
Proposal for Getting Started With Databricks Groups and Permissions
Introduction
Databricks is a unified analytics platform that combines data engineering, machine learning and business intelligence to help organizations make better use of their big data. Its vision is to make big data simple, accessible and collaborative for all. In this post, we focus on how Databricks can be simply and quickly deployed in enterprise organizations with an appropriate security model, mapping different sets of privileges to different job roles or personas with a predefined blueprint.
When organizations deploy a technology such as Databricks in their environment, they must assign different privileges to groups of people with different job-role personas in the organization by applying an IAM (Identity and Access Management) strategy. IAM manages access to components of the technology platform to control who can access, modify or delete resources.
For a default Databricks installation, all users can create and modify workspace objects unless an administrator enables workspace access control. This post is aimed at organizations that want to implement segregation of access control within a workspace. To enable this, the Databricks administrator must enable workspace access control. This feature requires the Databricks Premium plan and above.
One of the main goals of the IAM strategy is to ensure that operational requirements around segregation of duty are enforced. This is required for:
- Regulatory compliance — EG ensuring business users cannot interfere with audit data
- Risk avoidance — EG avoiding the risk of a developer changing live business data
This introduces the challenge of mapping different combinations of technology-specific options to an organization’s operating model. The options to choose from and the combinations required for each job function are different for each technology that the organization uses, and this can add extra effort and complexity when onboarding new technologies such as Databricks for the first time.
This post provides a blueprint with guidance on how to map typical personas (job roles) to a sample set of groupings of permissions. The benefits of this are:
- Quicker implementation time for a first-release design
- Best practice guidance in an easily consumable and practical structure
- Flexibility to adjust and extend the blueprint to match a company’s operating model
Market Research
Industry Landscape
The ability to map security privileges to each customer-organization’s operating model is a common requirement across cloud vendors and software vendors. Before developing the blueprint guidance in this post, a survey of other cloud vendors was performed. This was done with the objective of making the Databricks approach as similar to other industry approaches as possible to reduce complexity and effort for the end user.
An approximate, but not exact, mapping of similar equivalent roles across different cloud vendor platforms is shown in the table below as an example:
| AWS Lake Formation | Azure Synapse | Azure ML | Power BI | Google BigQuery |
|---|---|---|---|---|
| Data Lake Administrator | Administrator | Owner | Admin, Member | Data Owner |
| Data Engineer | Contributor | Contributor | Contributor | Data Editor |
| Artifact Publisher | Data Scientist | |||
| Artifact User | ||||
| Workflow Role | Compute Operator |
Compute Operator |
User | |
| Registry User | ||||
| Monitoring Operator |
||||
| Credential User | ||||
| Linked Data Manager | ||||
| Data Analyst | Reader | Viewer | Data Viewer / Filtered Data Viewer |
Table 1. Comparison of personas for a sample of cloud vendors
Market Research Conclusion
All the vendors surveyed take a similar approach, using predefined roles or personas to simplify the process of controlling access to resources in a way that is appropriate for different job functions.
One of the challenges apparent during the market research survey was that for each vendor, different groups of persona classification for different technology components have to be mapped to the same sets of identities to create an end-to-end lakehouse solution for sourcing and transforming data, building and deploying AI models, and making curated data and AI models available to analysts. This adds an extra layer of complexity to the process of setting up an end-to-end data analytics solution.
The observations from this market research are used to form the approach for the Identity Management guidance and strategy defined in this post. In this post we simplify the approach further by defining a common set of role persona names that cover the entire lakehouse architecture — data management, data analytics, and AI and business analysis. This approach and these roles are also common across deployments on AWS, Azure and GCP.
Databricks Identity Management
Databricks offers out-of-the-box integration with identity providers for simple and programmatic management of users and groups into the platform. It also offers a central, well-governed identity configuration interface to assign users and groups to various workspaces.
