end model building. Models now retrain as soon as new data becomes available, translating infrastructure efficiency into tangible business benefits.
Parallelism in Action: From Data Prep to Model Tuning
Building a high-accuracy forecasting model for retail sales involves several steps:
- Data Collection and Preparation: Gathering and cleansing large-scale, multi-source sales data.
- Feature Engineering: Transforming and extracting new predictors that improve model performance.
- Model Training: Adjusting parameters and minimizing loss functions for the best fit.
- Model Validation and Tuning: Evaluating accuracy, adjusting hyperparameters and selecting the best models.
- Deployment and Evaluation: Final effectiveness checks before going live.
- Spark excels at big data tasks — steps 1 and 2 — using data parallelism. Massive datasets are split into partitions, processed concurrently and efficiently managed across a cluster.
- Steps 3-6 (training, tuning and evaluation) benefit from task parallelism. Here, the challenge is to maximize utilization for compute-intensive, long-running processes — enter Ray.
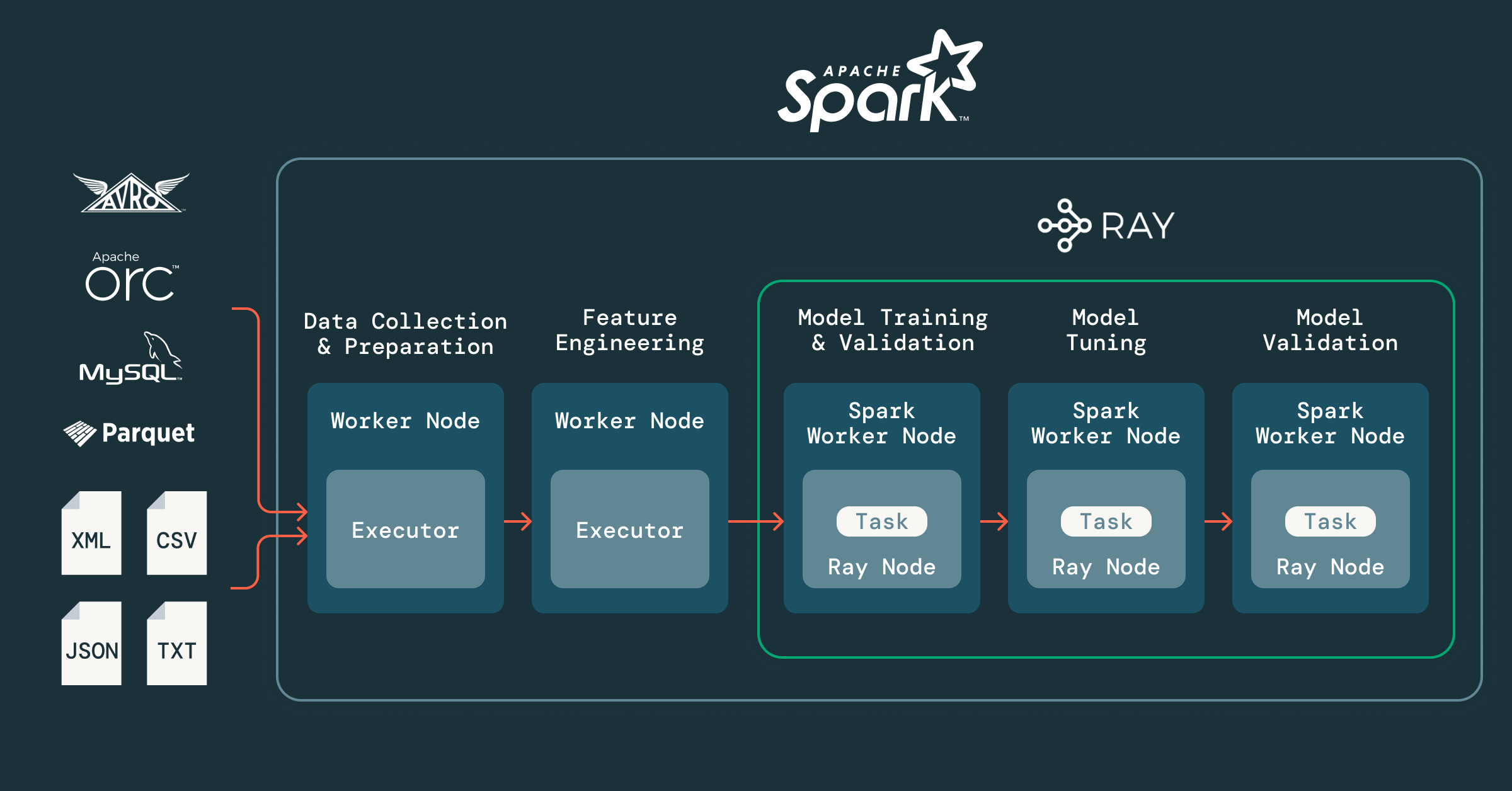
Data Parallelism with Spark
In Spark, data is divided into partitions. Each executor processes these in parallel using higher-order and lambda functions (e.g., map, filter) across RDDs or DataFrames. This allows seamless scaling for ETL, batch processes and feature engineering, slashing time for data prep and transformation.
