To Tailgate or Not? How Databricks + AccuWeather used ML to answer every football fan's burning question
by Kunal Marwah, Timothy Loftus, Mikaila Garfinkel and David Kulwin
Whether you’re an NFL fanatic, an alumnus rooting for your alma mater or a super fan just trying to catch a glimpse of Taylor Swift, football season is one of the most exciting times of the year in the U.S.
And there’s no shortage of ways to enjoy it. While millions of viewers will watch from the comfort of their couches or neighborhood bar, many others will trek to the stadium, sometimes in sub-zero temperatures, to see their favorite teams play – and, of course, tailgate in the parking lot ahead of the game with other fans. Others may even want to hit the road with the team and travel to a new city. But given fans have a whole season of games to pick from, they need help whittling down which ones to choose.
In the spirit of Databricks solving our customers’ “toughest problems,” we wanted to tap into the power of data and machine learning to help NFL and college football fans predict how they can get the most bang from their tailgating bucks.
In this blog post, we’ll walk through how we used the Databricks Lakehouse Platform – including Databricks AutoML and Databricks Assistant – with data from our Databricks Marketplace partner AccuWeather (who knows a thing or two about tailgating, being based in Stage College, PA – home of the Penn State Nittany Lions) to answer the question: Where are the best places to tailgate the rest of this season?
What we found
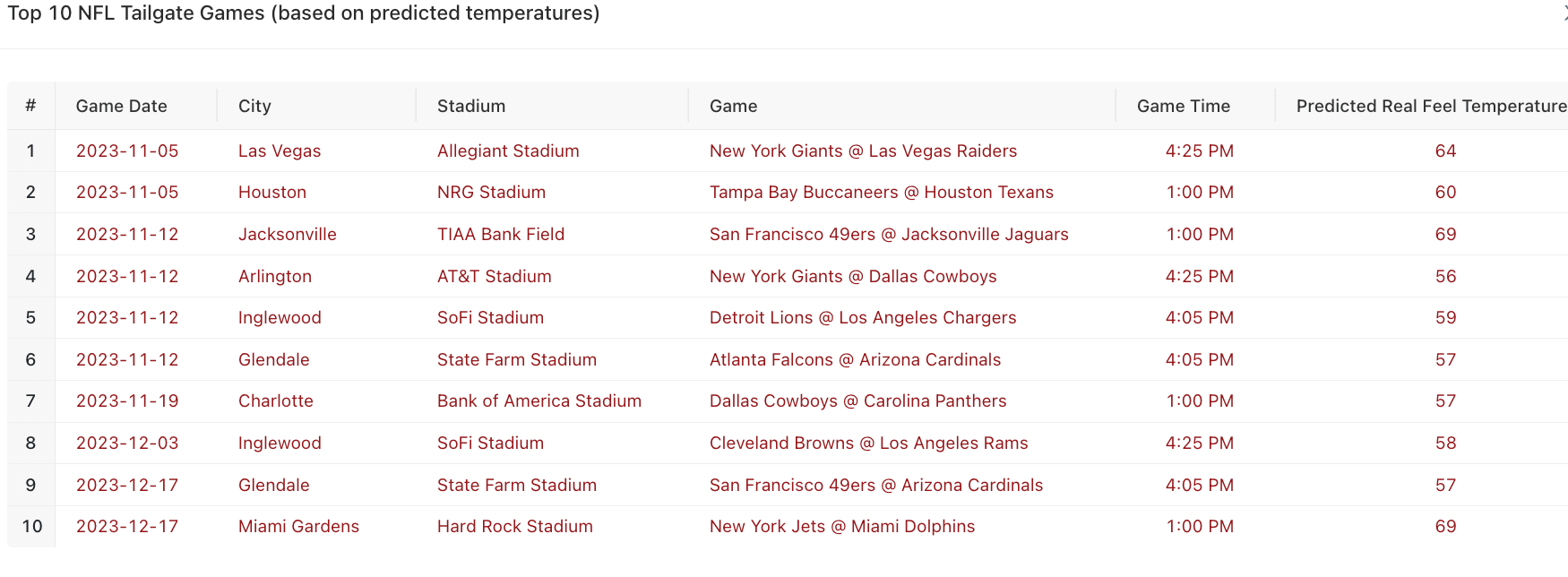
From November through December 2023, our model pin-pointed 23 NFL games out of the 117 total that were projected to have exemplary tailgating conditions. We are able to visualize these results using Databricks’ brand new dashboarding tool, called Lakeview.