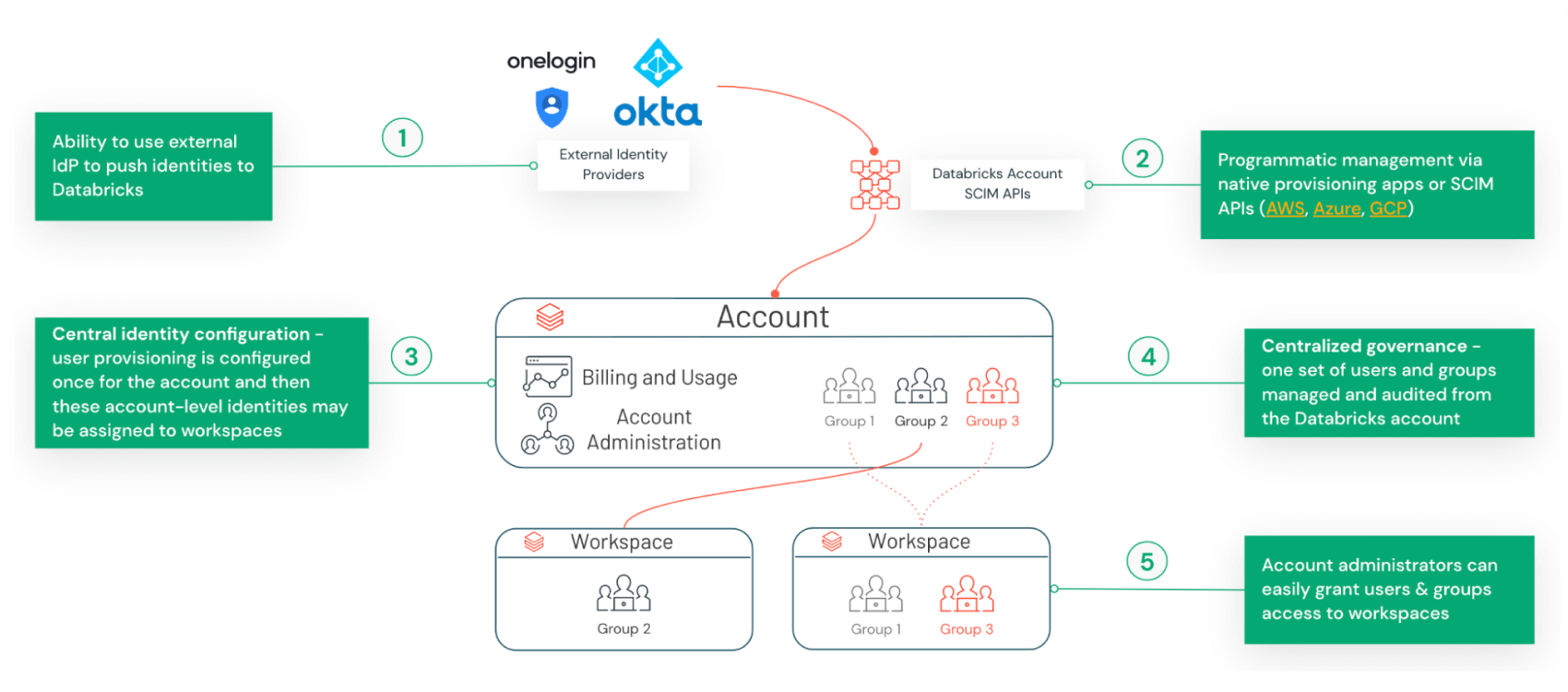
Figure 1. Databricks Identity Management
There is a separate set of permissions specific to Databricks account-level operations such as user management, workspace creation, and billing and resource management. Account-level privileges are documented here and not covered further in this post.
Workspace Access Control
This article focuses on permissions granted to identities at the Databricks workspace level. A workspace is a logical grouping of compute resources and associated libraries, notebooks and processing jobs. Users collaborate on the Databricks platform by being assigned to specific workspaces. The following classes of privilege can be assigned across the many different resources available in a Databricks workspace:
- Read
- View
- Attach
- Use
- Run
- Edit
- Write
- Manage
- Owner
The details of these options for each resource type are documented here. There is also a permissions API available to set these privileges programmatically. This post sets out to simplify the process of assigning appropriate privileges to different groups of identities by providing a standard template approach for different persona types.
Proposal: Manage 6 Simple Groups Across Environments
For organizations that do not already have well-defined analytics groups, we propose a set of six groups that should be granted a series of default permissions on all objects across each environment on a per-group basis. Individual identities are assigned to the appropriate group based on their persona (job function) as per the list below. This speeds up time to productivity and simplifies collaboration on the platform.
