Skip to main content
What is a Resilient Distributed Dataset (RDD)?
Understand Spark's foundational data structure for distributed, fault-tolerant parallel processing
- A Resilient Distributed Dataset (RDD) is Spark's original core data structure for working with collections of data that are split across a cluster and processed in parallel.
- RDDs are immutable and support low level transformations and actions, which is useful when you need fine grained control or are working with unstructured data.
- Even though higher level APIs like DataFrames and Datasets are now preferred for most structured workloads, they are built on top of RDDs and you can still move between them when needed.
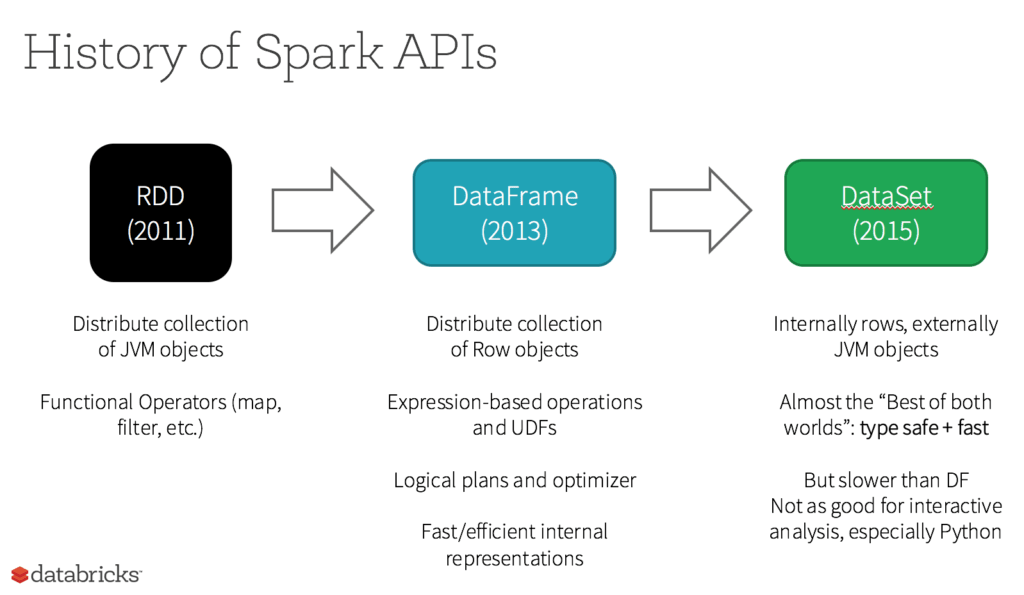
RDD was the primary user-facing API in Spark since its inception. At the core, an RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
5 Reasons on When to use RDDs
- You want low-level transformation and actions and control on your dataset;
- Your data is unstructured, such as media streams or streams of text;
- You want to manipulate your data with functional programming constructs than domain specific expressions;
- You don’t care about imposing a schema, such as columnar format while processing or accessing data attributes by name or column; and
- You can forgo some optimization and performance benefits available with DataFrames and Datasets for structured and semi-structured data.
REPORT
The agentic AI playbook for the enterprise

What happens to RDDs in Apache Spark 2.0?
Are RDDs being relegated as second class citizens? Are they being deprecated? The answer is a resounding NO! What’s more is you can seamlessly move between DataFrame or Dataset and RDDs at will—by simple API method calls—and DataFrames and Datasets are built on top of RDDs.
Additional Resources
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.