What is a Hadoop Distributed File System (HDFS)?
Distributed storage splitting files into replicated blocks across cluster nodes, providing fault tolerance, scalable capacity, and high-throughput access
- The Hadoop Distributed File System (HDFS) is a storage system that splits files into blocks and distributes them across many machines for scalability and fault tolerance.
- HDFS was designed to store very large datasets on clusters of commodity hardware and keep data available even when individual nodes fail.
- Although many organizations now use cloud object storage with lakehouse architectures, understanding HDFS helps explain the foundation of early big data systems.
HDFS
HDFS (Hadoop Distributed File System) is the primary storage system used by Hadoop applications. This open source framework works by rapidly transferring data between nodes. It's often used by companies who need to handle and store big data. HDFS is a key component of many Hadoop systems, as it provides a means for managing big data, as well as supporting big data analytics.
There are many companies across the globe that use HDFS, so what exactly is it and why is it needed? Let's take a deep dive into what HDFS is and why it may be useful for businesses.
What is HDFS?
HDFS stands for Hadoop Distributed File System. HDFS operates as a distributed file system designed to run on commodity hardware.
HDFS is fault-tolerant and designed to be deployed on low-cost, commodity hardware. HDFS provides high throughput data access to application data and is suitable for applications that have large data sets and enables streaming access to file system data in Apache Hadoop.
So, what is Hadoop? And how does it vary from HDFS? A core difference between Hadoop and HDFS is that Hadoop is the open source framework that can store, process and analyze data, while HDFS is the file system of Hadoop that provides access to data. This essentially means that HDFS is a module of Hadoop.
Let's take a look at HDFS architecture:
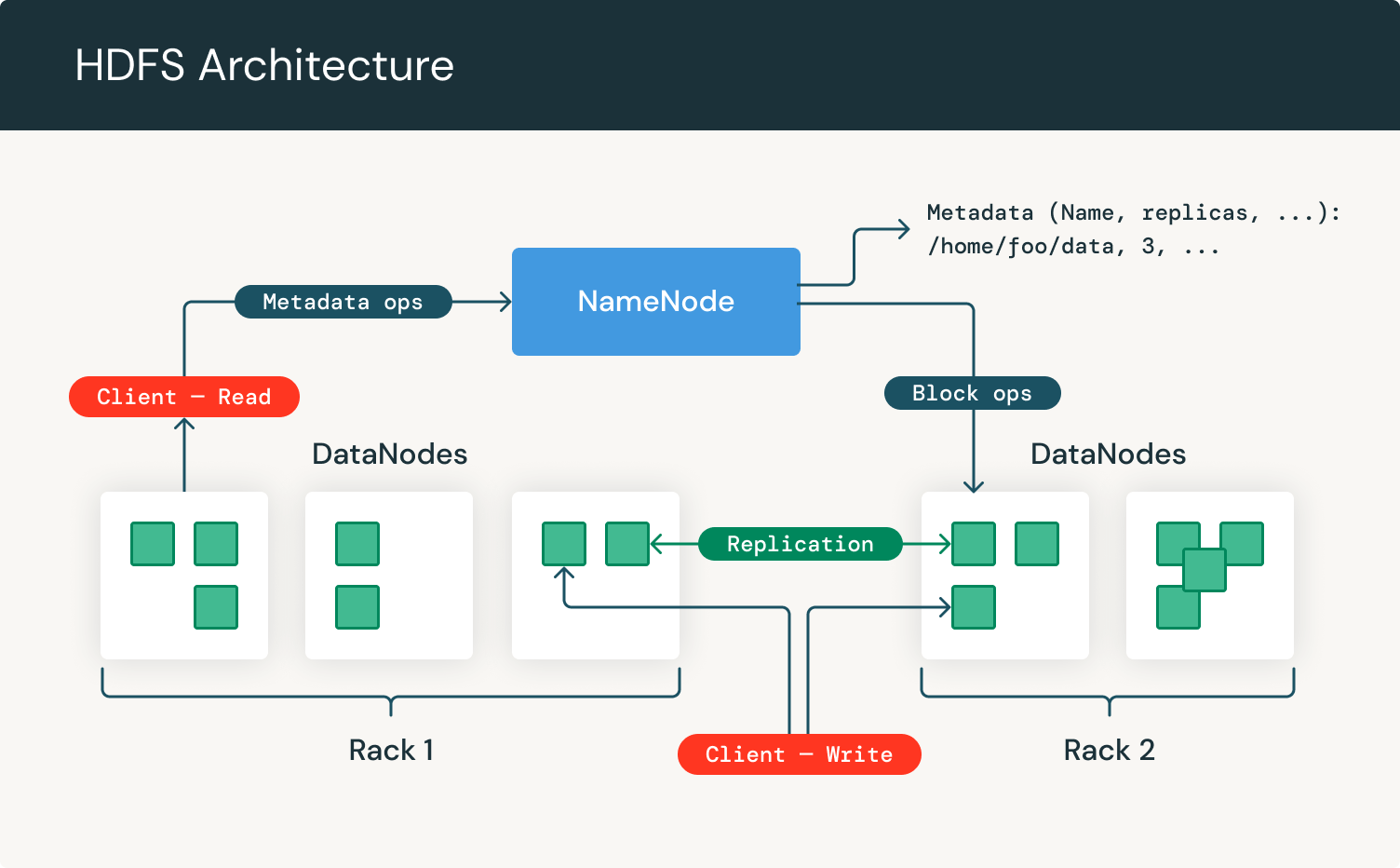
As we can see, it focuses on NameNodes and DataNodes. The NameNode is the hardware that contains the GNU/Linux operating system and software. The Hadoop distributed file system acts as the master server and can manage the files, control a client's access to files, and overseas file operating processes such as renaming, opening, and closing files.