- Admin. The persona who is the highest point of escalation across every environment. This should be a highly restricted role.
- Data engineers. These individuals build data pipelines and should have access to their own assets and environment (provided out of the box by Databricks). These personas should also have visibility of commonly shared assets that do not contain sensitive information but whose metadata and configuration data are useful for reference.
- Data scientists/ML engineers. These individuals develop models and experiments, and should have access to their own assets and environment (provided out of the box by Databricks)
- Analysts. Personas focused on querying various data sets whose scope on Databricks objects should be limited. Complexity of setting them up comes from access to data itself, and the permissions they are granted on tables via Unity Catalog, but data object privileges are out of scope for this work.
- Deployers (DevOps Engineer). This persona is focused on devops and SDLC, and will help review code and move projects into production. We believe they should have access to most UAT/PROD assets to achieve these goals. However, for PROD specifically, we recommend this persona to be restricted to Service Account/Service Principal users rather than human users.
- Support. These play a crucial role in helping data engineers, data scientists, analysts or even deployers debug their application across the different environments, and should have the right level of access from the start to be able to assist.
This template approach requires that workspace access control has been enabled.
Assumptions
- We assume that six groups are enough to broadly cover the persona separation needs of an organization
- We assume that there is some level of separation between environments (denoted here as DEV/UAT/PROD)
- We affirm that all individual user code should by default remain private to not discourage innovation