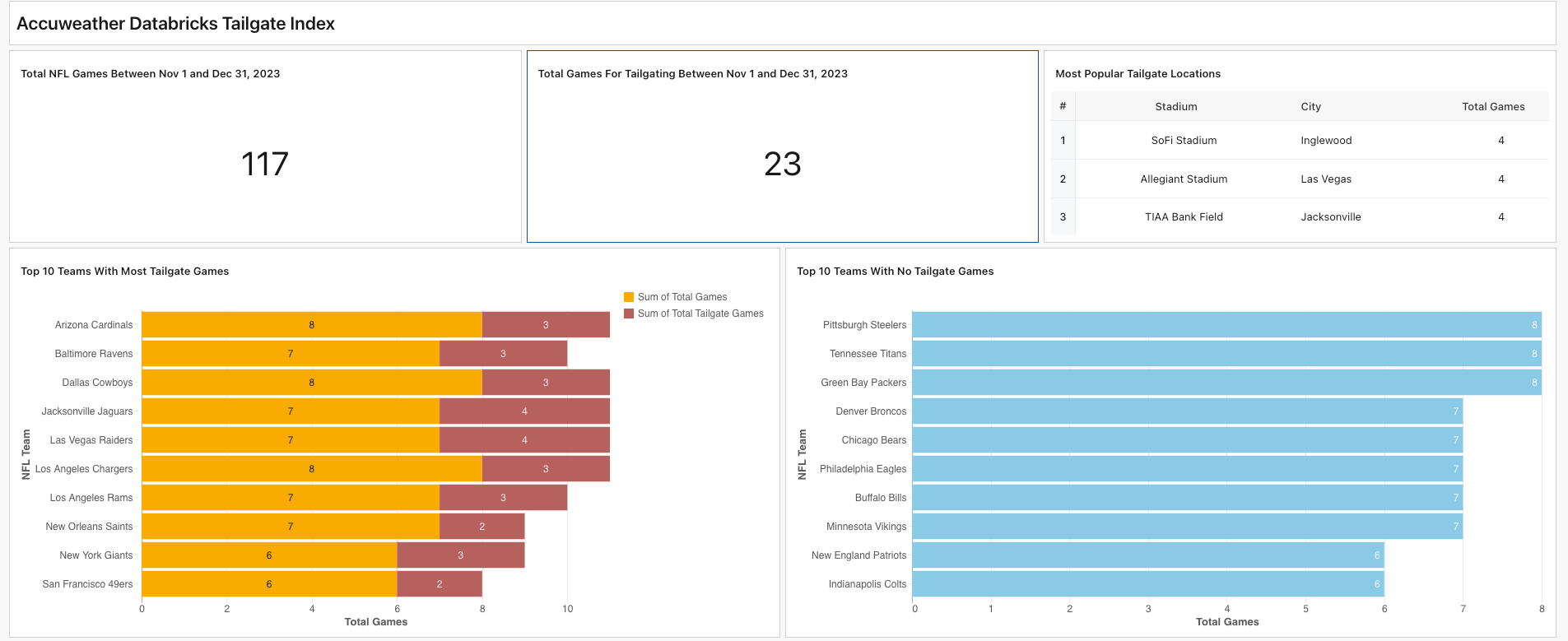
The stadiums with the most “tailgate-able” games were SoFi Stadium in Inglewood, CA, Allegiant Stadium in Las Vegas, NV, and TIAA Bank Field in Jacksonville, FL.
Similar to the stadiums, it’s not too surprising that teams located in warmer locations are projected to have the most ideal weather for their games: the Arizona Cardinals, the Dallas Cowboys, the Jacksonville Jaguars and Las Vegas Raiders.
Conversely, fans of the teams with the fewest tailgate-able games should get their heavy winter coats out of storage now – if they haven’t already: the Pittsburgh Steelers, the Tennessee Titans, the Green Bay Packers, the Denver Broncos and the Chicago Bears. As we’ve seen before, that’s unlikely to stop many of the devoted fans from trekking, possibly in subzero temperatures, to the respective stadiums to tailgate. And that’s even with the rough start to the season that many of those teams are having.
