Elastic Scalability
Optimized for speed, reliability, and scalability for all workloads

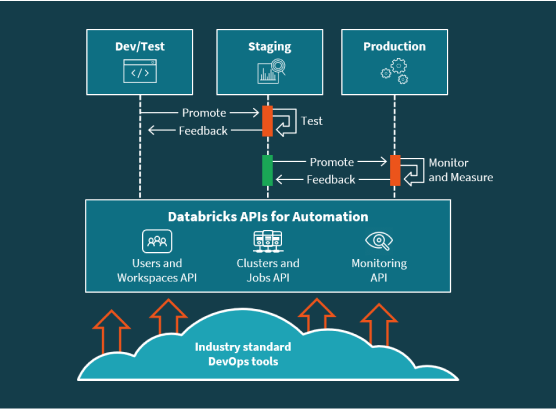
Take data applications from development to production faster using pre-configured data environments and APIs for automation. Streamline operations with autoscaling infrastructure and monitoring.
Benefits for DevOps Teams
Fully configured data environments
Enable your data teams to deliver value quickly with ready-to-use data environments configured with infrastructure, tools, libraries, users and governance policies
Productionize faster with automation
APIs for everything from version control, workspace provisioning, user management, clusters, and jobs to ML model management and tracking, allow DevOps teams to automate the data and ML lifecycle.
Streamline operations
Use on-demand autoscaling infrastructure and integrations for real-time monitoring to streamline operations in production. Improve performance and reduce downtime of your data pipelines and ML applications.
Features
Resources
Documentation
Test the platform for yourself
Use the Quick Start Guide to get the most out of your 14 day free trial