Turbocharged Training: Optimizing the Databricks Stack With FP8
by Mihir Patel, Cheng Li, Davis Blalock and Saaketh Narayan
At Databricks, we believe that the best companies in the world, in every sector, will have AI-powered systems that are trained and customized on their own proprietary data. Today's enterprises can maximize their competitive advantage by training their own AI models.
We’re committed to providing the best platform for enterprises to train AI as quickly and cost-effectively as possible. Today, we’re excited to share several major improvements we’ve made to our LLM stack which have significantly improved pretraining and finetuning efficiency for our customers. In this post, we’ll present our latest throughput numbers and describe several techniques that have helped us to achieve those results and scale to thousands of GPUs.
Latest Benchmark Results
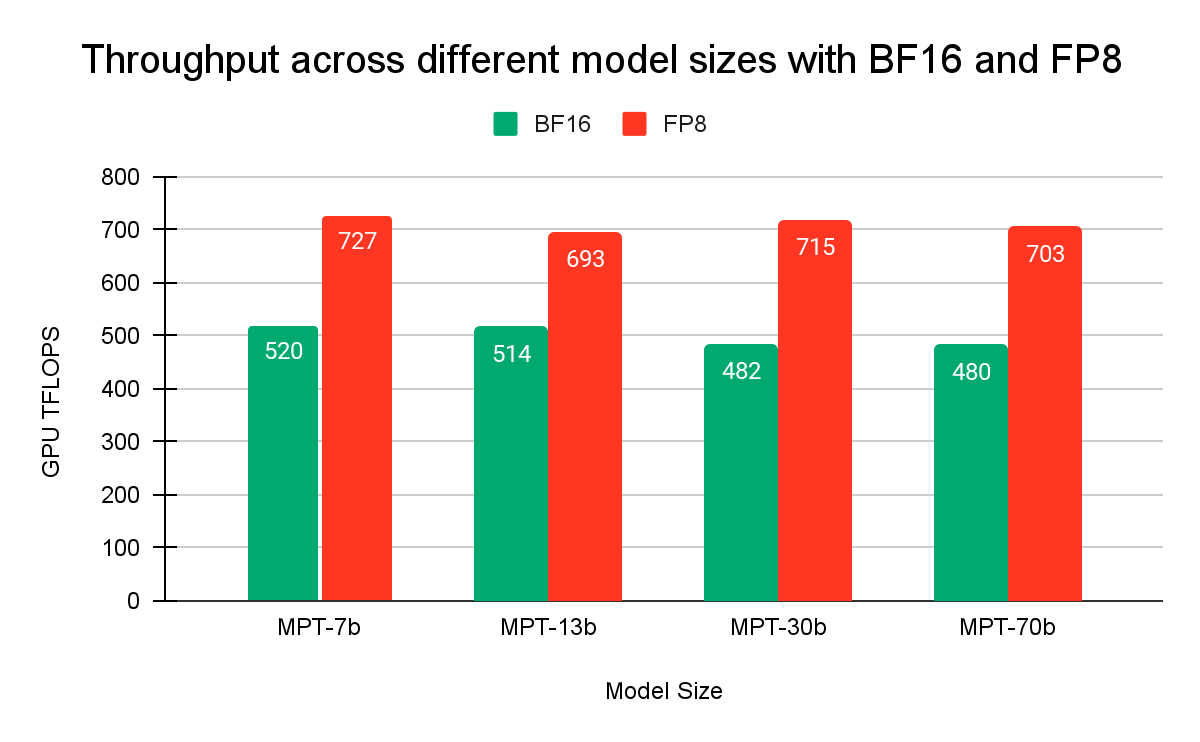
Let’s get straight to the results. Figure 1 shows achieved floating point operations per second (FLOPS) for a training run with different model sizes with BFloat16 (BF16) and FP8 (Float8) data types. We achieve 1.4x-1.5x speedup with FP8 compared to BF16.