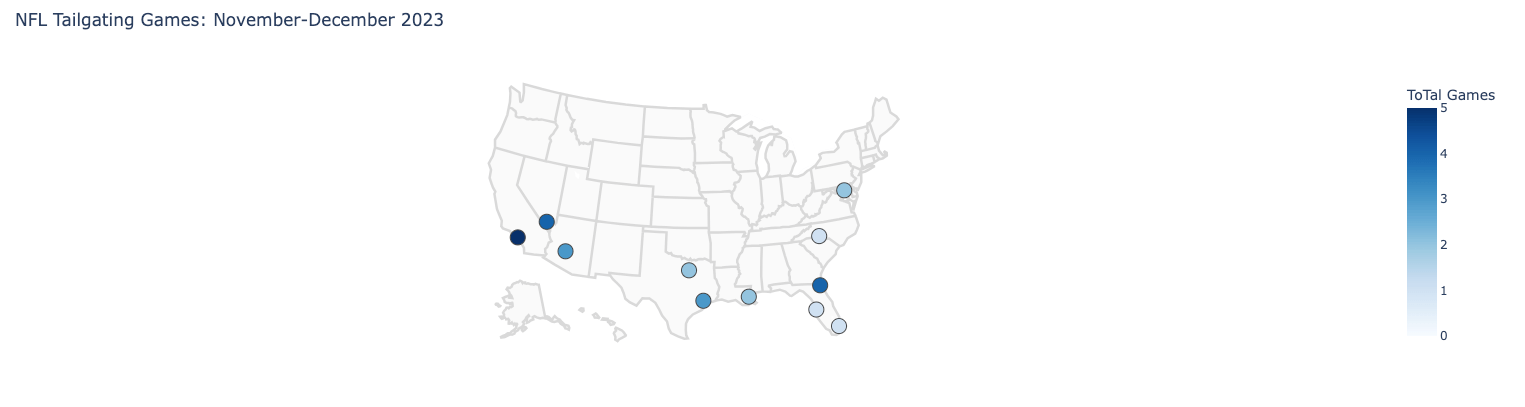
There were a few surprises. Both the New York Giants/Jets and the Baltimore Ravens – not necessarily teams from cities known for their perfect weather conditions in November and December – made it into the top ten teams with the most “tailgate-able” games.
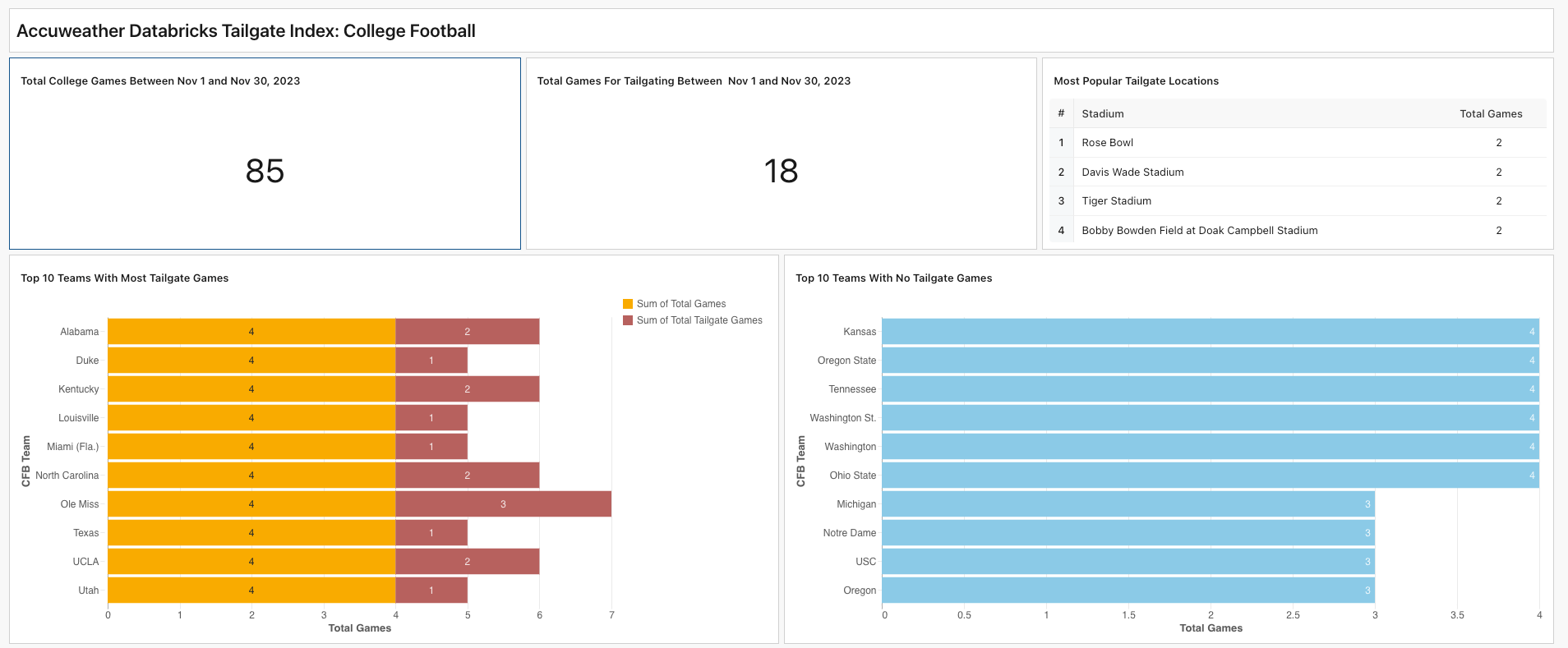
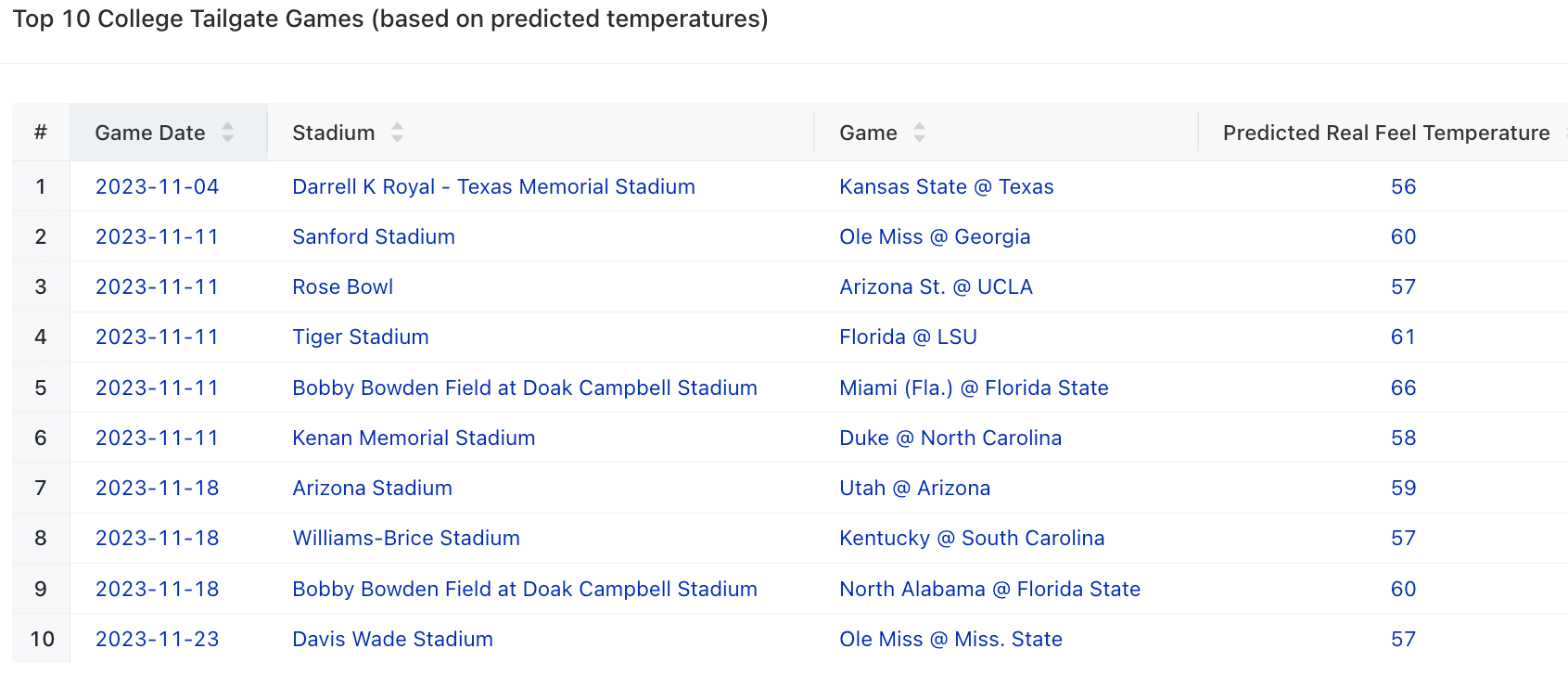
Meanwhile, over the next few weeks, there are 18 college football games that would likely prove to be attractive tailgating options. The top 10 teams with the most “tailgate-able” games include Alabama, Duke, Kentucky, Louisville and Miami. Conversely, the college teams whose fans should start stocking up on hot chocolate now include Kansas, Oregon State, Tennessee and Washington St.