A DataNode is hardware having the GNU/Linux operating system and DataNode software. For every node in a HDFS cluster, you will locate a DataNode. These nodes help to control the data storage of their system as they can perform operations on the file systems if the client requests, and also create, replicate, and block files when the NameNode instructs.
The HDFS meaning and purpose is to achieve the following goals:
- Manage large datasets - Organizing and storing datasets can be a hard talk to handle. HDFS is used to manage the applications that have to deal with huge datasets. To do this, HDFS should have hundreds of nodes per cluster.
- Detecting faults - HDFS should have technology in place to scan and detect faults quickly and effectively as it includes a large number of commodity hardware. Failure of components is a common issue.
- Hardware efficiency - When large datasets are involved it can reduce the network traffic and increase the processing speed.
The history of HDFS
What are Hadoop's origins? The design of HDFS was based on the Google File System. It was originally built as infrastructure for the Apache Nutch web search engine project but has since become a member of the Hadoop Ecosystem.
In the earlier years of the internet, web crawlers started to pop up as a way for people to search for information on web pages. This created various search engines such as the likes of Yahoo and Google.
It also created another search engine called Nutch, which wanted to distribute data and calculations across multiple computers simultaneously. Nutch then moved to Yahoo, and was divided into two. Apache Spark and Hadoop are now their own separate entities. Where Hadoop is designed to handle batch processing, Spark is made to handle real-time data efficiently.
Nowadays, Hadoop's structure and framework are managed by the Apache software foundation which is a global community of software developers and contributors.
HDFS was born from this and is designed to replace hardware storage solutions with a better, more efficient method - a virtual filing system. When it first came onto the scene, MapReduce was the only distributed processing engine that could use HDFS. More recently, alternative Hadoop data services components like HBase and Solr also utilize HDFS to store data.
What is HDFS in the world of big data?
So, what is big data and how does HDFS come into it? The term "big data" refers to all the data that's difficult to store, process and analyze. HDFS big data is data organized into the HDFS filing system.
As we now know, Hadoop is a framework that works by using parallel processing and distributed storage. This can be used to sort and store big data, as it can't be stored in traditional ways.
