The Unconscious Patient Problem: A Look at the Importance Of Entity Resolution in Healthcare and Life Sciences
by Tim Sedlak, Aaron Zavora and Luke Bilbro
This blog was written in collaboration with Tim Sedlak, Senior Solutions Architect at Stardog
In healthcare and life sciences, accuracy is everything. That's particularly true when it comes to entity resolution – the process of identifying, matching, and merging records from multiple data sources that refer to the same thing.
It's a complex – and crucial – task for any healthcare or life science organization. Fortunately, it's also one that's easily handled by the Databricks Data Intelligence Platform. This innovative solution is built on lakehouse architecture and uses Stardog Voicebox as its semantic layer.
Let's take a look at a real-world example of the importance of entity resolution in healthcare. Then, we'll talk about some solutions to the challenges organizations face today.
Patient Identification in the ER – Entity Resolution at its Most Critical
Let's say you're an emergency room doctor. An unconscious patient – the victim of a car crash – is in need of urgent care. You need to make quick decisions that could potentially save their life. The more information you have to base your choices on, the better the outcome. What's the patient's medical history? Any allergies? What medications are they taking?
Thankfully, electronic health records (EHR) make it easier to access data quickly and at scale. But, to retrieve your patient's record, you first have to determine who they are – and they're unconscious. A driver's license could help, but how can you be sure it's current and accurate? Is Bob Smith of 122 Main Street the same person as Robert Smith of 122 Main Street?
You're now in a technical quandary known as identity resolution. Finding the right answer quickly could save a life. Finding the wrong answer could be devastating.
Identity resolution is one problem in the larger space of entity resolution. The goal of entity resolution is to eliminate duplicates, and ensure each entity is uniquely represented. The result is a comprehensive, accurate view of the entity across various datasets.
Conquering Data Challenges to Directly Improve Patient Outcomes
Patient identification is part of a range of entity resolution challenges in healthcare and life sciences. Successfully managing those issues can have a significant positive effect on the patient experience. Those challenges are present in a range of tools, including:
- Digital Front Door: A single identity for a patient across all digital interactions with medical providers and payers can improve the patient experience, and requires a connected understanding of the patient as a singular entity.
- Master Patient Index: Unified directories of health records depend on the reliability of unique identifiers for each patient, and are more scalable when founded on systems that can quickly incorporate data from new and disparate sources.
- Matching Physician Data: Creating a unified and reliable profile for physicians across health records and research databases requires reconciling diverse datasets.
- Matching Facility Data: Accurately linking information about hospitals, clinics, and other facilities in order to improve operations is a complex task, in part because they're often referenced in inconsistent ways.
Optimizing all of these tools to improve the patient experience requires robust entity resolution. But this classically complex problem presents several technical challenges.
- Data Quality and Variability: Inconsistent data formats, typos, missing values, and other data quality issues can significantly hinder the ability to match entities accurately.
- Scalability: As databases grow, the computational complexity of matching records increases exponentially.
- Ambiguity in Data Matching: Different records can have similar or overlapping information, leading to ambiguity in determining whether they refer to the same entity.
- Language and Semantic Differences: For global databases, differences in languages, naming conventions, and cultural nuances add to the complexity of accurately resolving entities.
In previous blogs, we've shared a variety of strategies for solving entity resolution problems with Databricks. Today, we'll highlight the power of using Stardog with Databricks to help healthcare and life science organizations take on entity resolution to quickly improve outcomes and extract value.
What is Stardog?
Stardog uses knowledge graph technology to solve the data silo, sprawl, and context problems that prevent users at any large enterprise from getting a trusted, timely, and accurate answer to any question, subject to data governance and access control.
Stardog customers create a contextualized view of their data stored both inside and outside of Databricks. Data can be explored as a network of information based on the conceptual relationships between data points. This "semantic layer" doesn't require the movement of data outside the storage systems where it resides.