Why this matters
We get it, few enterprises are going to need to know mission-critical tailgating information. But what if you did need to know when to stock snow shovels, or when people were most likely to purchase anti-frizz hair care products? As we show with this use case, when it comes to AI and ML, the end application is only as good as the data and process behind it.
Without gathering the right data, building the proper model, training it and verifying the results, there is no way to be sure the model is actually performing as intended. By standardizing that process on a single, unified data platform, businesses can start to reap the benefits of AI and ML much faster and with greater confidence in the outcomes.
What we will highlight below is the step-by-step process that we used to build the Tailgate Index. But it is easily repeatable for other use cases. For example, replace weather information with regional sales data – like the customer size, location, industry, etc. – and the business development team suddenly has a chatbot that it can use when evaluating potential new clients. Instead of querying the machine for the best tailgate, salespeople could ask questions like: Within this region, which businesses are likely to buy my product? Organizations can use weather data and ML to predict business-critical outcomes; for instance, a major coffee chain may choose to launch its pumpkin spice latte based on colder-than-expected weather predictions.
Most importantly, Databricks helps to unlock the potential of data for everyone in the business. With tools like MLflow, it’s now possible for those without data science backgrounds to build simpler models – like classification, regression, and forecasting models. This democratization of ML and AI will be the catalyst that drives the efficiency gains so many businesses are targeting.
Our Approach
The Databricks Lakehouse already serves as a unified platform to execute a multitude of data and AI use cases, but some recent features and enhancements that we’ll be walking through made this project easier and faster.
Getting data, describing data, data summary
As with every AI/ML project, the first step we settled on after figuring out the desired outcome was getting the right data.
Working with Databricks partner AccuWeather, we were able to use Delta Sharing and access four years of weather information, spanning over 61 million records, in the Databricks Lakehouse in minutes. In addition to cross-platform sharing of live data, Delta Sharing enables organizations to discover, evaluate and access information quickly through the Databricks Marketplace, the open marketplace for data, analytics, and AI.
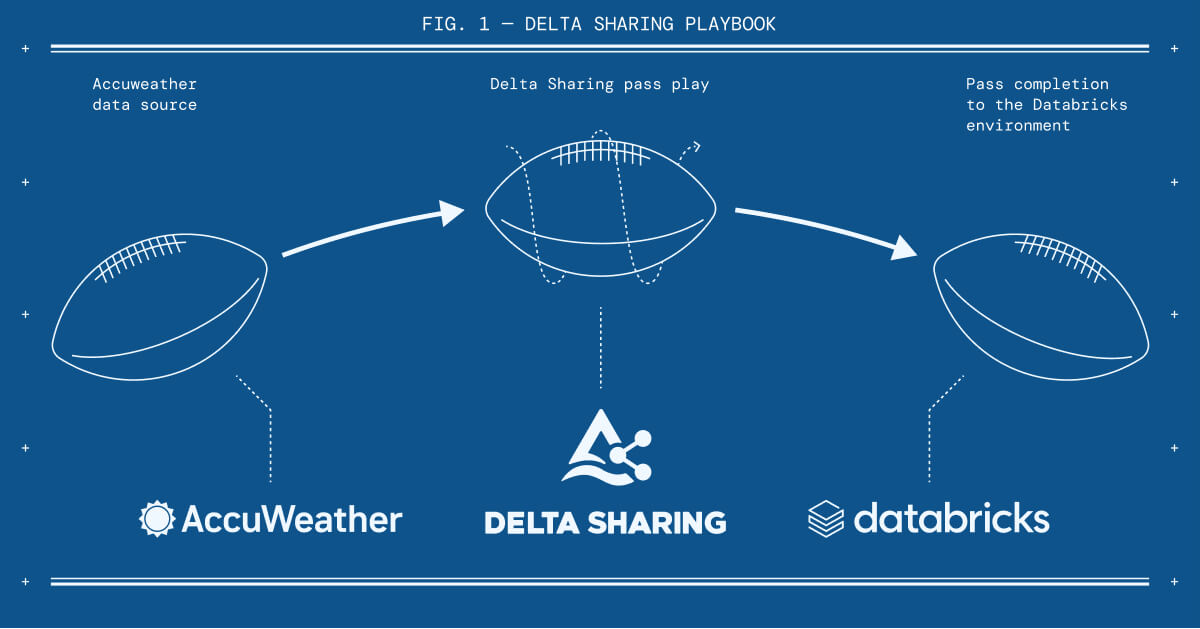