In fact, it's the most commonly used software to handle big data, and is used by companies such as Netflix, Expedia, and British Airways who have a positive relationship with Hadoop for data storage. HDFS in big data is vital, as this is how many businesses now choose to store their data.
There are five core elements of big data organized by HDFS services:
- Velocity - How fast data is generated, collated and analyzed.
- Volume - The amount of data generated.
- Variety - The type of data, this can be structured, unstructured, etc.
- Veracity - The quality and accuracy of the data.
- Value - How you can use this data to bring an insight into your business processes.
Advantages of Hadoop Distributed File System
As an open source subproject within Hadoop, HDFS offers five core benefits when dealing with big data:
- Fault tolerance. HDFS has been designed to detect faults and automatically recover quickly ensuring continuity and reliability.
- Speed, because of its cluster architecture, it can maintain 2 GB of data per second.
- Access to more types of data, specifically Streaming data. Because of its design to handle large amounts of data for batch processing it allows for high data throughput rates making it ideal to support streaming data.
Compatibility and portability. HDFS is designed to be portable across a variety of hardware setups and compatible with several underlying operating systems ultimately providing users optionality to use HDFS with their own tailored setup. These advantages are especially significant when dealing with big data and were made possible with the particular way HDFS handles data.
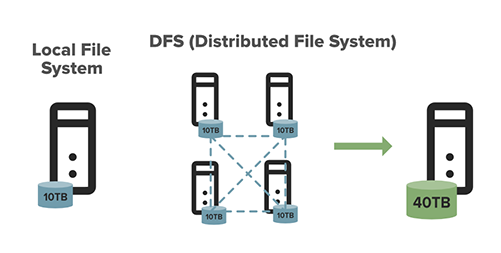
This graph demonstrates the difference between a local file system and HDFS.
- Scalable. You can scale resources according to the size of your file system. HDFS includes vertical and horizontal scalability mechanisms.
- Data locality. When it comes to the Hadoop file system, the data resides in data nodes, as opposed to having the data move to where the computational unit is. By shortening the distance between the data and the computing process, it decreases network congestion and makes the system more effective and efficient.
- Cost effective. Initially, when we think of data we may think of expensive hardware and hogged bandwidth. When hardware failure strikes, it can be very costly to fix. With HDFS, the data is stored inexpensively as it's virtual, which can drastically reduce file system metadata and file system namespace data storage costs. What's more, because HDFS is open source, businesses don't need to worry about paying a licensing fee.
- Stores large amounts of data. Data storage is what HDFS is all about - meaning data of all varieties and sizes - but particularly large amounts of data from corporations that are struggling to store it. This includes both structured and unstructured data.
- Flexible. Unlike some other more traditional storage databases, there's no need to process the data collected before storing it. You're able to store as much data as you want, with the opportunity to decide exactly what you'd like to do with it and how to use it later. This also includes unstructured data like text, videos and images.
How to use HDFS
So, how do you use HDFS? Well, HDFS works with a main NameNode and multiple other datanodes, all on a commodity hardware cluster. These nodes are organized in the same place within the data center. Next, it's broken down into blocks which are distributed among the multiple DataNodes for storage. To reduce the chances of data loss, blocks are often replicated across nodes. It's a backup system should data be lost.
Let's look at NameNodes. The NameNode is the node within the cluster that knows what the data contains, what block it belongs to, the block size, and where it should go. NameNodes are also used to control access to files including when someone can write, read, create, remove, and replicate data across the various data notes.
The cluster can also be adapted where necessary in real-time, depending on the server capacity - which can be useful when there is a surge in data. Nodes can be added or taken away when necessary.
Now, onto DataNodes. DataNodes are in constant communication with the NameNodes to identify whether they need to commence and complete a task. This stream of consistent collaboration means that the NameNode is acutely aware of each DataNodes status.
When a DataNode is singled out to not be operating the way it should, the namemode is able to automatically re-assign that task to another functioning node in the same datablock. Similarly, DataNodes are also able to communicate with each other, which means they can collaborate during standard file operations. Because the NameNode is aware of DataNodes and their performance, they're crucial in maintaining the system.