- We assume that PROD workspaces are secure, with no explicit edit access given by default
- The work assumes that users/personas are mapped to groups, and permission on the workspace assets is done at group level and not individual user level
Per Persona Walk-Through
Each persona is assigned to a group appropriate to their job function. This allows them to automatically be assigned a set of privileges appropriate to their job role. Custom privileges can be assigned to individuals in addition to these group permissions (or instead of group permissions). This is illustrated in figure 2 below.
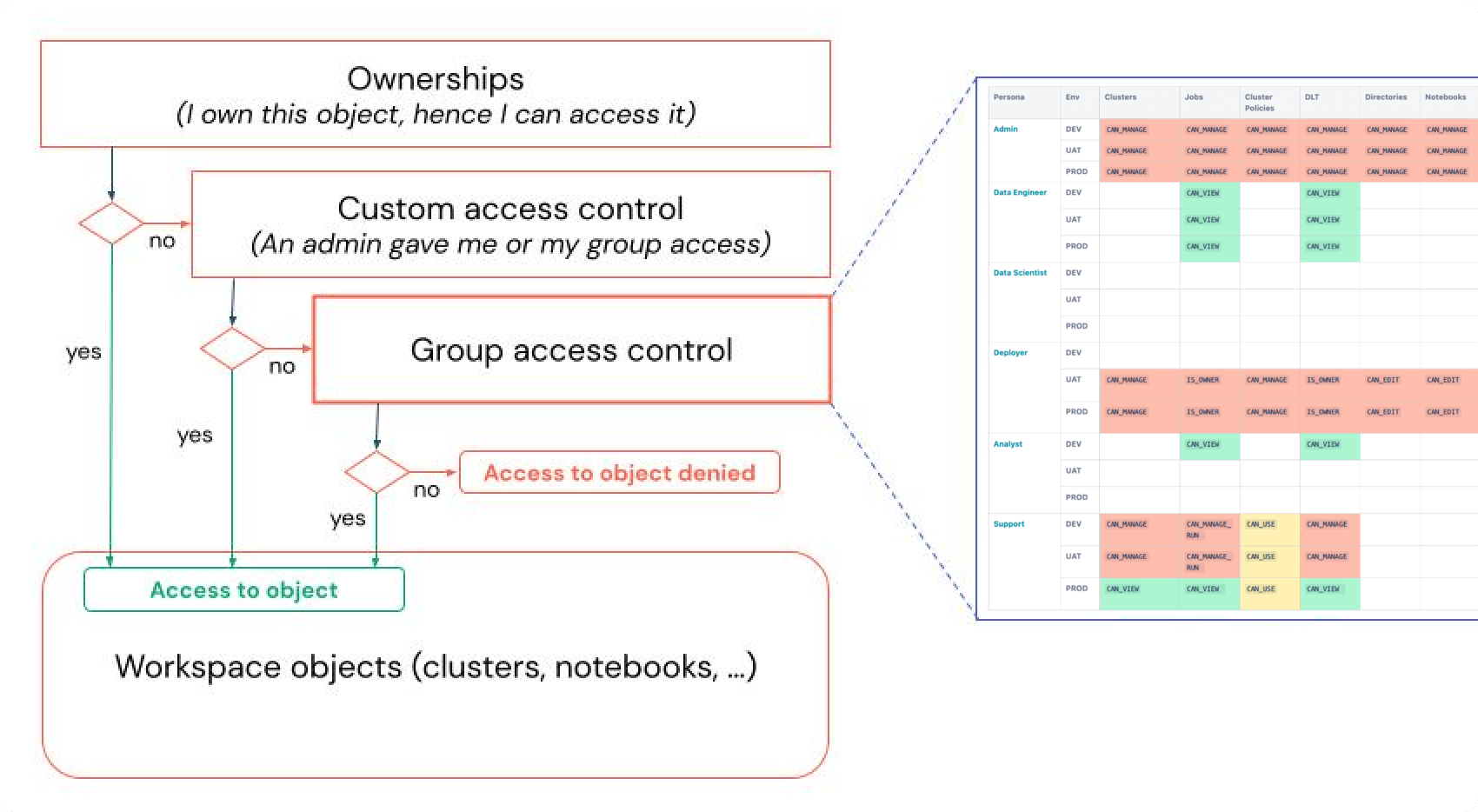
Figure 2. Hierarchy of access to resource objects
The matrix in figure 3 below shows the detailed mapping of privileges to different persona groups on a per resource-type basis. This is a default example mapping that can be adjusted to suit a particular organization’s requirements.
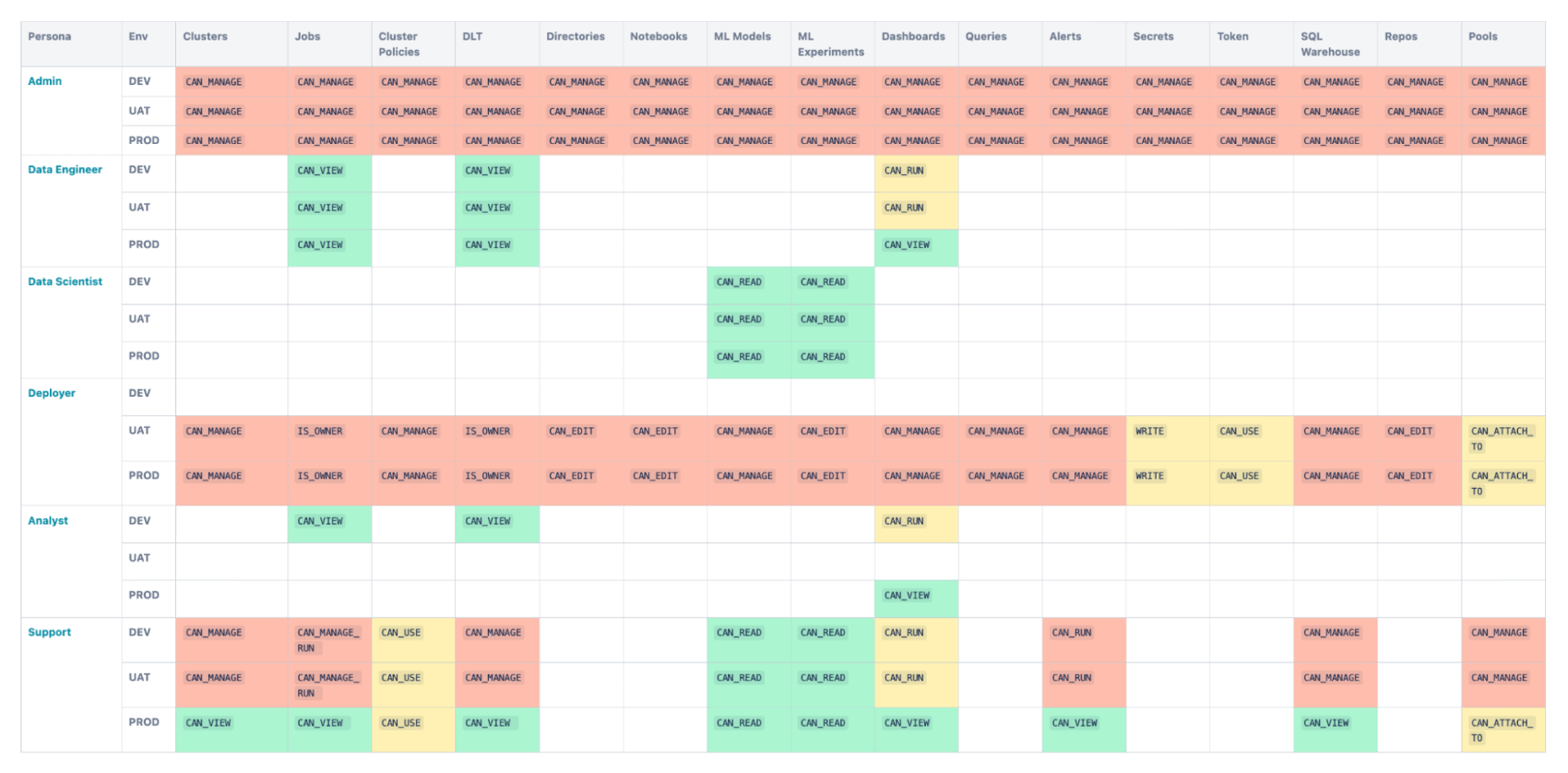
Figure 3. Matrix of resource-type privileges by persona group
Color: Level of permission
Red: High, Yellow: Medium, Green: Low, Empty: No Permissions
A detailed description of each of the persona groups in the matrix above is provided in the next section, along with the privileges assigned.
Admin
An admin persona is an all-encompassing role within the Databricks ecosystem. A workspace admin can:
- Access the admin console
- Manage workspace users and groups
- Manage workspace settings
- Configure cluster policies
- Configure access control
- Manage workspace storage
- Manage Databricks SQL
In addition to managing workspace objects, an admin also works with the network and identity team of the cloud provider for:
- Configuring network security
- SCIM/SSO setup from the IDP
- Connectivity to external data sources
- Private link setup
Data Engineer
The data engineer role covers development activities for data engineering. A person with a data engineer role can be responsible for tasks such as developing new data pipeline transformations and ETL flows.