Stardog also helps minimize the risks of Generative AI, such as hallucination, that prevent organizations from adopting large language models (LLMs). Stardog Voicebox, which leverages MosaicML's platform for fine-tuning, is a hallucination-free conversational data platform powered by LLM and Knowledge Graph for the regulated enterprise. Those responses are informed not just by the data, but by what it all means. Early access to Voicebox is available in Stardog Cloud, which in turn integrates with Databricks via Partner Connect.
Stardog Voicebox can identify and link data associated with business objects—for example, patient, provider, facility, procedure, etc.—across a data landscape. That connection results in better decisions in support of healthcare and life science use cases, leveraging the power of Databricks to process data at scale.
The Solution in Action
To demonstrate entity resolution matching capabilities with Stardog and Databricks, we used sample datasets from the Centers for Medicare and Medicaid Services' (CMS) National Plan and Provider Enumeration System (NPPES) and CMS' OpenPayments. NPPES contains basic directory information for every individual physician, while OpenPayments discloses relationships between Drug and Durable Medical Equipment (DME) with physicians. Our goal is to identify the physicians on OpenPayments with their directory information.
We import datasets from Databricks Marketplace, an open market for sharing notebook, data, and models, and use pyspark.sql to normalize the data across sources. We then used Stardog Designer, a visual application that simplifies data modeling, to create a baseline data model to capture the concepts of a Physician, their practice Address, and Specialty. Stardog Designer's data source mapping feature was used to align the National Providers and Open Payments datasets to this data model.
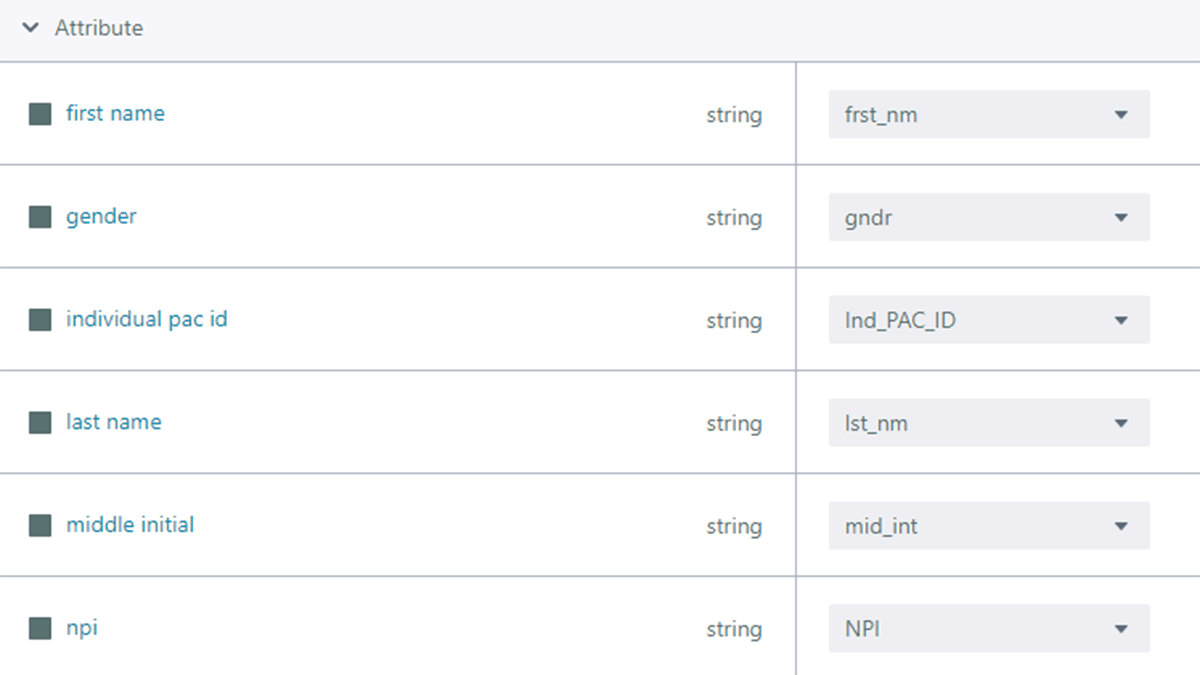
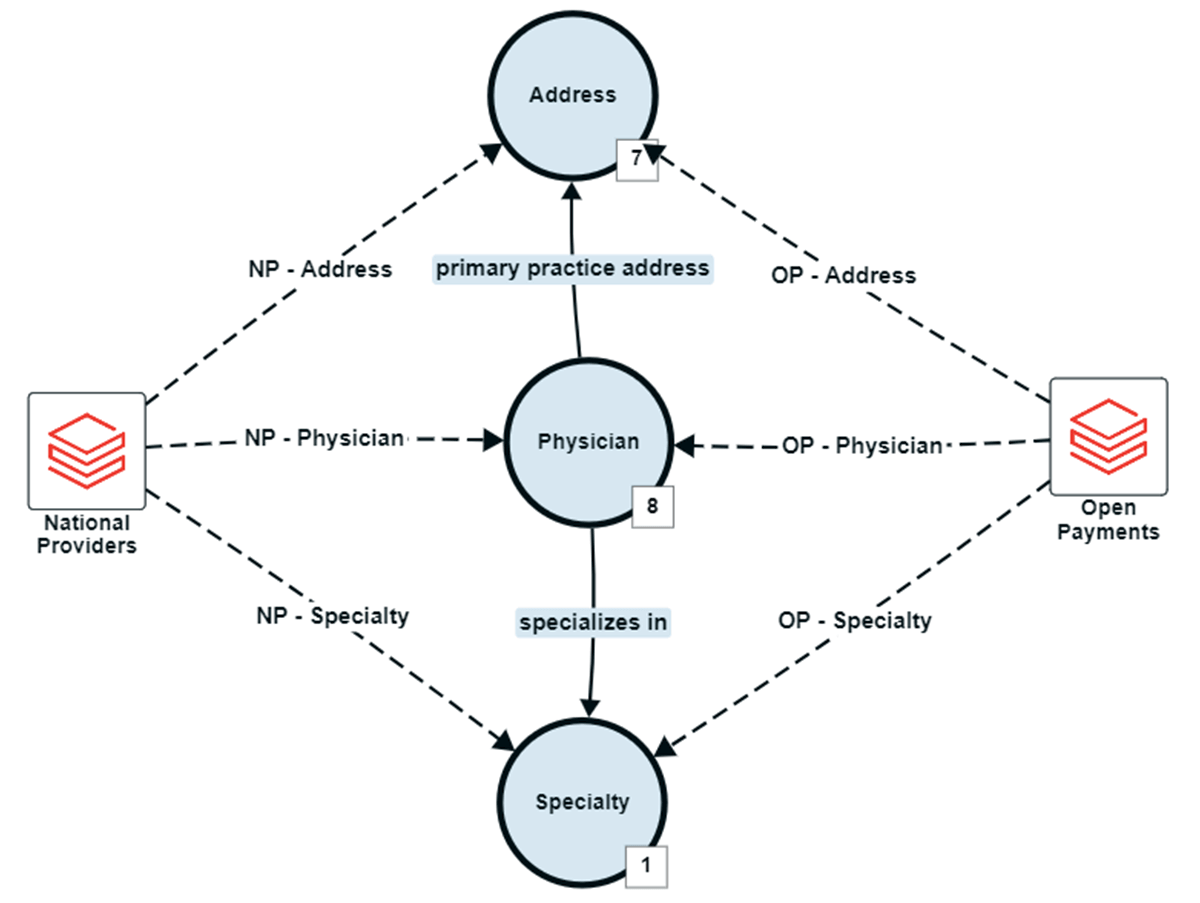
Once published from Designer to Stardog Explorer, which allows business users to visually explore and query enterprise data in a knowledge graph, we can perform federated queries against external sources thanks to virtualization capabilities–in this case, Databricks.
Stardog's entity resolution service, driven by unsupervised machine learning, now becomes the linchpin for resolving real-world entities. Through entity resolution techniques, records within the National Providers and Open Payments datasets are identified and linked. Users provide key details such as the Database name, a query, a key to the field name, and the target graph. Stardog executes the query, performs the entity resolution job, and writes results to the specified graph.