Task Parallelism with Ray — On Top of Databricks
Ray enables thousands of model training or hyperparameter tuning jobs to run simultaneously, assigning optimal CPU or GPU fractions per task — maximizing cluster utilization. For example, Ray can fine-tune more than 1,400 time series models at once across a 52-core cluster, matching compute supply to job demand.
Integration with Databricks enables in-memory transfer via Apache Arrow, shifting from Spark’s data environment into Ray-driven ML tasks with zero I/O bottlenecks.
Task parallelism is crucial in model training and tuning, particularly when optimizing thousands of individual models — such as forecasting demand for every item at every store across an entire retail network. Ray excels at this layer, orchestrating workloads so that each model training or hyperparameter optimization task runs independently and simultaneously.
What sets Ray apart is its resource efficiency: not only can it manage thousands of concurrent tasks, but it dynamically allocates the right amount of compute resources — assigning specific numbers or even fractional shares of CPU and GPU cores to each task based on complexity. For example, Ray can assign as little as 0.25, 0.5, or 1 full CPU core (or combinations like 1 CPU and 0.5 GPU) to different jobs, maximizing overall cluster utilization.
In our benchmark, this fine-grained parallelism enabled us to train and tune more than 1,400 time series models concurrently across a 52-core cluster, resulting in a reduction of total processing time from nearly 3 hours (using only Spark) to under 30 minutes with Ray on Databricks. This not only means engineers can do more, faster, but it also ensures that every ounce of available hardware is fully leveraged for business value.
Key benefit: Ray’s integration with Databricks enables in-memory data transfer with Apache Arrow, allowing ML workloads to switch from Spark’s data prep environment directly into Ray-powered experiments — without cumbersome file I/O.
Real-World Benchmark: Retail Sales Forecasting
Scenario
- Objective: Tune more than 1,400 individual time series forecasting models (one per product-store location) for retail sales.
- Task: Hyperparameter optimization using Optuna with a rich, multi-dimensional search space.
Baseline: Spark Only (Cluster 1)
- 6 worker nodes, eight cores each, 61 GB RAM.
- Models run sequentially across worker nodes; only six can be processed at a time.
- Total execution time: ~2 hours 47 minutes.
- CPU utilization: Only 20–25%.
Accelerated: Ray-on-Spark (Cluster 2)
- Same hardware stack, with a Ray cluster added (4 CPUs per Ray worker).
- 52 concurrent tasks managed by Ray (6x8+4).
- Total execution time: Only 28 minutes 12 seconds — a nearly 8x improvement!
- CPU utilization: 90–95% (much closer to full potential).
Business Impact:
This parallelized approach not only accelerated forecasting for our retail operations, but it will also transform the way Pilot Company’s supply chain, merchandising and marketing teams use insights to support our purpose of showing people they matter at every turn. By reducing the time required for training and tuning forecasting models from hours to minutes, models can be retrained much more frequently. This increased frequency enables predictions to reflect real-time sales trends, seasonality and changing consumer preferences — capturing “ground reality” far better than slower, batch-based approaches.
As a result, inventory planning will be more accurate, allowing stores to stock precisely what they need. For category managers, the speed to actionable insight will enable tighter alignment between demand forecasts and procurement decisions.
Most importantly, the marketing and merchandising teams will be empowered to respond rapidly with data-driven promotional campaigns, launching offers at the most opportune moments, showing people they matter at every turn. This closed feedback loop — where models are continually improved based on the latest store-level data — positions the business to remain agile and guest-obsessed in a rapidly changing retail environment.
Technical Deep Dive: How It Works
- Spark partitions and preps the sales data, readying features for model consumption.
- Ray orchestrates and parallelizes hyperparameter tuning and model training. Each Ray worker node handles multiple models — or splits large datasets for distributed training when needed.
- Data moves seamlessly between Spark and Ray thanks to Databricks’ Arrow-based memory integration, which avoids slow disk writes and storage bottlenecks.
A simple code example:
- Define a search space in Optuna.
- Use Ray’s tune library for parallel, distributed model training and hyperparameter search.
- Log and monitor utilization to ensure hardware is fully tapped for business value.
When to Use Spark, Ray… or Both?
- Spark: Ideal for ETL, massive data processing, streaming/batch workflows and feature engineering.
- Ray: Best for hyperparameter tuning, deep learning, reinforcement learning, and high-performance compute tasks.
- Combined: Use Spark + Ray for end-to-end AI pipelines: prep/feature engineering with Spark, training/tuning/experimentation with Ray — all with minimal friction.
Transforming Model Training: Where to Go from Here
The combination of data parallelism with Spark and task parallelism with Ray — mainly when run on a unified Databricks stack — allows AI/ML teams to break through legacy bottlenecks. Execution times plummet, compute utilization soars, and enterprise deployments become much more cost-effective.
Adding Ray to your Databricks Spark clusters can deliver a model reduction build time for large-scale ML tasks — enabling organizations to forecast, plan and compete with new speed and accuracy.
Redefine what’s possible with Databricks Data Intelligence Platform. Learn more today.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.