For a data engineer’s typical day-to-day operations, they are normally granted access to a cluster (or set of clusters) allocated to them by an administrator (“Admin”) where they can work independently in their own repo or folder in a workspace on their own branch of code. When a package of code is ready for deployment into a shared development or test environment, the data engineer typically creates a pull request for the deployer role to merge their branch into the code deployment lifecycle.
Specifically, the data engineer would typically have the following resource privileges:
- Jobs: CAN_VIEW (all environments)
- DLT: CAN_VIEW (all environments)
- Dashboards: CAN_RUN (Dev and Test), CAN_VIEW (PROD)
These are also summarized in the overall matrix of persona to resource-privilege mappings in the earlier “Permissions Overview” section.
Data Scientist/ML Engineer
The data scientist role covers development activities for machine learning. A person with a data scientist role can be responsible for tasks such as developing new machine learning models or creating an ML experiment.
For a data scientist’s typical day-to-day operations, they are normally granted access to a cluster (or set of clusters) allocated to them by an administrator (“Admin”) where they can work independently in their own repo or folder in a workspace on their own branch of code. When a package of code is ready for deployment into a shared development or test environment, the data scientist typically creates a pull request for the deployer role to merge their branch into the code deployment lifecycle.
Specifically, the data scientist would typically have the following resource privileges:
- ML models: CAN_READ (all environments)
- ML experiments: CAN_READ (all environments)
- Dashboards: CAN_RUN (Dev and Test), CAN_VIEW (PROD)
These are also summarized in the overall matrix of persona to resource-privilege mappings in the earlier “Permissions Overview” section.