Stardog's external compute feature pushes the entity resolution workload to Databricks Spark and the query is translated into Databricks SQL using virtualization. This federated approach enables seamless data access and integration, bridging the gap between Stardog and Databricks for enhanced efficiency.
We were also able to fine-tune matching precision by setting a similarity threshold. Entities surpassing this threshold are identified as matches or duplicates, offering users a customizable layer to refine the entity resolution process.
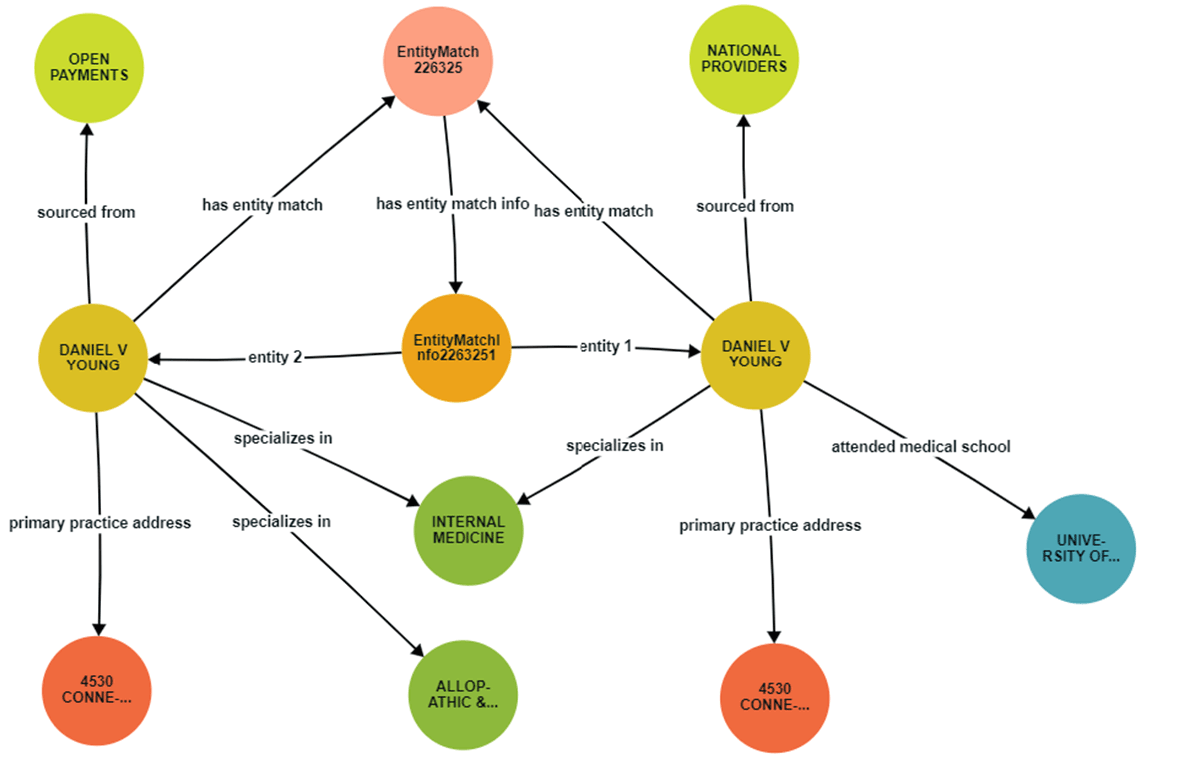
For any healthcare and life sciences organization seeking to improve both experiences and outcomes, merging records from different databases is crucial. The Databricks Data Intelligence Platform built on lakehouse architecture, coupled with Stardog as a semantic layer, provides a robust and scalable alternative to tedious and brittle traditional approaches. This extends to any entity resolution challenge, such as physician data and healthcare facilities, that demands a comprehensive view across datasets.
Building on the efficacy of Stardog and Databricks in resolving entities, Stardog Voicebox users can interact with this unified data in plain language, unlocking its full potential. This approach streamlines data integration, empowering healthcare and life science professionals to make informed decisions at scale.
Get started today with step-by-step instructions in our Github repository.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.