What is Spark Tuning?
The systematic optimization of Apache Spark configurations, memory usage, and execution strategies to maximize performance while preventing resource bottlenecks
- Spark tuning is the practice of adjusting Apache Spark settings for memory, cores and execution so jobs run faster and avoid resource bottlenecks.
- Key optimizations include choosing efficient data serialization, tuning memory use for storage and execution, and managing garbage collection to keep more data in memory.
- Developers also look at data structures and shuffle behavior so Spark can use cluster resources efficiently without excessive spilling or contention.
What is Spark Performance Tuning?
Spark Performance Tuning refers to the process of adjusting settings to record for memory, cores, and instances used by the system. This process guarantees that the Spark has a flawless performance and also prevents bottlenecking of resources in Spark. 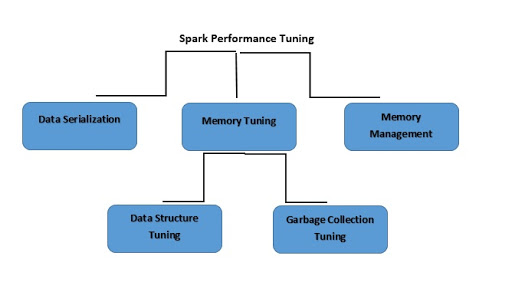
What is Data Serialization?
In order, to reduce memory usage you might have to store spark RDDs in serialized form. Data serialization also determines a good network performance. You will be able to obtain good results in Spark performance by:
- Terminating those jobs that run long.
- Ensuring that jobs are running on a precise execution engine.
- Using all resources in an efficiently.
- Enhancing the system’s performance time
Spark supports two serialization libraries, as follows:
- Java Serialization
- Kryo Serialization
What is Memory Tuning?
While tuning memory usage, there are three aspects that stand out:
- The entire dataset has to fit in memory, consideration of memory used by your objects is the must.
- By having an increased high turnover of objects, the overhead of garbage collection becomes a necessity.
- You’ll have to take into account the cost of accessing those objects.
The agentic AI playbook for the enterprise

What is Data Structure Tuning?
One option to reduce memory consumption is by staying away from java features that could overhead. Here are a few ways to do this:
- In case the RAM size is less than 32 GB, the JVM flag should be set to –xx:+ UseCompressedOops. This operation will build a pointer of four bytes instead of eight.
- Nested structures can be dodged by using several small objects as well as pointers.
- Instead of using strings for keys you could use numeric IDs and enumerated objects
What is Garbage Collection Tuning?
In order to avoid the large “churn” related to the RDDs that have been previously stored by the program, java will dismiss old objects in order to create space for new ones. However, by using data structures that feature fewer objects the cost is greatly reduced. One such example would be the employment an array of Ints instead of a linked list. Alternatively, you could use objects in the serialized form, so you will only have a single object for each RDD partition.
What is Memory Management?
An efficient memory use is essential to good performance. Spark uses memory mainly for storage and execution. Storage memory is used to cache data that will be reused later. On the other hand, execution memory is used for computation in shuffles, sorts, joins, and aggregations. Memory contention poses three challenges for Apache Spark:
- How to arbitrate memory between execution and storage?
- How to arbitrate memory across tasks running simultaneously?
- How to arbitrate memory across operators running within the same task?
Instead of avoiding statically reserving memory in advance, you could deal with memory contention when it arises by forcing members to spill.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.