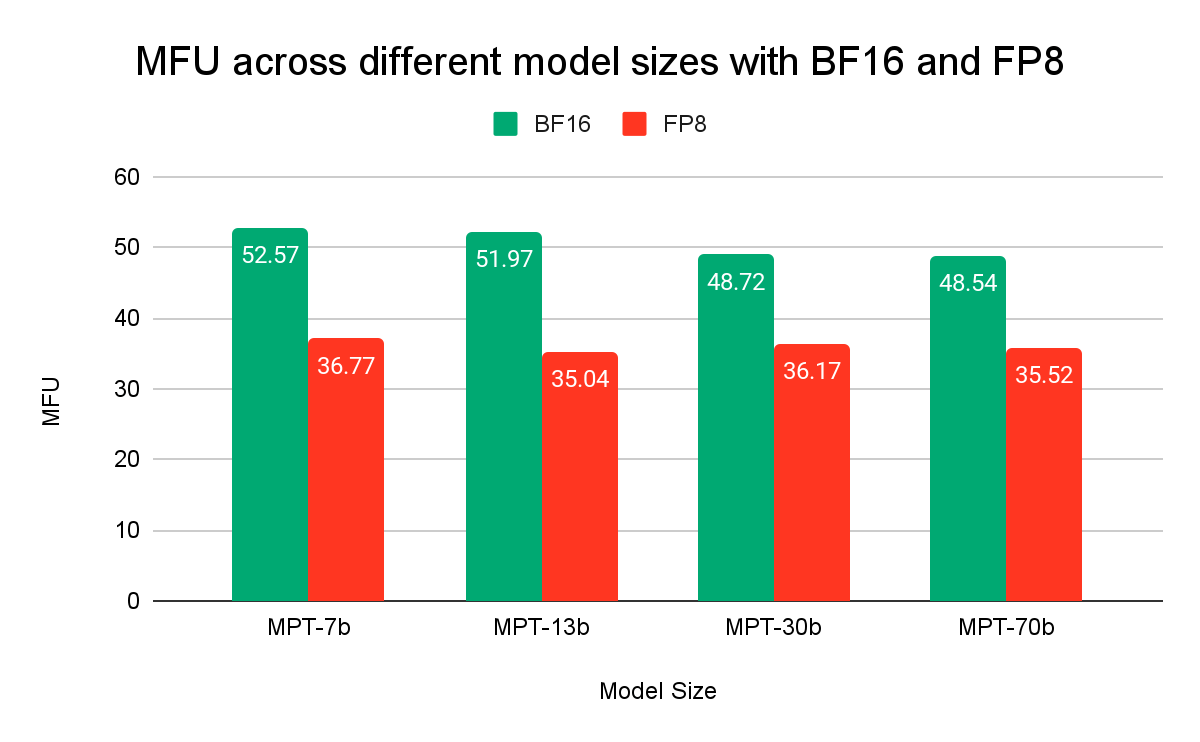
Figure 2 shows how efficiently we are utilizing the underlying hardware during model training with BF16 and FP8. We achieve a model FLOPS utilization (MFU) of > 50% at scale the highest among published numbers by other LLM training frameworks. MFU with FP8 is lower because the utilization is lower with higher speed of FP8.
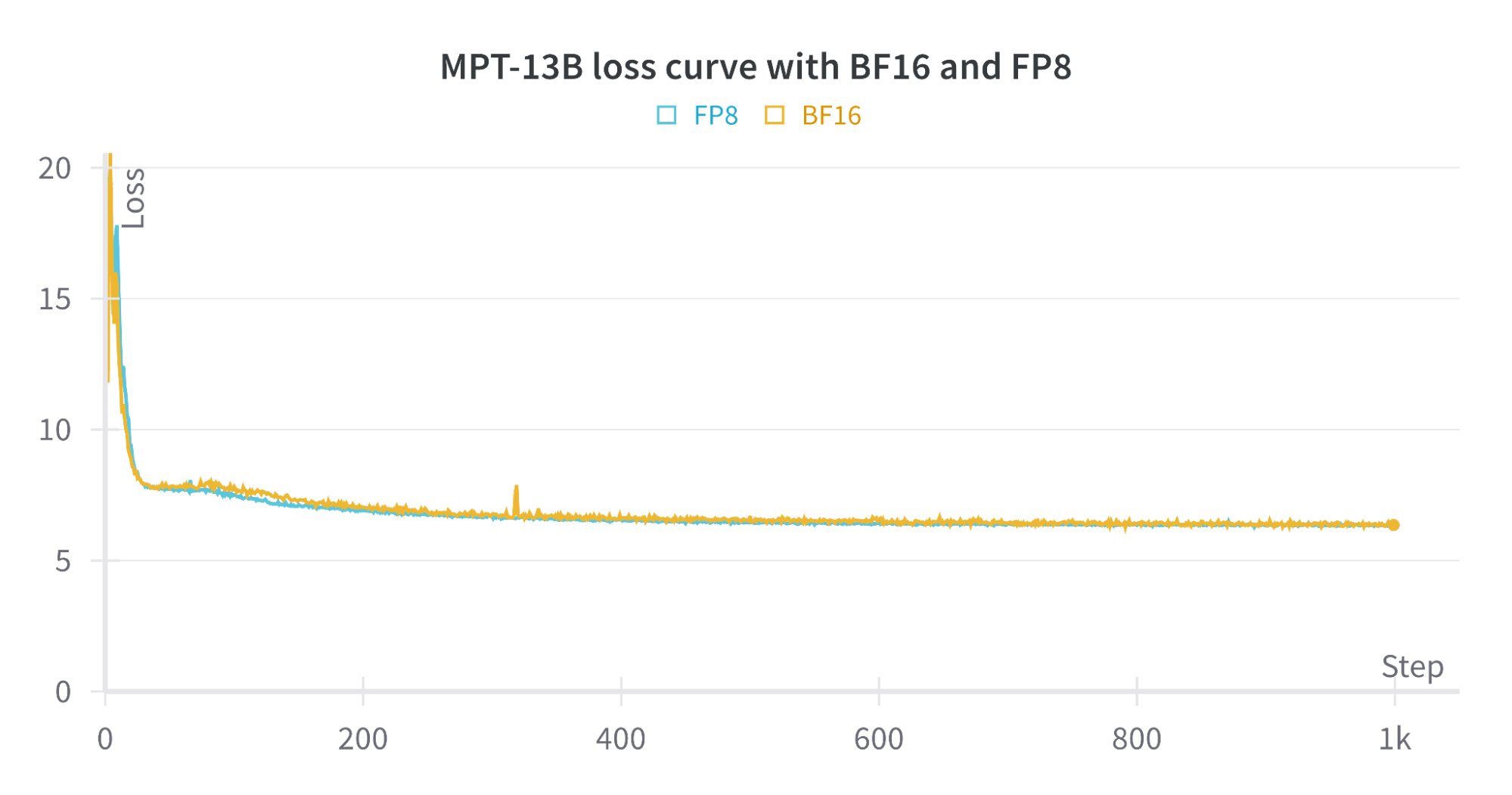
Figure 3 shows the loss curve between BF16 training and FP8 training. The loss curves with BF16 and FP8 are tracking each other closely, indicating that the lower precision of FP8 has minimal impact on model convergence.