Once we had the data, we narrowed it down to the timeframe of August to December and only used days with football games – Thursdays, Saturdays, Sundays and Mondays. That left us with 17 million.
When building ML models, it’s common to segment a portion of the training data to validate the model. Typically, it’s about an 80-20% split between training and validation data, respectively. In this instance, we used 14 million records to train the model and 3 million to validate it.
These steps are important, as they help narrow down the scope of information the model will be analyzing. In machine learning, the goal is to eliminate as much unnecessary noise as possible. It didn’t make sense to train our model on past information that wasn’t applicable to the outcome we were hoping to achieve. And ultimately, the more relevant the data that the model is trained on, the better it will perform.
As we showed with the Tailgate Index, settling on a desired outcome before making any data decisions can help in segmenting out the most appropriate training and validation information.
Model Development
With that information handy, we could start to build the Tailgate Index.
Before building the model, we had to define the model for the ideal tailgate day. We classified a “perfect” day as one where the weather is between 50 and 80°F, and the cloud cover is less than 60%. Then we got started.
After manually writing some aspects of the model, we got stuck and couldn’t remember some lines of code. Instead of toggling back-and-forth between Stack Overflow or scanning tons of Google results, we simply asked Databricks Assistant. With a command in plain English – I need Python code for a correlation model – Databricks Assistant generated the code, we copied it into our notebook and quickly added it to the model.

The early iterations of our model had a recall rate – a reflection of how accurately it classified the data we ingested – of roughly 65%. To improve that, we had to use a machine learning technique called hyperparameter tuning, a process during which we programmatically tweak the model inputs that provide the best results.
Typically, a data scientist can spend hours, days or weeks changing the parameters of a model to improve the recall rate. It takes a lot of computation and back-end coding. That’s where AutoML is a big help. Alongside hyperparameter tuning, AutoML can help businesses build different ML models – like forecasting or regression – without having to write any code.
For example, with the Tailgate Index, all we had to do was load the training data into AutoML, and in 30 minutes, it generated 50 different classification models for us to pick from – all with different sensitivity (recall) rates.