Datablocks are replicated across multiple datanotes and accessed by the NameNode.
To use HDFS you need to install and set up a Hadoop cluster. This can be a single node set up which is more appropriate for first-time users, or a cluster set up for large, distributed clusters. You then need to familiarize yourself with HDFS commands, such as the below, to operate and manage your system.
| Command | Description |
| -rm | Removes file or directory |
| -ls | Lists files with permissions and other details |
| -mkdir | Creates a directory named path in HDFS |
| -cat | Shows contents of the file |
| -rmdir | Deletes a directory |
| -put | Uploads a file or folder from a local disk to HDFS |
| -rmr | Deletes the file identified by path or folder and subfolders |
| -get | Moves file or folder from HDFS to local file |
| -count | Counts number of files, number of directory, and file size |
| -df | Shows free space |
| -getmerge | Merges multiple files in HDFS |
| -chmod | Changes file permissions |
| -copyToLocal | Copies files to the local system |
| -Stat | Prints statistics about the file or directory |
| -head | Displays the first kilobyte of a file |
| -usage | Returns the help for an individual command |
| -chown | Allocates a new owner and group of a file |
How does HDFS work?
As previously mentioned, HDFS uses NameNodes and DataNodes. HDFS allows the quick transfer of data between compute nodes. When HDFS takes in data, it's able to break down the information into blocks, distributing them to different nodes in a cluster.
Data is broken down into blocks and distributed among the DataNodes for storage, these blocks can also be replicated across nodes which allows for efficient parallel processing. You can access, move around, and view data through various commands. HDFS DFS options such as "-get" and "-put" allow you to retrieve and move data around as necessary.
What's more, the HDFS is designed to be highly alert and can detect faults quickly. The file system uses data replication to ensure every piece of data is saved multiple times and then assigns it across individual nodes, ensuring at least one copy is on a different rack than the other copies.
This means when a DataNode is no longer sending signals to the NameNode, it removes the DataNode from the cluster and operates without it. If this data node then comes back, it can be allocated to a new cluster. Plus, since the datablocks are replicated across several DataNodes, removing one will not lead to any file corruptions of any kind.
HDFS components
It's important to know that there are three main components of Hadoop. Hadoop HDFS, Hadoop MapReduce, and Hadoop YARN. Let's take a look at what these components bring to Hadoop:
- Hadoop HDFS - Hadoop Distributed File System (HDFS) is the storage unit of Hadoop.
- Hadoop MapReduce - Hadoop MapReduce is the processing unit of Hadoop. This software framework is used to write applications to process vast amounts of data.
- Hadoop YARN - Hadoop YARN is a resource management component of Hadoop. It processes and runs data for batch, stream, interactive, and graph processing - all of which are stored in HDFS.
How to create an HDFS file system
Want to know how to create HDFS file system? Follow the steps below which will guide you on how to create the system, edit it, and remove it if needed.
Listing your HDFS
Your HDFS listing should be /user/yourUserName. To view the contents of your HDFS home directory, enter:
As you're just getting started, you won't be able to see anything at this stage. When you want to view the contents of a non-empty directory, input:
You can then see the names of the home directories of all the other Hadoop users.
Creating a directory in HDFS
You can now create a test directory, let's call it testHDFS. It will appear within your HDFS. Just enter the below:
Now you must verify that the directory exists by using the command you entered when listing your HDFS. You should see the testHDFS directory listed.
Verify it again using the HDFS full pathname to your HDFS. Enter:
Double check that this is working before you take the next steps.
Copy a file
To copy a file from your local file system to HDFS, start by creating a file you wish to copy. To do this, enter:
That is going to create a new file called testFile, including the characters HDFS test file. To verify this, input:
ls
And then to verify that the file was created, enter:
You will then need to copy the file to HDFS. To copy files from Linux into HDFS, you need to use:
Notice that you have to use the command "-copyFromLocal" because the command "-cp" is used to copy files within HDFS.