How We Accelerate Training
Transformer Engine FP8
NVIDIA H100 Tensor Core GPUs provide native FP8 operations, which presents an additional opportunity to speed up training by running at lower numerical precision. We’ve worked closely with NVIDIA to leverage Transformer Engine, a popular library for FP8 training, in our training stack and ensure it is compatible with PyTorch FSDP. FP8 provides a significant boost in performance, dramatically accelerating large matrix multiplications.
In our training stack, we leverage PyTorch Fully Sharded Data Parallel (FSDP), an implementation of the Zero-3 technique, to parallelize training and scale to thousands of GPUs. In order to ensure FSDP compatibility with Transformer Engine and FP8 training, we’ve worked closely with NVIDIA to identify key bottlenecks, such as memory overhead from initialization and unsharded buffers, to dramatically decrease memory utilization. We’ve also helped extend this stack to integrate with PyTorch activation checkpointing, enabling support for training even larger models.
Configurable Activation Checkpointing
When training large models, GPU memory is consumed by model weights, optimizers, gradients, and activations. PyTorch FSDP shards model weights, optimizers, and gradients. However, activations can still eat up all the memory in a GPU, especially for large models at large batch sizes. If there is not enough memory on a GPU, we can use a technique called activation checkpointing to ensure training can still proceed. Activation checkpointing involves storing only some of the activations on the forward pass and recomputing missing activations in the backwards pass. This involves a tradeoff: it saves memory, but it increases computation in the backward pass.
The standard way to implement activation checkpointing is to do so on an entire transformer block, which consists of attention, MLP, and normalization layers. However, some parts of the model use significantly more memory compared to the amount of compute required. We’ve revamped our activation checkpointing implementation to make it possible to target arbitrary layers and only checkpoint a subset of activations. This lets users checkpoint just enough of the activations to fit a run in memory while minimizing the computational overhead of doing so.
DTensor
When training models at scale, we often want to describe custom parallelism configurations to maximize performance. PyTorch DTensor provides a flexible and easy-to-use interface to specify how tensors and models are sharded and replicated across a multi-GPU cluster. We’ve recently upstreamed several new features to DTensor to allow us to rapidly experiment with different parallelism strategies.
As an example, we rely heavily on DTensor to scale to thousands of GPUs. When running distributed collectives like AllGather across large clusters, we often see poor use of available network bandwidth. This is due to the ring algorithm typically used to implement AllGathers, which scales linearly in latency as the number of GPUs increases. With DTensor, instead of sharding the model across the entire cluster, we can shard the model within smaller blocks and replicate that configuration multiple times across the cluster in parallel, which ensures each communication operation only involves a subset of the cluster instead of the entire cluster. This optimization dramatically improves scalability and ensures we can see near linear improvements as we increase the cluster size.
Communication and Activation Compression
While existing libraries provide great support for low precision matrix multiplications, communication and activation tensors are still primarily in higher precision formats. In order to alleviate communication bottlenecks and decrease memory pressure, we leverage custom kernels for compressing tensors. This technique allows us to increase our tokens per GPU and increase the size of our matrix multiplications. This gives us higher performance since larger matrix multiplications achieve higher hardware utilization.
Come Train with Us!
We’re super excited to start bringing partners onto the next generation of our training platform. Whether you are looking to train from scratch, or finetune a foundation model, the efficiency and performance of our stack will enable you to use your data to unlock your organization’s competitive advantage. Contact us today to get started!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.