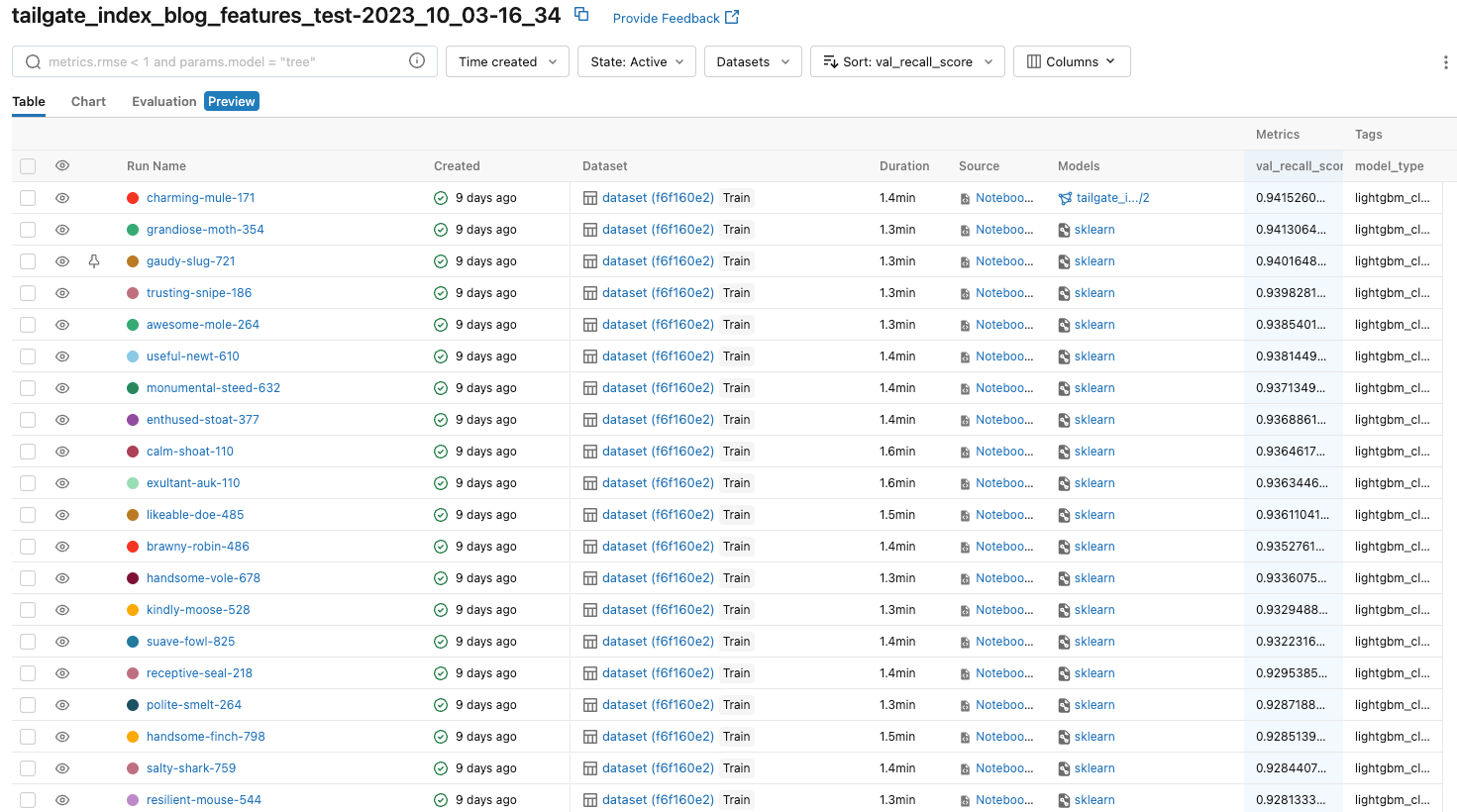
The next step was to settle on one of those models that AutoML provided as our production model. To simplify this process, AutoML provides us with a tabular representation of all model outputs and their corresponding metrics (such as sensitivity, specificity, AUC, etc.). We sorted these models based on sensitivity (recall) to choose our Tailgate Predictor; a LightGBM Classifier. The final model had a recall rate of 95%. Now, we needed to turn the model’s attention from historical data to predicting what’s to come.
To do that, we collected AccuWeather’s forecast data for Nov. 1 to Dec. 31, 2023. Given our objective was to determine ideal tailgating days, we only included days with scheduled NFL or college football games. AccuWeather also had a list of zip codes that have the NFL and the college football stadiums, so we were also able to filter the data even further. (Note: For college football, we only used data related to the top 25 teams as of early October.)
So while weather forecasts could change, based on the current predictions our model has come up with the following list of upcoming games that would be the best for tailgating.
What’s next?
The journey doesn’t end there. After getting the foundational model right, we could easily go to Databricks Marketplace and find additional data and AI assets that would help customize the model even further or help it answer different queries.
For businesses, this type of flexibility is critical. It’s how companies build scalable and repeatable AI and ML processes that still provide individual employees the flexibility to tailor models to their specific problems.
If you're already using Databricks, head over to the “Machine Learning” section to start building your own tailgating experience (or sign up here if you want to give Databricks a try).
Want to learn more about how you can use AccuWeather + Databricks to improve your bottom line? Watch this on-demand session from Data + AI Summit 2023!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.