Now you just need to confirm that the file has been copied over correctly. Do this by entering the following:
Moving and copying files
When copying the testfile it was put into the base home directory. Now you can move it into the testHDFS directory you've already created. Use the following:
The first part moved your testFile from the HDFS home directory into the test one you created. The second part of this command then shows us that it's no longer in the HDFS home directory, and the third part confirms that it's now been moved to the test HDFS directory.
To copy a file, input:
Checking disk usage
Checking disk space is useful when you're using HDFS. To do this you can enter the following command:
This will then allow you to see how much space you are using in your HDFS. You can also view how much space is available in HDFS across the cluster by entering:
Removing a file/directory
There may come a time when you need to delete a file or directory in the HDFS. This can be achieved with the command:
You'll see that you still have the testHDFS directory and testFile2 leftover that you created. Remove the directory by entering:
It will then pop up with an error message - but don't panic. It will read something like "rmdir: testhdfs: Directory is not empty". The directory needs to be empty before it can be deleted. You can use the "rm" command to bypass this and remove a directory including all the files it contains. Enter:
The agentic AI playbook for the enterprise

How to install HDFS
To install Hadoop, you need to remember that there is a singlenode and a multinode. Depending on what you require, you can either use a singlenode or multinode cluster.
A single node cluster means only one DataNode is running. It will include the NameNode, DataNode, resource manager, and node manager on one machine.
For some industries, this is all that's needed. For instance, in the medical field, if you're conducting studies and need to collect, sort, and process data in a sequence, you can use a singlenode cluster. This can easily handle the data on a smaller scale, as compared to data distributed across many hundreds of machines. To install a singlenode cluster, follow these steps:
- Download the Java 8 Package. Save this file in your home directory.
- Extract the Java Tar File.
- Download the Hadoop 2.7.3 Package.
- Extract the Hadoop tar File.
- Add the Hadoop and Java paths in the bash file (.bashrc).
- Edit the Hadoop Configuration files.
- Open core-site.xml and edit the property.
- Edit hdfs-site.xml and edit the property.
- Edit the mapred-site.xml file and edit the property.
- Edit yarn-site.xml and edit the property.
- Edit hadoop-env.sh and add the Java path.
- Go to Hadoop home directory and format the NameNode.
- Go to hadoop-2.7.3/sbin directory and start all the daemons.
- Check that all the Hadoop services are running.
And there you have it, you should now have a successfully installed HDFS.
How to access HDFS files
It will come as no surprise that security is tight when it comes to HDFS, given that we're dealing with data. As HDFS is technically virtual storage, it spans across the cluster so you can only see the metadata on your file system, you won't be able to view the actual specific data.
To access HDFS files you can download the "jar" file from HDFS to your local file system. You can also access the HDFS using its web user interface. Simply open your browser and type "localhost:50070" into the search bar. From there, you can see the web user interface of HDFS and move to the utilities tab on the right hand side. Then click "browse file system," this shows you a full list of files located on your HDFS.
HDFS DFS examples
Here are some of the most common Hadoop command examples.
Example A
To delete a directory you need to apply the following (note: this can only be done if the files are empty):
Or
Example B
When you have multiple files in an HDFS, you can use a "-getmerge" command. This will merge multiple files into a single file, which you can then download to your local file system. You can do this with the following:
Or
Example C
When you want to upload a file from HDFS to local, you can use the "-put" command. You specify where you want to copy from, and what file you want to copy onto HDFS. Use the below:
Or
Example D
The count command is used to track the number of directories, files, and file size on HDFS. You can use the following:
Or
Example E
The "chown" command can be used to change the owner and group of a file. To activate this, use the below:
Or
What is HDFS storage?
As we now know, HDFS data is stored in something called blocks. These blocks are the smallest unit of data that the file system can store. Files are processed and broken down into these blocks, which are then taken and distributed across the cluster - and also replicated for safety. Typically, each block can be replicated three times. This diagram shows big data and how it can be stored with HDFS.