Analyst
An analyst is a persona who uses Databricks for SQL analysis and/or building BI reports or dashboards. Analysts are different from BI users, who only need access to a SQL warehouse to run queries through a BI tool (e.g., Tableau, Power BI). An analyst, on the other hand, uses a SQL warehouse for:
- Authoring new queries, dashboards or alerts
- Refreshing dashboards
- Accessing jobs and DLT that reference dashboards, queries or alerts
- Authoring reports/dashboards in BI tools connecting to a SQL warehouse
An analyst authors dashboard/queries/alerts in the dev environment and hands over code to the deployer for migration to the UAT and PROD environment.
Deployer (DevOps Engineer)
The deployer is a persona that is responsible for deploying artifacts or different configurations into a workspace. Hence, they can manage, own or create most of these objects. The main difference between the deployer and admin personas is that the former only manages what it deploys. The deployer persona segregates the duties of the users who make changes to the code and those who release the code, something often needed in regulated industries.
Since the deployer has a lot of permissions in a workspace, we recommend it to be a service principal (SP). This SP would then be used in a CI/CD process to deploy the code and configurations. This means that the SP would be the owner of important artifacts such as jobs and DLT pipelines in production. There are advantages with this approach:
- The SP can’t “quit” the team, making jobs and clusters ownerless
- Access to UAT and PROD artifacts can be locked down, requiring tests and code reviews to modify
If a CI/CD process is not used, we recommend the deployer to be a senior team member. This person can be responsible for creating, updating and validating artifacts in UAT and PROD. An SP can and should still be assigned as owner, to make sure that jobs and clusters are still operational in case this person leaves the team. Using a “deployer” group is still possible to maintain boundaries. Users can then be assigned to these groups when necessary to allow them to execute the job. This provides a level of control and visibility for user identities operating with elevated privileges.
Support
The support persona is responsible for maintaining and troubleshooting production systems critical to the business. They also are responsible for recommending emergency fixes for releases and configurations of a system/job in case of failure. Examples of permissions for this role are:
- Should be able to view jobs in clusters/configs
- Able to read pipelines, models, dashboards
- Able to view the alerts
- Support team won’t have access to notebooks/scripts, as they are run in production through DLT and Jobs which should show them the output and any information they need for Level 1 troubleshooting
For detailed recommendations on environment-wise permissions, please refer to the permissions matrix.
The support role sits in between data engineer/data scientist/analyst and deployer. Support should give constant feedback to other personas on the general job health and performance. The deployer should be responsible for giving timely updates on new deployments and any enhancements or changes to the current system back to the support persona.
Custom Access Control
The above permissions are recommended for the workspace as a whole and act as a default permission for a new group or member of a group on the workspace. Administrators can add additional custom permissions on top of the base matrix above to cater to specific needs. For example, as per the matrix above, by default the data engineer persona should not have access to any clusters, but in reality they would need access to a cluster for their development work. Administrators can make additional permission rules that give data engineers, data scientists and analysts access to specific clusters (either can_restart or can_attachto).
For example, assume three clusters are pre-created (Cluster A, Cluster B and Cluster C). There are three development teams (Team A, Team B and Team C) sharing the same workspace. The administrator can follow the approach below to set up permissions.
- Default is no permission for all three teams on all the clusters
- Administrator gives specific permission to each team group
- Can_Restart to Team A on Cluster A
- Can_Restart to Team B on Cluster B
- Can_Restart to Team C on Cluster C
- If a new development team is being onboarded (say, Team D), admin creates a new Cluster — Cluster D — and adds Team D group to the workspace. By default all four teams have no access to Cluster D. Admin then adds Can_Restart permission for Team D on Cluster D.
With the above combination of default and custom permissions, the admin team can easily supervise permissions without compromising security.
Technical Implementation (via Terraform)
The best way to enforce the above permissions is to automate them. Customers can choose between Terraform and Databricks SDK to implement access management. Here we show how it’s done using Terraform. Using the example of Jobs and the permission required for the different personas on the production environment, by referring to the matrix above, it can be implemented in Terraform as below:
Conclusion
Setting up the right workspace permission settings is an important aspect of Databricks platform governance. In this post we have described the various personas and the permission they need across different environments. Customers can choose to alter some of this permission mapping suitable to their needs, keeping best governance principles in mind. Tools like Terraform can be used to enforce such permissions. If you want to know more about Databricks workspace access management, refer to the docs here.