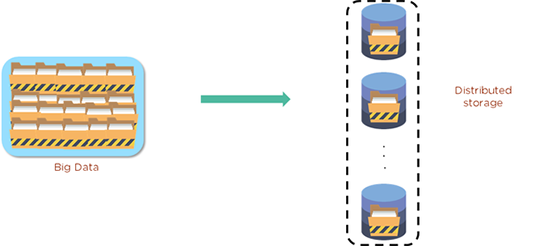
The first you will find on the DataNode, the second is stored on a separate DataNode within the cluster, and a third is stored on a DataNode in a different cluster. This is like a triple protection security step. So, if the worst should happen and one replica fails, the data is not gone for good.
The NameNode keeps important information, such as the number of blocks and where the replicas are stored. In comparison, a DataNode is storing the actual data, and can create blocks, remove blocks, and replicate blocks on command. It looks like this:
This determines where DataNodes should store its blocks.
How does HDFS store data?
The HDFS file system consists of a set of Master services (NameNode, secondary NameNode, and DataNodes). The NameNode and secondary NameNode manage the HDFS metadata. The DataNodes host the underlying HDFS data.
The NameNode tracks which DataNodes contain the contents of a given file in HDFS. HDFS divides files into blocks and stores each block on a DataNode. Multiple DataNodes are linked to the cluster. The NameNode then distributes replicas of these data blocks across the cluster. It also instructs the user or application where to locate wanted information.
What is the Hadoop distributed file system (HDFS) designed to handle?
Put simply, when asking "what is the Hadoop distributed file system designed to handle?" The answer is first and foremost - big data. This can be invaluable to large corporations that would otherwise struggle to manage and store data from their business and customers.
With Hadoop, you can store and unite data, whether it's transactional, scientific, social media, advertising, and machine. It also means you can come back to this data and gain valuable insights into business performance and analytics.
As it was designed to store data, HDFS can also handle raw data which is commonly used by scientists or those in the medical field who are looking to analyze such data. These are called data lakes. It allows them to combat more difficult questions without restraints.
What's more, as Hadoop was primarily designed to handle enormous volumes of data in various ways, it can also be used to run algorithms for analytical purposes. This means it helps businesses to process and analyze data more efficiently, allowing them to discover new trends and anomalies. Certain datasets are even being removed from data warehouses and moved to Hadoop. It just makes it easier to store everything in one easily accessible place.
When it comes to transactional data, Hadoop is also equipped to handle millions of transactions. Thanks to its storage and processing abilities, it can be used to store and analyze customer data. You can also deep dive into the data to discover emerging trends and patterns to help with business goals. Don't forget, Hadoop is constantly being updated with fresh data, and you can compare new and old data to see what has changed, and why.
Considerations with HDFS
By default, HDFS is configured with 3x replication which means datasets will have two additional copies. While this improves the likelihood of localized data during processing, it does introduce overhead storage costs.
- HDFS works best when configured with locally attached storage. This ensures the best performance for the file system.
- Increasing the capacity of HDFS requires the addition of new servers (compute, memory, disk), not just storage media.
HDFS vs. Cloud Object Storage
As mentioned above, HDFS capacity is tightly coupled with computing resources. Increasing storage capacity entails increasing CPU resources, even though the latter is not required. When adding more data nodes to HDFS, a rebalance operation is required to distribute existing data to the newly added servers.
This operation can take some time. Scaling a Hadoop cluster in an on-premises environment can also be difficult from a cost and space perspective. HDFS uses locally attached storage which can provide IO performance benefits assuming YARN can provision processing on the servers that store the data to be processed.
With heavily utilized environments, it's possible that most data read/write operations will be over the network vs local. Cloud object storage includes technologies such as Azure Data Lake Storage, AWS S3, or Google Cloud Storage. It's independent of computing resources that access it and hence customers can store far larger amounts of data in the cloud.
Customers that are looking to store Petabytes worth of data can easily do this in cloud object storage. However, all read and write operations against cloud storage will be over the network. So, it's important that applications that will access its data leverage caching where possible or include logic to minimize IO operations.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.